Be My Eyes:通过多智能体协作将大型语言模型扩展到新模态
(arxiv 2025)2511.19417
方法
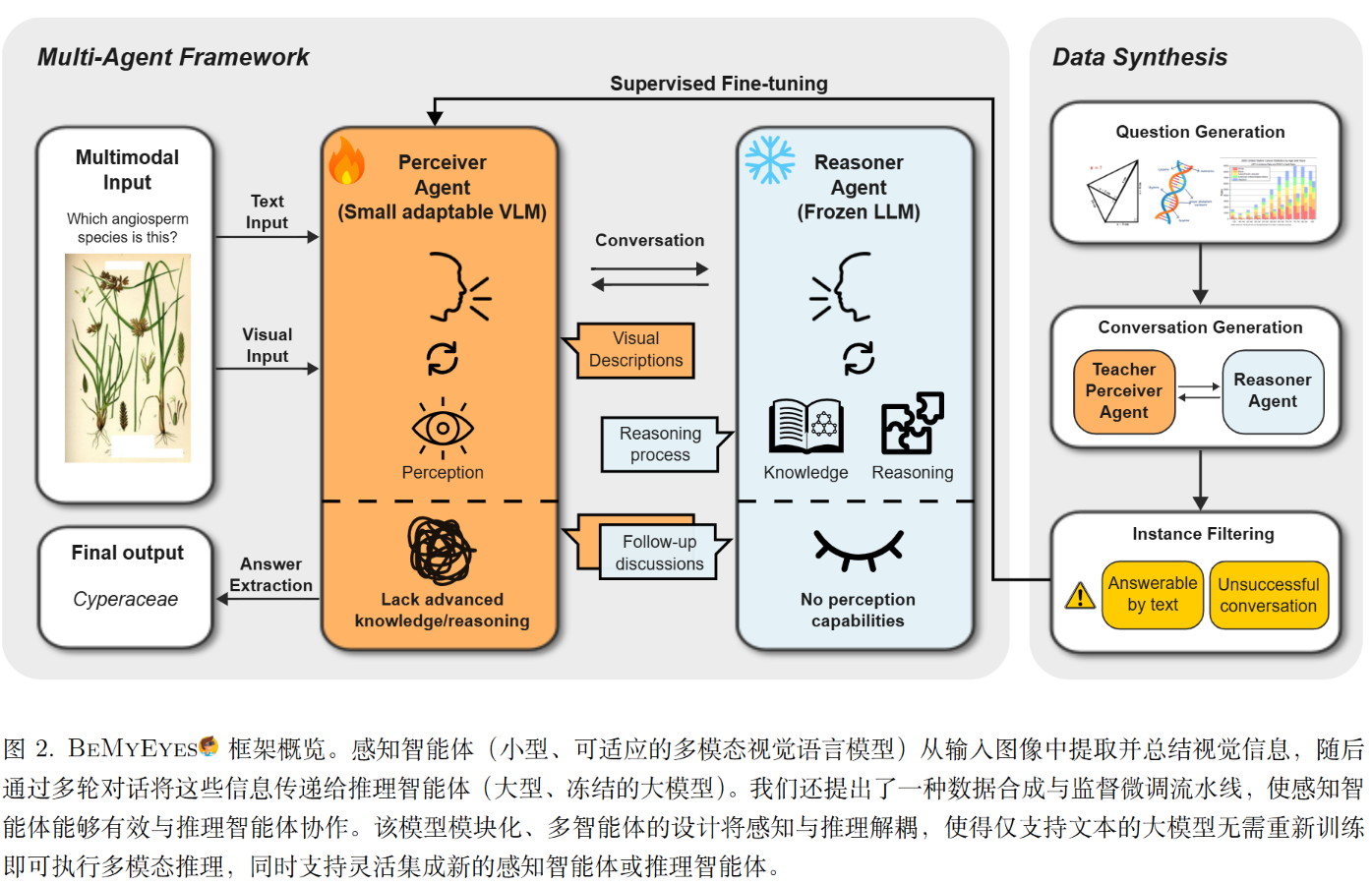
框架由两个主要智能体组成。
感知者代理 (Perceiver Agent)
- 角色: “眼睛”。负责观察图像,并根据推理者的需求描述视觉细节 。
- 模型选择: 使用较小、高效的视觉语言模型(如 Qwen2.5-VL-7B 或 InternVL3-8B)。
- 特点: 它可能缺乏深度的世界知识或复杂推理能力,但擅长视觉识别。经过微调后,它能理解自己处于“辅助”地位,需要详细、客观地描述图像 。
推理者代理 (Reasoner Agent)
- 角色: “大脑”。负责逻辑推理、调用世界知识,并主导解决问题的过程 。
- 模型选择: 使用强大的冻结LLM(如 GPT-4 或 DeepSeek-R1)。
- 特点: 它看不到图像,只能通过文本输入。它被提示(Prompted)去主动向感知者提问,索取解题所需的视觉细节,并根据反馈调整推理 。
协作流程 (Orchestration)
- 输入: 感知者接收图像和文本问题,推理者最初只知道有一个问题需要解决 。
- 对话: 双方进行多轮对话(通常上限为5轮)。推理者提出具体问题(例如:“图中的植物叶子是什么形状?”),感知者提供描述 。
- 输出: 最终由感知者基于双方的讨论总结出答案 。
训练
