把MoE整合进LLaVA
(ICLR 2025)《LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation》
(TMM 2025)《MoE-LLaVA: Mixture of Experts for Large Vision-Language Models》
LLaVA-MoD
旨在通过从大规模多模态语言模型(l-MLLM)中蒸馏知识,高效训练小规模多模态语言模型(s-MLLM)。
简单地缩小LLM可能会降低模型的表达能力,故作者选择加入MOE(相当于加宽网络,但又保持激活的参数量不变)。
如何能把大模型的复杂能力迁移到小模型上?
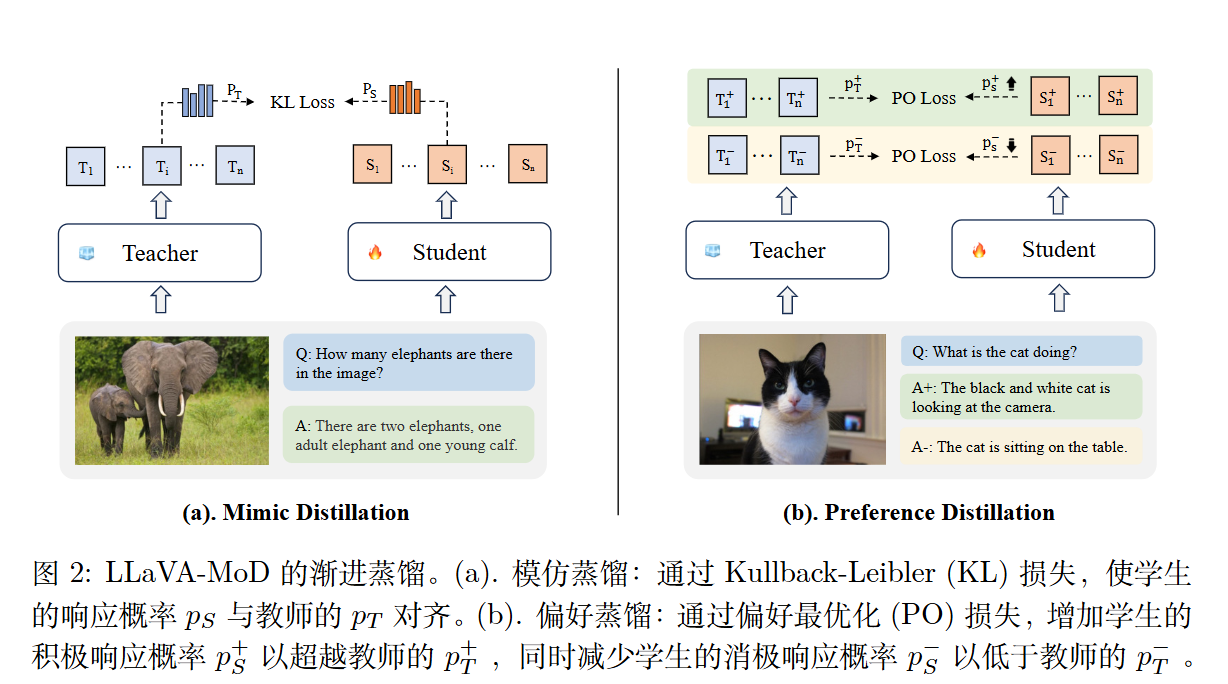
模仿蒸馏。此阶段分为两个步骤,即稠密到稠密(D2D)和稠密到稀疏(D2S)。
偏好蒸馏。l-MLLM 提供关于“好”与“坏”样本的知识,为学生模型建立基础参考。s-MLLM 利用这一知识调整其概率分布,确保好样本的概率高于来自 l-MLLM 的样本,而坏样本则被赋予较低的概率。
