ARC Is a Vision Problem
何恺明出品。arxiv 2025。
ARC任务
ARC-AGI(Abstraction and Reasoning Corpus,抽象与推理语料库) 是一个专门用于衡量 AI 系统泛化能力和解决新颖任务能力的基准测试,它与传统的基准测试不同,更注重考察 AI 的抽象推理能力,而不是单纯的记忆或模式匹配能力。
ARC-AGI 任务不需要专门的世界知识(例如历史事实)或语言来解决。唯一需要的先验知识是一些核心知识——诸如物体性、基本拓扑、初等整数算术等概念。而这些人类的核心知识已由 Spelke 等人研究并指出这些知识 Prior 在儿童早期(通常在四岁之前)就已获得。
ARC-AGI 任务的另一个重要特征是它们对 AI 系统来说很难,但对人类来说却很容易。
一个示例:

motivation
抽象推理语料库 (Abstraction and Reasoning Corpus, ARC) 挑战虽然常被视为一个语言或符号推理问题,但其本质是视觉的,因此应该从计算机视觉的角度来解决 。
方法
将 ARC 任务(从输入 $x$ 到输出 $y$ 的映射)视为一个逐像素分类 (per-pixel classification) 问题,类似于语义分割。
模型目标: 学习一个神经网络 $f_{\theta}$,它以输入图像 $x_i$ 为输入,并以一个表示任务 $T$ 的可学习任务令牌为条件,输出一个网格,其中每个位置代表一个分类分布。
损失函数: 使用逐像素交叉熵损失 (per-pixel cross-entropy loss) 进行优化。
为了引入 2D 空间局部性、平移不变性和尺度不变性等视觉先验,模型采用了以下设计:
- 画布:
画布具有预定义且足够大的大小。原始输入经过变换后被放置在该画布上。这种设定自然地容纳了平移和尺度增强,这些是视觉领域中引入平移和尺度不变性的常见策略,将画布的背景设置为额外的背景颜色,即第 (C+1) 种颜色。
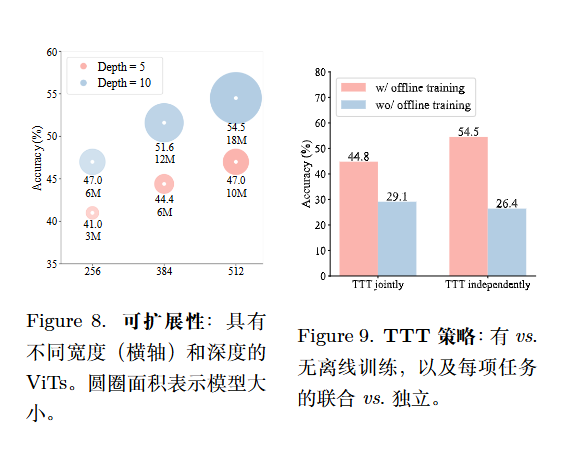
当应用 ViT 模型时,如果将每个原始像素天真地视为一个 token,那么只会存在 C个不同的 token。相比之下,画布支持更大数量的局部、块级配置。例如,当块大小为 2×2时,单个块可以包含多种颜色(如下面的VIT结构图所示),并且在理论上具有指数级大的基数,O(C2×2)。这种公式对于提升泛化性能至关重要。
- 翻译与尺度不变性(Translation and scale invariance)
缩放增强:给定一个原始输入,随机将其按整数缩放比例 s 重新调整大小,将每个原始像素复制为 s×s 个。类似于自然图像中的最近邻插值。
当然,因为ARC 中的“颜色”并不对应真实世界中的颜色,因此进行其他插值(如双线性插值)是没有意义的。
翻译增强: 给定缩放后的网格,将其随机放置在固定大小的画布上。我们确保所有像素都可见。
- VIT。默认情况下使用VIT。
从概念上讲,块化可以被视为一种特殊的卷积形式。与卷积一样,它在视觉任务中引入了几个关键的归纳偏置:最显著的是局部性(即对邻近像素进行分组)和平移不变性(即在不同位置间共享权重)。
- 二维位置嵌入。
在这里作者使用可分离的2D位置嵌入,对于具有对于具有 D 通道的位置嵌入,使用前半部分通道来嵌入水平坐标,后半部分通道用于嵌入垂直坐标。这既可用于加性位置嵌入以编码绝对位置,也可用于相对位置的编码。
另外,作者也使用了一些更经典的基于视觉的架构,比如CNN。具体而言,作者使用的是U-Net。
训练
作者采用两阶段训练范式来学习神经网络的参数。
离线训练。在整个训练集上训练。所有任务共享相同的模型参数,但每个任务有自己独立的可学习的任务条件令牌 (task-conditional token) 。
测试时训练。对于每一个新的、未见过的测试任务 $T \in \mathcal{T}_{test}$,模型权重从离线训练结果初始化。
使用该任务的演示样本 $\mathcal{D}_{demo}^T$(只有 2-4 对)对模型进行微调 (fine-tuned) 。
通过对演示样本进行翻转、旋转和颜色置换等增强,将单个测试任务扩充为多个辅助任务进行 TTT。
推理
单视图推理。由于画布上的多个像素可能预测原始网格中的同一个输出位置(因为有缩放),算法通过平均池化对这一位置的所有预测(来自 Softmax 输出)进行聚合。
多视图推理。 采用与传统视觉方法类似的多视图推理策略 。通过采样不同增强(尺度和平移)的 510 个随机“视图”,并使用多数投票 (majority voting) 来整合预测结果,以提高准确性 。
Pass@2 准确率。为了支持 ARC 默认的 Pass@2 评估指标,模型保留多数投票得出的前 2 个最普遍的输出作为最终预测 。
实验