Neural Message-Passing on Attention Graphs for Hallucination Detection
(ICLR 2026在投)
分数6686
motivation
目前检测 LLM 幻觉的方法通常依赖于简单的启发式规则或仅利用单一的信号(例如仅查看某些层的激活值或注意力图),缺乏对模型内部计算过程的统一和整体性建模 。
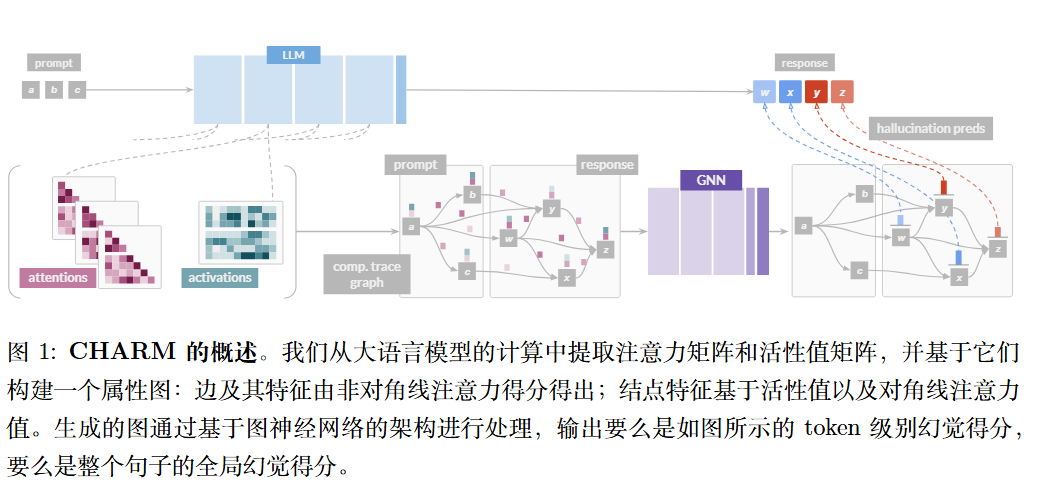
作者认为 LLM 的生成过程本质上是一个信息流动的过程。Token 之间的注意力机制天然形成了一个图结构。因此,可以将注意力(Attention)和激活值(Activations)统一到一个图结构中,通过图机器学习(Graph Learning)的方法来自动学习如何识别幻觉 。
方法
CHARM 将 LLM 处理 Prompt 和生成 Response 的过程构建为一个有向属性图 $G=(V, E, X_V, X_E)$ :
- 节点 (Nodes, $V$): 序列中的每一个 Token 就是一个节点。
- 边 (Edges, $E$): 基于注意力机制构建。如果 Token $T_i$ 在某些层/头中关注了 Token $T_j$(即注意力分数 $\alpha_{i,j} > 0$),则存在一条从 $j$ 指向 $i$ 的边(因为信息从 $j$ 流向 $i$)。
- 边特征 (Edge Features, $X_E$): 由 Token 之间的注意力分数构成。
- 节点特征 (Node Features, $X_V$): 包含两部分信息:
- 自注意力分数(Token 对自己的关注度)。
- 残差流激活值(Residual stream activations),即 Token 在特定层的向量表示。
为了提高效率,论文还引入了阈值 $\tau$ 进行图稀疏化,过滤掉权重过小的注意力边。
引入GNN
$f_{mp}$ (消息传递层): 通过多层 GNN 更新每个 Token 的节点表示。它聚合来自邻居节点(即被关注的 Token)的信息。更新公式是非线性的,并且是可学习的。
$f_{pool}$ (池化层): 根据任务粒度决定。
- 如果是Token 级检测,则不做聚合。
- 如果是句子/回答级检测,则将所有 Token 的表示聚合(如求平均)。
$f_{pred}$ (预测头): 一个多层感知机(MLP),输出幻觉的预测分数 。
统一
作者从数学上证明了 CHARM 可以统一 了目前最先进的两种基于注意力的启发式检测方法 :
Lookback Lens: 一种基于 Token 级注意力比率的检测方法。论文证明 CHARM 可以在单层消息传递中逼近 Lookback Lens 的计算逻辑 。
每个toekn $i=n_p,…,n_r+n_p-1$,为了简便忽略了头H和层数$l$符号:
$$
\begin{align}
P=\frac{1}{n_p}\sum \alpha \\
R_i=\frac{1}{i-n_p}\sum \alpha \\
\ell_i=\frac{P_i}{P_i+R_i}
\end{align}
$$
LLM-Check: 一种基于注意力矩阵对数行列式的句子级检测方法。论文证明 CHARM 同样可以逼近这种全局统计量的计算 。
$$
c=\frac{1}{H}\sum\sum log(\alpha)
$$