方法
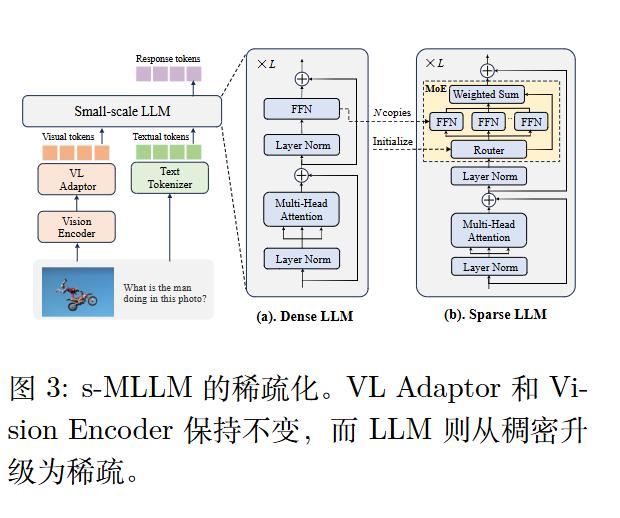
稀疏化
复制 N 个前馈网络(FFNs)作为专家模块。
逐步蒸馏
s-MLLM$\pi_S$从 l-MLLM$\pi_T$ 中模仿通用和特定知识。在偏好蒸馏阶段,$\pi_S$获得 $\pi_T$的偏好知识,以进一步优化其输出并减少幻觉。$\pi_S$和$\pi_T$均来自同一 LLM 家族。这确保了词表空间的一致性,
初始化。首先通过一个可学习的适配器将视觉编码器与 LLM 对齐,旨在获得一个良好初始化的稠密版本$\pi_s$。训练目标是最小化生成token 的交叉熵。
$$
\mathcal{L} _ {\text{Init}}(\pi_S)
= -\mathbb{E} _ {(y_k \mid y _ {<k}, x)\sim \pi_S}\left[\log \pi_S(y_k \mid y _ {<k}, x)\right]
