Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
(ENNLP 2024)
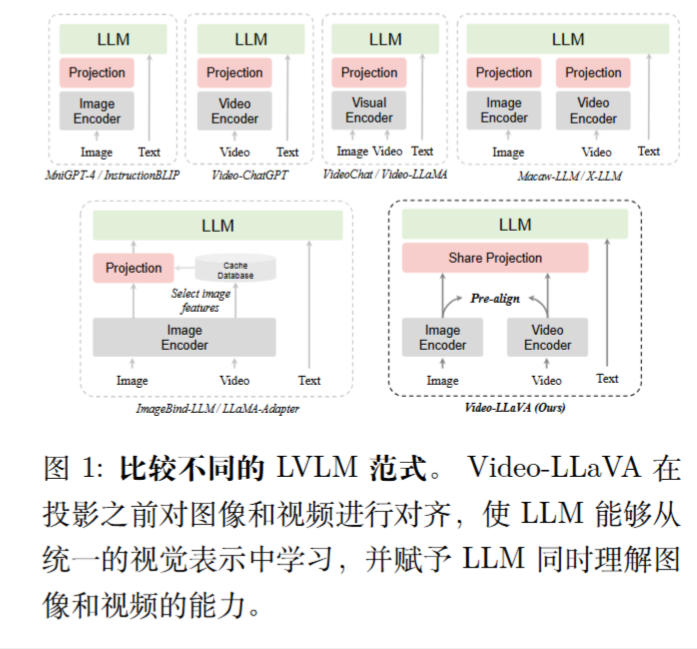
方法比较易懂,使用LanguageBind编码器。

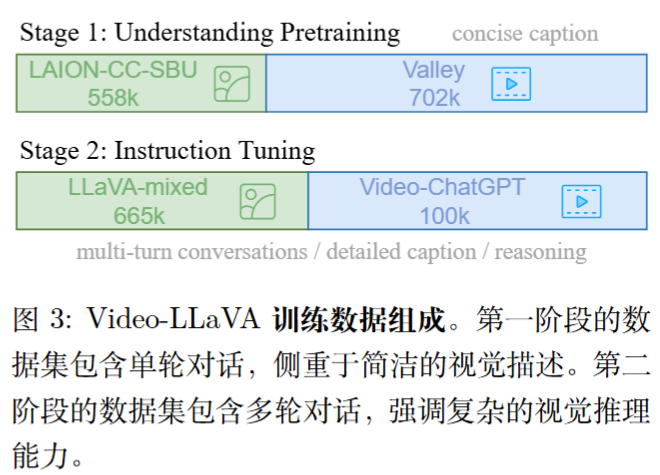
训练数据组成:
题外话:LanguageBind
这篇论文针对多模态预训练提出了一个新的框架 LanguageBind 和一个大规模数据集 VIDAL-10M。
目前的视频-语言(VL)预训练框架很难扩展到除了视觉和语言之外的更多模态($N \ge 3$)。
ImageBind 的局限性: 之前的 SOTA 方法 ImageBind 使用“图像”作为连接不同模态的桥梁(间接对齐)。这种方法要求其他模态先与图像对齐,再通过图像与语言对齐,这会导致间接对齐带来的性能损失。
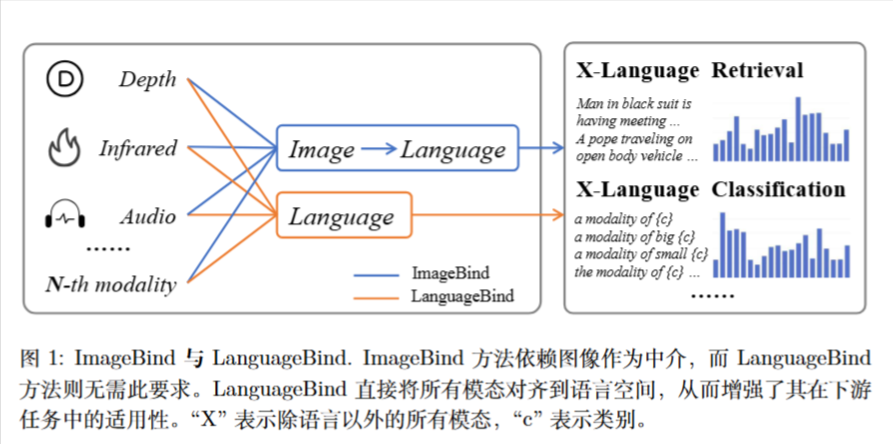
LanguageBind 的核心思想是通过对比学习(Contrastive Learning),将所有模态(视频、红外、深度、音频)直接映射到通过 VL 预训练获得的共享语言特征空间中 。
方法
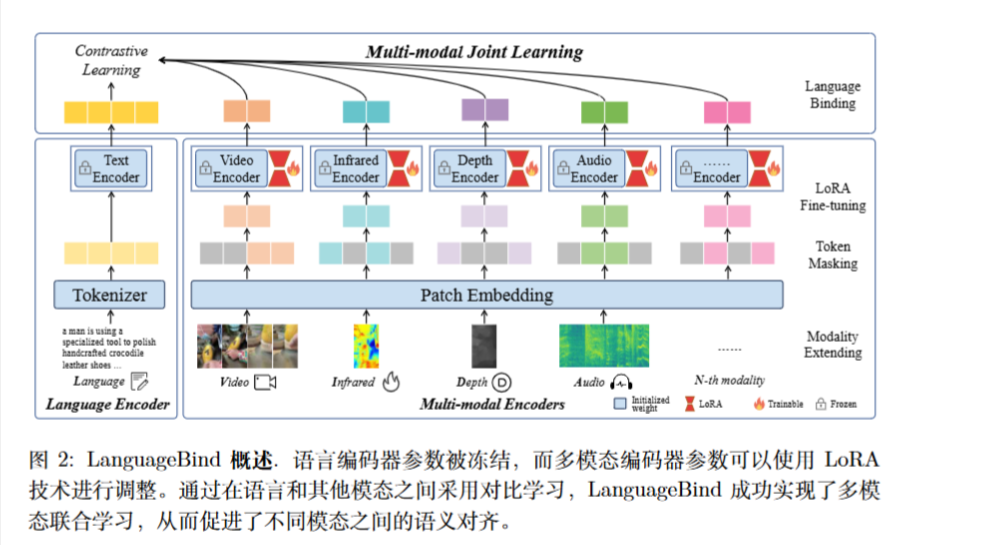
作者冻结了通过 VL 预训练获得的语言编码器(初始化自 OpenCLIP),不进行参数更新 。针对其他模态(如视频、红外、深度、音频),作者初始化 OpenCLIP 的 Vision Transformer 参数,并使用对比学习进行训练 。
为了提高训练效率并保留预训练知识,作者使用了 LoRA (Low-Rank Adaptation) 技术对多模态编码器进行微调,而不是全量微调 。
对于一些模态还有一些特殊处理:
- 深度与红外 (Depth & Infrared): 被视为 RGB 图像处理,在通道维度上复制 3 次以适应 RGB 输入格式 。
- 音频 (Audio): 转换为频谱图(Spectrograms),同样在通道维度复制 3 次 。
- 掩码策略 (Token Masking): 为了提高效率,采用了类似 MAE 的掩码策略,只处理部分 Patch
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
https://lijianxiong.space/2025/20251210/