IBD:通过图像有偏解码减轻大型视觉-语言模型中的幻觉
(CVPRW 2025)
也是对比解码。
方法
原始模型 ($\theta$): 标准的 LVLM,可能存在文本依赖偏差。
图像偏置模型 ($\hat{\theta}$): 一个经过修改的模型,更侧重于图像信息 。
故我们可以通过对比解码来抑制语言先验。
构建图像偏置模型 ($\hat{\theta}$)
作者没有重新训练一个大模型,而是采用了一种轻量级的方法来构建 $\hat{\theta}$——直接调整原始模型的注意力权重。
计算公式:
$$W _ {m,n}^l = \text{Softmax}\left(\frac{Q_m (K_n)^T + C _ {m,n} \cdot \epsilon + M}{\sqrt{D}}\right)$$
其中,如果 $K_n$ 是图像 token,则 $C _ {m,n}=1$,否则为 0。
基础对比解码
作者一开始也采用原始的对比解码,即:
$$\mathcal{L} _ {CD} = \text{logit} _ {\hat{\theta}}(y_i | v, t, y _ {<i}) - \text{logit} _ {\theta}(y_i | v, t, y _ {<i})$$
即两个模型输出Logits 的差值 。
但作者发现,简单的对比解码并不适用于所有情况,主要存在两个问题:
- 虚词问题: 像 “the”, “and” 这样的虚词(Function Words)主要依赖语法结构(文本先验),强制图像偏置反而会干扰预测。
- 预测相似度问题: 当两个模型的预测分布过于相似时(JSD 距离小),直接对比容易引入噪声 。
动态调整机制
最终的生成概率分布不仅依赖原始 logits,还加上了动态加权的 CD 分数:
$$y \sim \text{Softmax}(\text{logit} _ {\theta} + \alpha \cdot I \cdot \mathcal{L} _ {CD})$$
其中 $\alpha$ 是缩放因子,$I$ 是动态调节系数,$I = \text{Min}{I _ {sim}, I _ {con}}$ 。
当然也有自适应合理性约束。
调节系数 $I _ {sim}$ (相似度指标)
用于衡量两个模型预测分布的差异。使用 Jensen-Shannon 散度 (JSD) 计算:
$$I _ {sim} = \text{JSD}(p _ {\theta} || p _ {\hat{\theta}})$$
当两者预测很像时,$I _ {sim}$ 变小,减少对比解码的影响 。
调节系数 $I _ {con}$ (内容词指标)
用于衡量当前 token 是否为“实词”(Content Word)。
- 早退策略 (Early Exit): 作者利用了一个现象:模型预测虚词时,通常在中间层(如第24层)就已经确定并保持不变;而预测实词时,直到最后一层预测结果还在变化 。
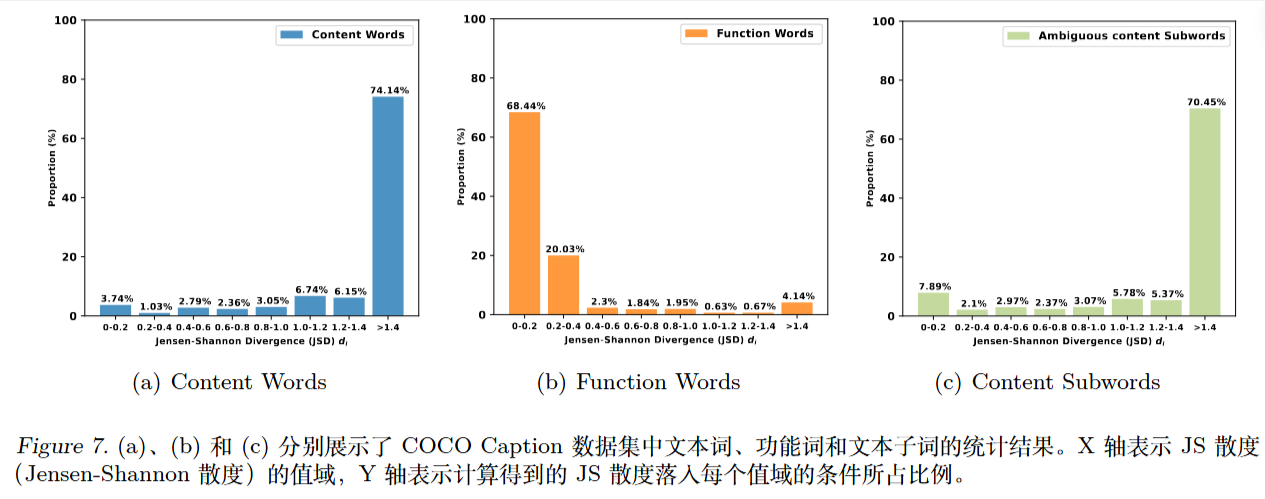
计算方法: 计算模型中间层预测 $\tilde{p} _ {\theta}$ 与最终层预测 $p _ {\theta}$ 之间的距离:
$$I _ {con} = \text{JSD}(p _ {\theta} || \tilde{p} _ {\theta})$$
如果距离大,说明是实词,适合使用对比解码;如果距离小,说明是虚词,应回退到原始解码。这种方法避免了使用外部 POS 标注工具带来的分词歧义问题。
微调
直接修改注意力权重可能会破坏模型的原有结构,引入噪声。作者通过在输入端加入少量的可学习 Prompt ($P$),并在 COCO 数据集上微调 $\hat{\theta}$,使其更好地适应这种修改后的注意力机制 。这仅增加了极少量的参数(Prompt 向量)。