作者只训练感知者。
分为以下几步:
第一步:问题生成 (Question Generation) 从公开数据集(如CoSyn-400K)中选取图像,利用GPT-4o生成必须依赖视觉信息才能回答的复杂推理题 。
第二步:对话生成 (Conversation Generation) 让GPT-4o分饰两角(既是老师感知者,又是推理者),模拟高质量的协作对话。GPT-4o作为“老师感知者”能提供比小模型更精准的视觉描述和指令遵循 。
第三步:实例过滤 (Instance Filtering) 剔除那些不需要图像就能回答的问题,以及模拟对话中未能得出正确答案的失败案例 。
监督微调 (SFT): 利用生成的12,145条高质量对话数据,对感知者代理(Perceiver)进行微调。注意,推理者代理(LLM)不需要任何微调 。微调的目标是让感知者学会根据上下文提供有效信息,而不是简单地看图说话 。
实验
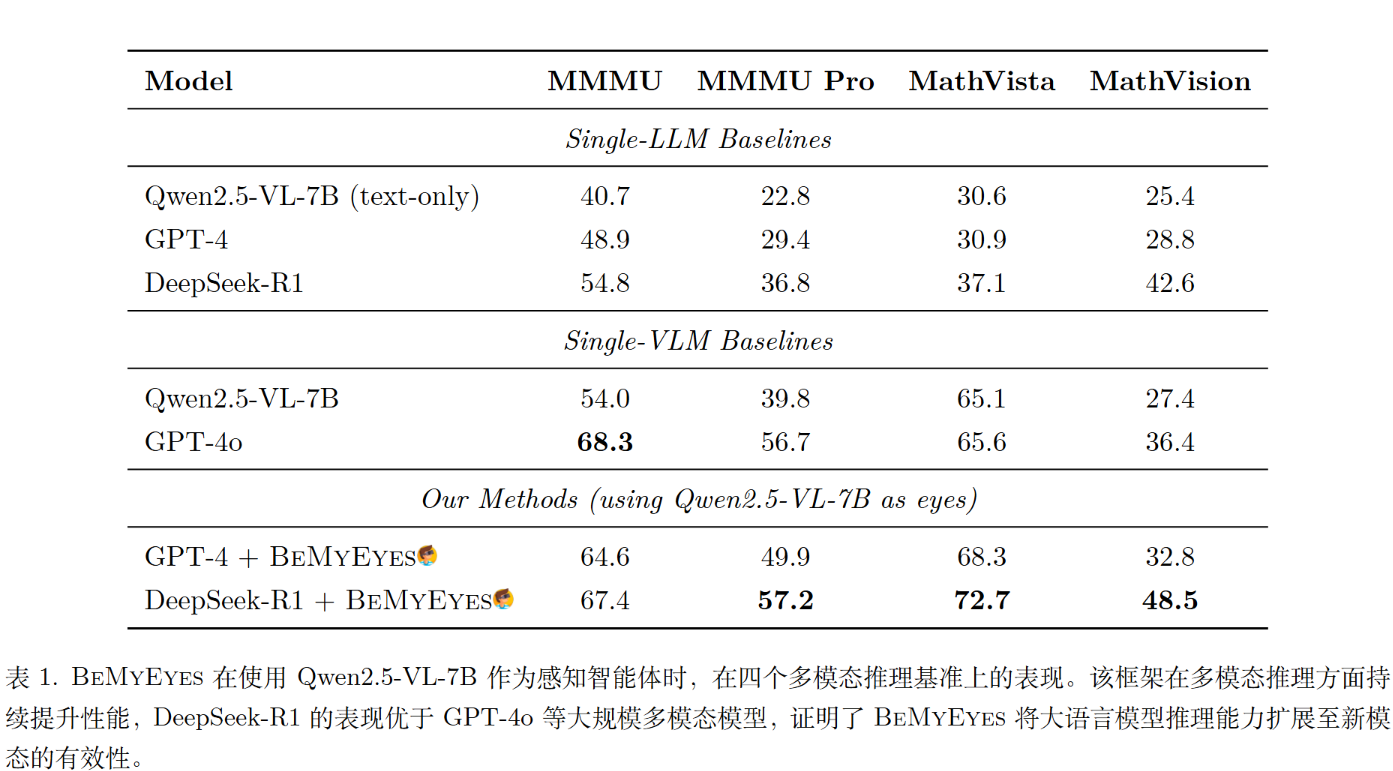
GPT-4是GPT-4o的文本模态,可以看出性能能超过原始GPT-4o。
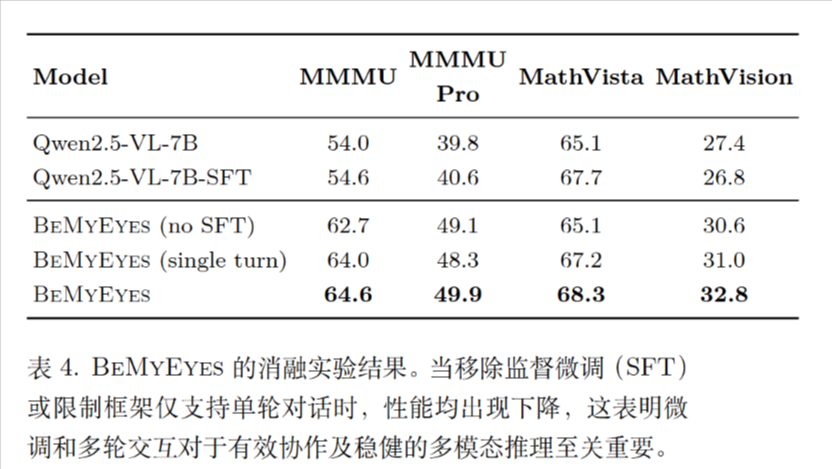
移除监督微调(SFT)或限制框架仅支持单轮对话时,性能依旧能最好。
Be My Eyes:通过多智能体协作将大型语言模型扩展到新模态
https://lijianxiong.space/2025/20251126/