$$
模仿蒸馏。
a)稠密到稠密。 使用KL散度。
b)稠密到稀疏。 KL散度+next token训练目标(交叉熵)。
偏好蒸馏。DPO。训练目标是优化 s-MLLM,使其与 l-MLLM 相比,对正面响应的概率分配更高,对负面响应的概率分配更低。
MoE-LLaVA
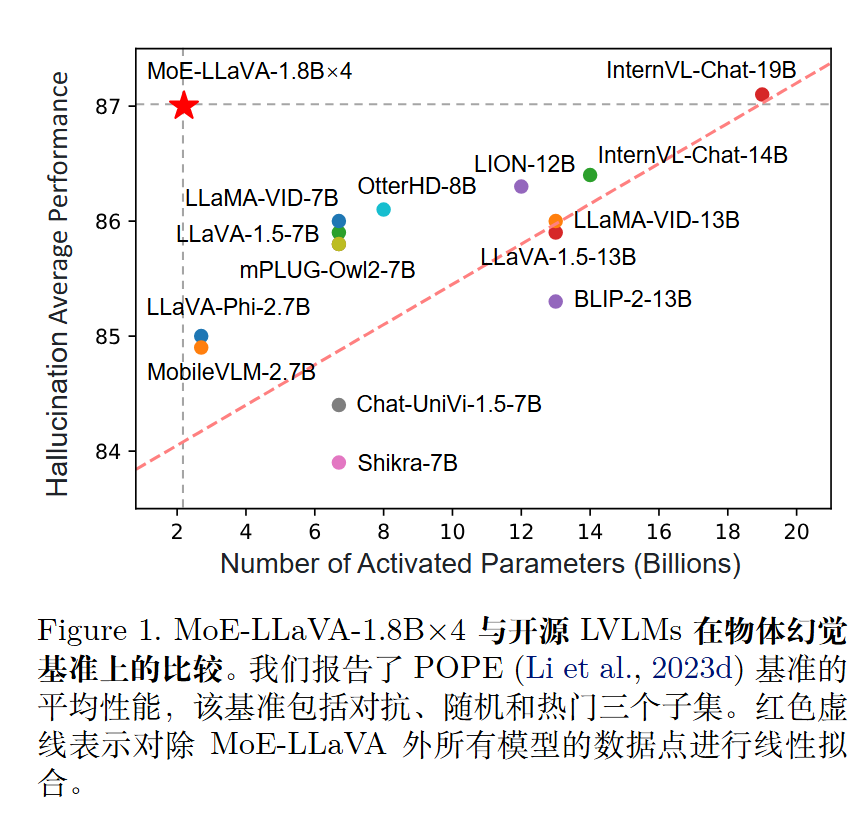
使用大约 3B个稀疏激活参数,在视觉理解基准上实现了与最先进 7B 模型相当的性能。
方法
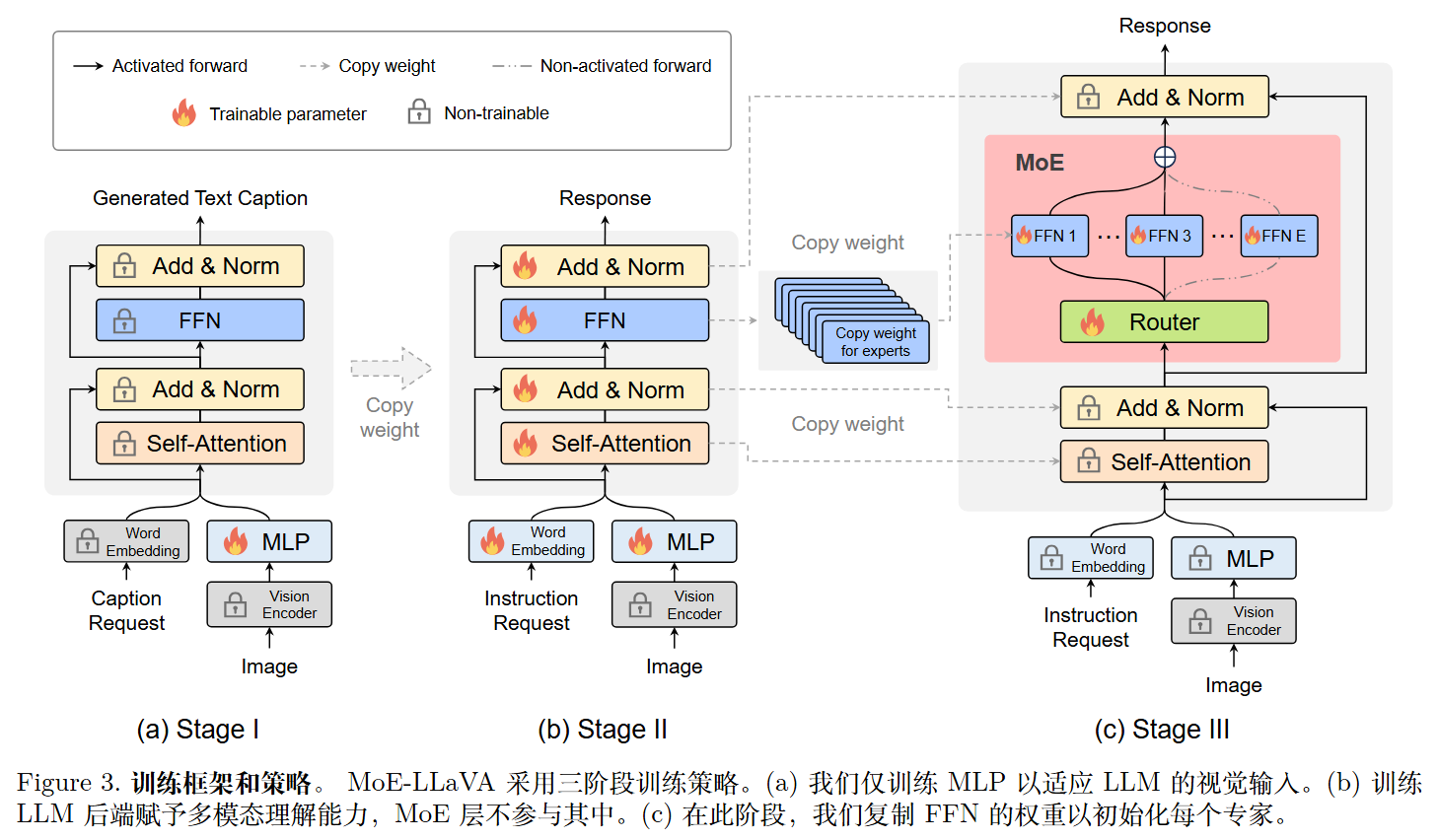
第一阶段(Stage I):适应性训练
- 操作:仅训练 MLP(投影层)。
- 目的:让 LLM 适应视觉 token,将其视为伪文本 token,使 LLM 能理解图像中的实例 。此阶段不涉及 MoE 层。
第二阶段(Stage II):多模态能力预热(关键步骤)
- 操作:训练整个 LLM 参数(此时仍为稠密模型,Dense Model)。
