五种LORA
受@Avi Chawla启发。
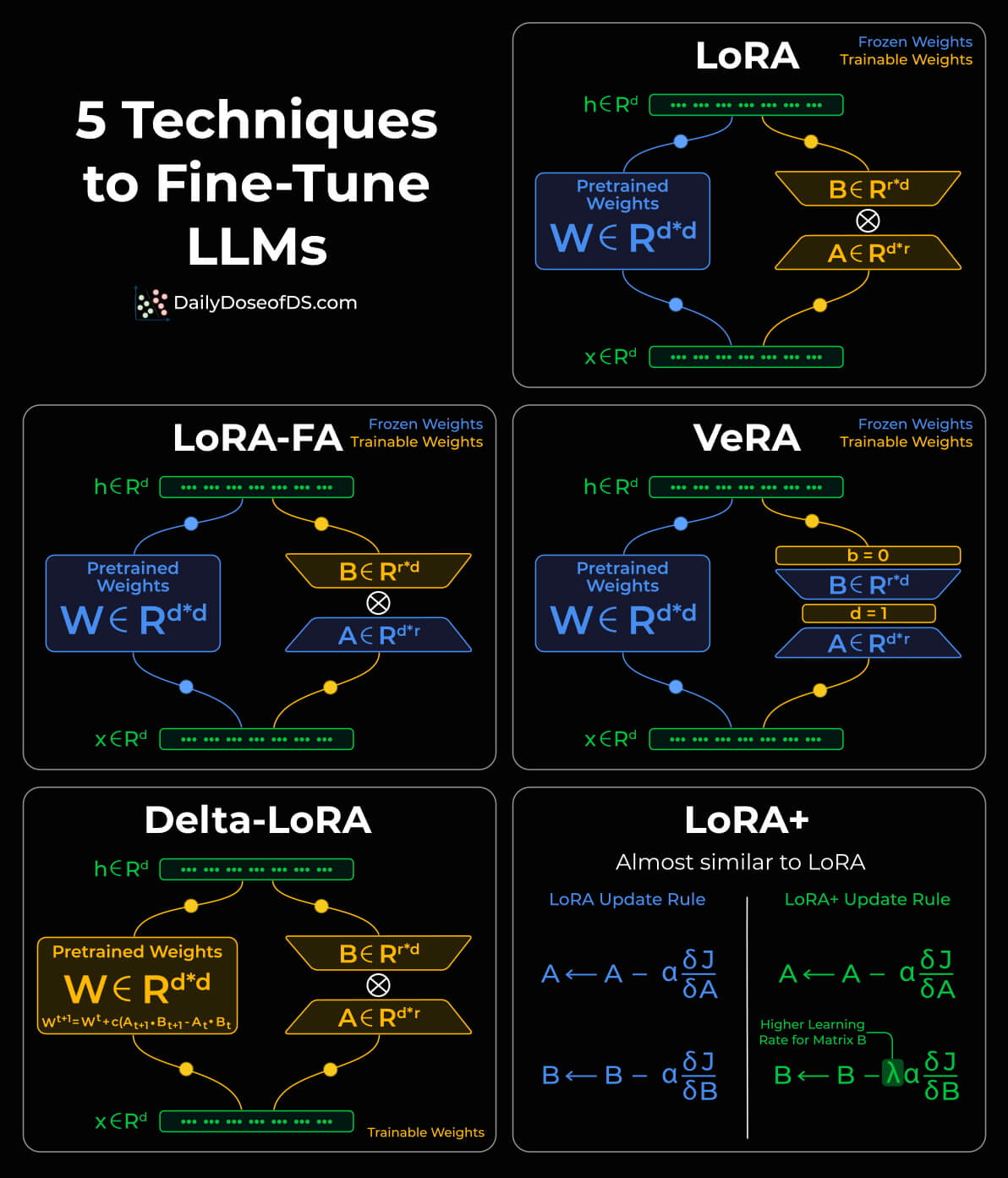
Lora
W=W+BA,其实B初始化为0,A使用高斯分布初始化。
LoRA-FA
LoRA with Frozen-A
冻结A只训练B。
VeRA
与 LoRA 直接训练矩阵 A 和 B 不同,LoRA+ 将这些矩阵初始化为共享的随机权重(即所有层中的矩阵 A 和 B 具有相同的权重值),并引入了两个新的可训练向量 d 和 b 。在训练过程,LoRA+ 仅优化向量 d 和 b 的参数值。
Delta -LoRA
ICLR 2024拒
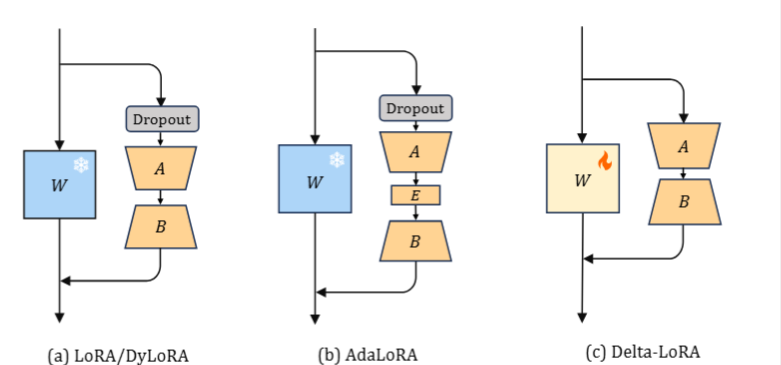
(i) 它同时更新完整的权重矩阵 (W ) 以及两个低秩适应矩阵 (A 和 B ),利用增量更新产生的 $\Delta(A(t+1)B(t+1) − A(t)B(t))$ 来优化预训练权重 (W)
(ii) 原本集成在传统 LoRA 模块中的Dropout层,在 Delta-LoRA 中被省略。这种省略源于认识到其存在违反了所需的假设$\frac{\partial \mathcal{L}}{\partial W}=\frac{\partial \mathcal{L}}{\partial AB}$。
LoRA+
为矩阵 A 和矩阵 B 引入了不同的学习率。
五种LORA
https://lijianxiong.space/2025/20251205/