Agentic Context Engineering:面向自改进语言模型的动态上下文演化
(arxiv 2025)
斯坦福
现有局限性
上下文坍缩:该现象发生在大模型被要求在每次适应步骤中完全重写累积的上下文时。随着上下文不断增大,模型倾向于将其压缩为更短、信息量更少的摘要,导致信息出现剧烈损失。
它反映了大模型进行端到端上下文重写的固有风险,即累积的知识可能被突然擦除而非保留。
方法
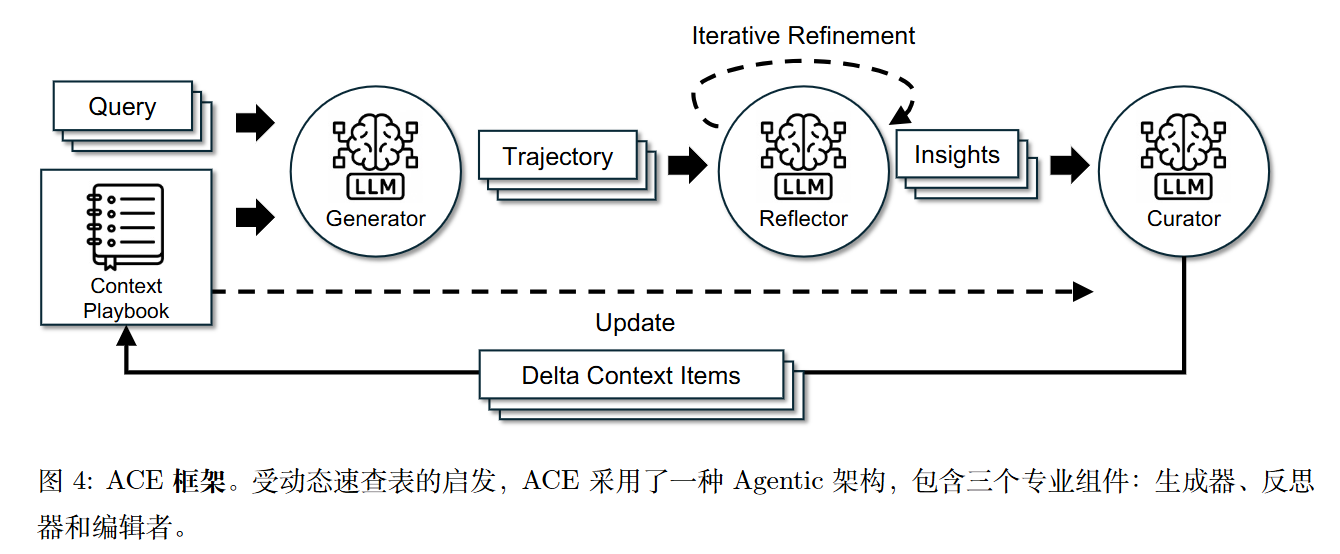
生成器负责生成推理轨迹;反思者从成功与错误中提炼具体洞见;管理者则将这些洞见整合为结构化的上下文更新。这模拟了人类的学习方式——通过实验、反思与巩固,同时避免了将所有职责集中于单一模型所带来的瓶颈。
模型分工
论文中这三个角色均由同一个模型(如 DeepSeek-V3.1)扮演。
A. 生成器 (The Generator)
- 输入: 用户的查询(Query)以及当前的“战术手册”。
- 职责: 它利用手册中的策略和代码模板来生成推理轨迹(Trajectory),尝试解决问题。
- 反馈源: 生成器的输出会产生执行结果,这可能是代码的报错信息、API 的返回结果,或者是最终答案与正确答案(如有)的比对情况。这些成为了后续学习的素材。
B. 反思者 (The Reflector)
- 输入: 生成器的推理轨迹、执行反馈(如错误日志)、以及(在离线训练时的)真实标签(Ground Truth)。
- 职责: 它不直接修改上下文,而是专注于分析。它会对比预测结果和期望结果,诊断失败的根本原因(Root Cause)。例如,它可能发现生成器在处理分页数据时使用了错误的循环结构。
- 输出: 它生成自然语言形式的“见解”(Insights)或“教训”,指明哪些策略是成功的,哪些是失败的,以及应该如何修正。
C. 策展人 (The Curator)
- 输入: 反思者生成的见解、当前的战术手册内容。
- 职责: 它将自然语言的见解转化为结构化的操作指令。它不需要重写整个手册,而是输出一个增量更新包(Delta Updates)。
- 输出格式: 通常是 JSON 格式的指令,例如“在‘API使用’章节增加一条关于分页的新规则”或“将规则 #ID-123 标记为有害”。
数据结构
数据结构:子弹项 (Bullets) 与元数据
为了支持上述的高效更新,ACE 将上下文极其精细地结构化。它不是一大段文本,而是一个由**“子弹项”(Bullets)**组成的列表。每一个子弹项包含:
- 内容 (Content): 一个独立的知识单元,例如“在调用 Spotify API 前必须先刷新 Token”。
- 唯一标识符 (ID): 系统自动分配的 ID,用于追踪和管理。
- 元数据 (Metadata): 包含计数器(Helpful/Harmful counters)。如果在后续任务中,生成器引用某条规则成功解决了问题,该规则的“Helpful”计数加一;如果导致失败,则“Harmful”计数加一。
增量更新与生长精炼
机制一:增量 Delta 更新 (Incremental Delta Updates)
ACE 严禁 LLM 直接重写整个上下文。
- 过程: 策展人(LLM)仅输出 JSON 格式的编辑操作(如
ADD,UPDATE)。 - 非 LLM 合并: 实际的合并工作由确定性的 Python 代码(非 AI)完成。代码解析 JSON,将新条目追加到列表末尾,或根据 ID 修改现有条目的元数据。
- 优势: 这种“只做加法和局部修改”的方式,确保了历史积累的知识不会因为模型一次糟糕的生成而被意外删除或篡改,同时也极大地降低了计算成本(Token 生成量大幅减少)。
机制二:生长与精炼 (Grow-and-Refine)
由于上下文窗口是有限的,手册不能无限增长,因此 ACE 设计了生命周期管理:
- 生长 (Grow): 在任务进行中,新的子弹项被不断追加,上下文长度自然增长。
- 精炼 (Refine): 当上下文达到一定长度或在特定周期结束时,系统会触发精炼过程。
- 去重: 使用语义向量(Embeddings)计算条目间的相似度,合并重复的策略。
- 剪枝: 根据元数据中的计数器,保留高价值策略,移除那些被标记为“有害”或长期未被激活的低效策略。
- 时机: 这种精炼可以是“激进的”(每步都做)也可以是“懒惰的”(仅在 Context Window 满时做),从而平衡性能与延迟。
代码
非官方开源。
Agentic Context Engineering:面向自改进语言模型的动态上下文演化
https://lijianxiong.space/2025/20251218/