AVG-LLaVA: 一种具有自适应视觉粒度的高效大型多模态模型
(ACL 2025)
厦门大学、微信出品。
motivation
现有的主流 LMM(如 LLaVA-NeXT)为了处理高分辨率图像,通常将图像切割成多个局部块(patches)进行编码。这导致产生的 视觉 Token(Visual Tokens)数量激增。例如,一张 $672\times672$ 的图片可能会产生 2880 个 Token,导致推理成本随 Token 数量二次方增长,计算效率低下。
为了处理 $672\times672$ 的高分辨率图像,模型会将其切分为多个符合基础分辨率($336\times336$)的局部图像块。
- $672 / 336 = 2$,因此图片被切分为 $2\times2$ 的网格。
- 这产生了 4 张 局部图像。
为了保持图像的整体上下文信息(防止切分后丢失宏观视角),模型还会将原始的 $672\times672$ 图片缩放到基础分辨率 $336\times336$,作为 1 张 全局图像。
每一张 $336\times336$ 的图像(无论是局部的还是全局的)经过编码器后,会被编码为一个 $24\times24$ 的特征网格。
这意味着每张图像生成 $24 \times 24 = \mathbf{576}$ 个 Token。
总数求和:
- 局部图像 Token: 4 张 $\times$ 576 Token = 2304 Token
- 全局图像 Token: 1 张 $\times$ 576 Token = 576 Token
- 总计: $2304 + 576 = \mathbf{2880}$ 个 Token 。
作者认为,并非所有问题都需要极高分辨率的视觉信息。人类在回答简单问题(如“球衣是什么颜色?”)时只需要粗略一瞥(粗粒度),而在回答复杂问题(如“球衣上的数字是多少?”)时才需要仔细观察(细粒度)。
故作者设计了一种机制,让模型像人类一样,根据具体任务动态决定“看”得多细致,从而去除冗余信息。
方法
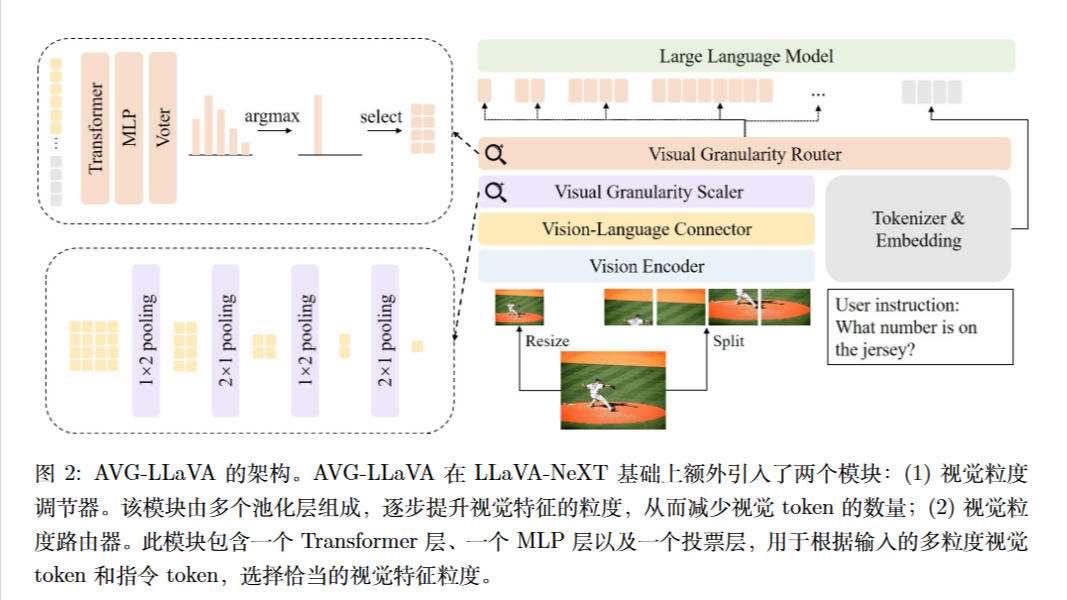
两个关键模块:
(1) 视觉粒度缩放器 (Visual Granularity Scaler)
- 功能: 该模块负责生成一系列不同粒度的视觉特征 。
- 实现: 它采用类似空间金字塔池化(Spatial Pyramid Pooling)的结构,通过堆叠 $1\times2$ 和 $2\times1$ 的平均池化层,逐步将视觉特征的分辨率减半。
- 效果: 它可以无需训练地将原始的高分辨率特征转换为多个不同层级的粗粒度特征(例如,从原始网格逐步降低到更少的 Token 数)。
(2)视觉粒度路由器 (Visual Granularity Router)
- 功能: 这是模型的核心决策模块,负责从上一模块生成的多个粒度候选中,选出最适合当前指令和图像的那一个 。
- 输入: 路由器同时接收多粒度视觉 Token 和指令 Token(Instruction Tokens)作为输入 。
- 结构: 包含一个 Transformer 层用于融合视觉和文本信息,接着是一个 MLP 层和一个投票层(Voter),最终通过 Softmax 输出各粒度的选择概率 。
- 决策: 选择概率最高的那个粒度对应的视觉 Token 输入到 LLM 中进行后续推理 。
训练
作者发现,直接使用传统的SFT很难训练好路由器,因为路由器难以从这种任务中学习到不同粒度之间的优劣差异 。为此,论文提出了一种新的两阶段训练范式。
第一阶段:多粒度视觉指令微调
- 训练基础模型(Encoder, Connector, LLM),使其具备处理和理解 N 种不同粒度视觉特征的能力。
- 此时路由器尚未参与训练。
第二阶段:基于 LMM 反馈的粒度排序 (RGLF)
- 核心思想: 冻结其他模块,仅训练路由器。利用 LMM 在不同粒度下的实际表现作为“反馈”来指导路由器。
- 排序损失 (Ranking Loss): 对于给定的图像和问题,让 LMM 使用所有不同粒度的特征分别预测答案,并计算生成正确答案的对数概率 (Log Probability)。根据这个概率对粒度进行优劣排序,强制路由器给“效果好”的粒度打高分,给“效果差”的打低分。
- 辅助损失: 同时结合交叉熵损失 ($\mathcal{L}_{ce}$),让路由器直接学习预测 LMM 认为最好的那个粒度。
实验配置
训练时使用8张 H800 GPU。
测试时使用8 张 V100 GPU,batch size=1。