- 目的:通过多模态指令数据微调,赋予模型通用的多模态理解能力。论文发现,先将 LLM 转化为具有多模态能力的 LVLM 是后续稀疏化成功的关键 。
第三阶段(Stage III):稀疏化微调
- 初始化技巧:将第二阶段训练好的 FFN 权重复制多次,作为 MoE 层中各个专家的初始化权重 。
- 操作:仅训练 MoE 层(专家和路由)。
- 目的:模型从初始化的通用 LVLM 逐渐过渡到稀疏的专家混合模型 。
实验
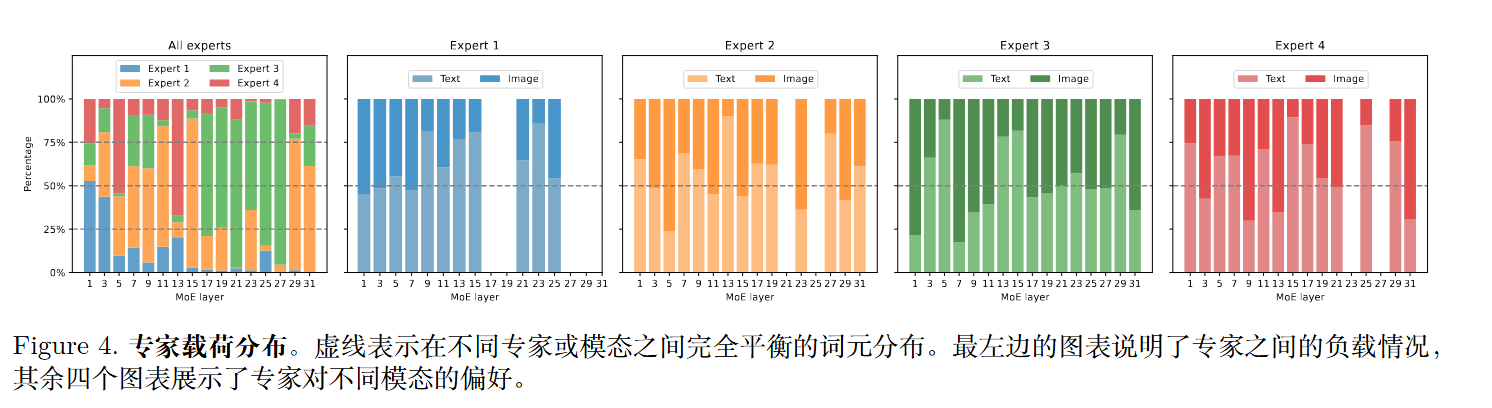
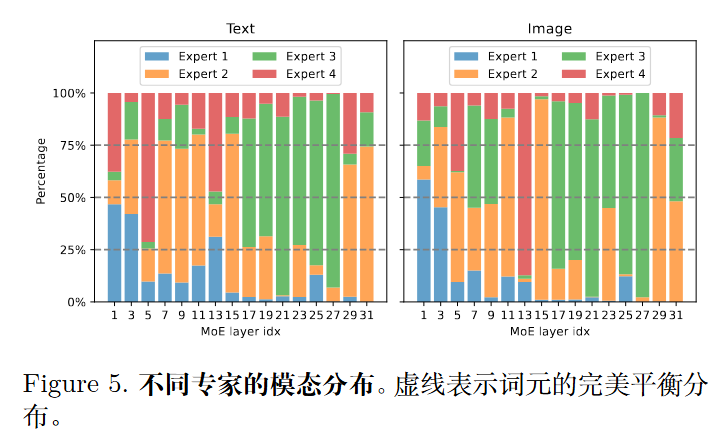
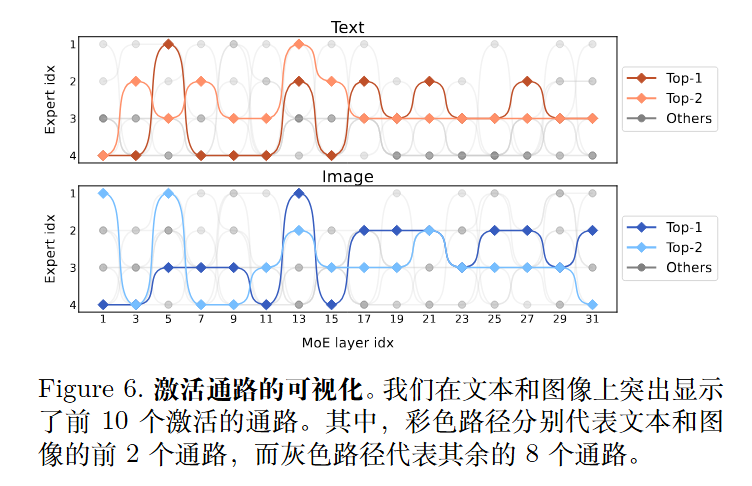
文本和图像的路由分布高度相似。MoE-LLaVA 处理的文本和图像的比例是相似的。MoE-LLaVA 中的每个专家都能同时处理文本词元和图像词元,这表明 MoE-LLaVA 在任何模态上都没有明显的偏好。这证明了其在多模态学习中的强大交互能力。