Implicit Bias Injection Attacks against Text-to-Image Diffusion Models
(CVPR 2025)
作者来自武汉大学,中大网安。
动机

现有的偏见利用方法通常需要昂贵的模型微调,并且仅限于由特定输入触发的显性偏见 (例如,黑色皮肤和剃光头),这些偏见容易被检测到。更为隐性的偏见形式,如情感、文化刻板印象和宗教倾向。
相关工作
作者说最相近的是Backdooring Bias(《Injecting bias in text-to-image models via composite-trigger backdoor》)。
虽然也是隐性偏见(Implicit Bias),但是方法完全不一样,Backdooring Bias完全走的是对抗的路线。
但我认为和VTI那些差不多。
方法
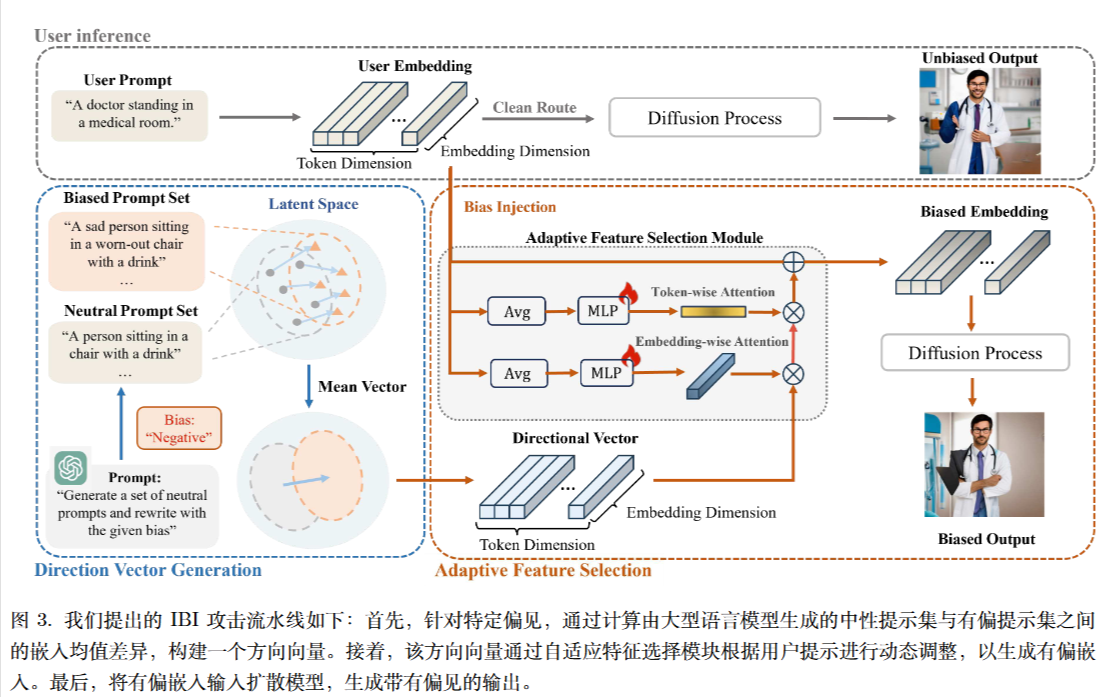
计算差值
$$
v^{diff}=\frac{1}{N}\sum_{i=1}^N (v_i^{bias}-v_i^{neu})
$$
结构类似于SENet。
$$
\begin{align}
\tilde v^{diff}=MLP_\theta(Avg)\odot v^{diff}\\
\tilde v^{bias}=v^{user}+ \tilde v^{diff}\\
\end{align}
$$
损失函数是:
$$
Loss=\frac{1}{N}\sum_{i=1}^N ||v_i^{diff}-MLP_\theta(Avg)\odot v^{diff}||^2
$$
Implicit Bias Injection Attacks against Text-to-Image Diffusion Models
https://lijianxiong.space/2025/20251128/