借助主动检索增强缓解大型视觉语言模型的幻觉问题
TOMM,CCF-B类,三区
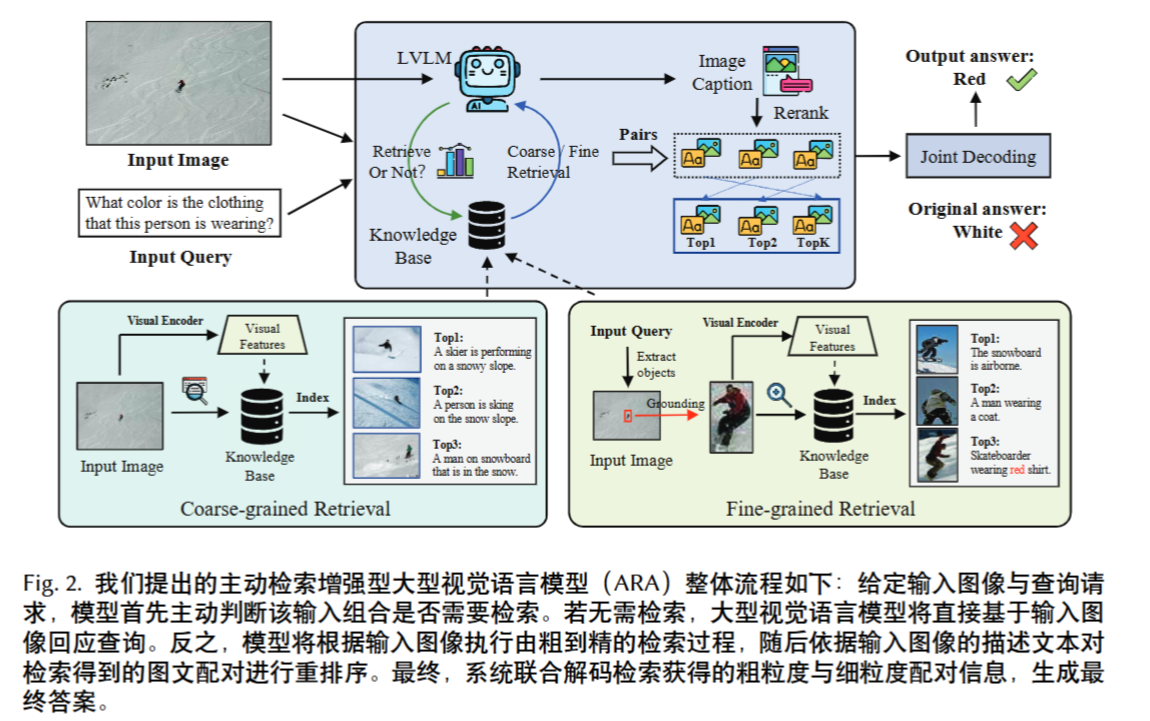
方法
主动触发检索
置信度感知 (Confidence-aware):基于输出token的置信度 。如果置信度低于阈值则触发。实验证明这种方法不稳定 。
图像感知 (Image-aware):比较模型对“原始图像”和“加噪图像”的回答概率差异 。
问题感知 (Question-aware):(本文最终采用的方法)
“问题感知”详解:
此方法的核心是评估模型在多大程度上依赖“图像”来回答,而不是仅凭“问题”中的语言偏见来猜测 。
它使用互信息公式来计算一个“难度度量” $M_{ij}$ :
$$M_{ij} = \log \frac{P(a_{ij}|V_i, Q_i)}{P(a_{ij}|Q_i)}$$
- $P(a_{ij}|V_i, Q_i)$ 是模型看到**图像(V)和问题(Q)**后,给出答案(a)的概率。
- $P(a_{ij}|Q_i)$ 是模型只看到问题(Q)(不看图像)时,给出答案(a)的概率。
如果 $M_{ij}$ 很高,说明图像(V)对答案贡献很大。如果 $M_{ij}$ 很低(甚至是负数),说明模型主要依赖问题(Q)在瞎猜(即语言偏见)。
因此,当 $M_{ij} < \theta$ (某个阈值)时,ARA 触发检索 。
由粗到精的层次化检索
粗粒度检索 (Coarse-grained):
使用 CLIP 提取整个输入图像的视觉嵌入。
在知识库(如 COCO 数据集)中检索最相似的 Top-K 图像及其配对的标题。
细粒度检索 (Fine-grained):
首先,使用 LLM (LLaMA2-7B) 从**输入的问题(Query)**中提取关键实体(如 “clothing”)。
然后,使用 Grounding Dino(一个检测模型)在输入图像中定位这些实体,并将其裁切 (crop) 出来。
使用 CLIP 提取这些裁切区域的嵌入。
在细粒度知识库(如 VisualGenome)中检索最相似的 Top-K 区域图像及其配对的标题。
检索结果重排序 (Reranking Retrieving Results)
初步检索(基于CLIP视觉相似性)可能会召回“视觉相似但语义不同”的噪声结果。
ARA 的解决方案是:
让 LVLM(如 LLaVA 1.5)为输入图像(或裁切区域)生成一个新的、详细的描述(Caption) 。
计算这个“新描述”与所有“检索到的描述”之间的文本语义相似度(使用 CLIP 文本编码器)。
根据这个语义相似度对检索结果进行重排序。
联合解码 (Joint Decoding)
最后一步是如何融合“粗粒度”和“细粒度”的检索结果来生成最终答案。作者对比了两种策略:
(1)实例级融合 (Instance-level Fusion / Coarse+Fine):
- 将粗粒度和细粒度的所有检索结果(图像+文本)全部塞进一个超长的 Prompt 中,让模型一次性推理。
- 实验证明,这种方法效果很差,甚至不如单独的粗粒度检索,因为它混淆了不同粒度的信息 。
(2)概率级融合 (Probability-level Fusion / Coarse & Fine):(本文最终采用的方法)
分别进行两次推理:
推理1:(输入图像 + 问题 + 粗粒度结果) $\rightarrow$ 得到 $p^{coarse}$ 概率分布。
推理2:(输入图像 + 问题 + 细粒度结果) $\rightarrow$ 得到 $p^{fine}$ 概率分布 。
最后,将两个概率分布进行线性加权融合 :
$$D^{\text{coarse&fine}} = \alpha p^{coarse} + (1-\alpha) p^{fine}$$
超参数 $\alpha$ 用来控制两者的重要性(例如,在对象检测任务中 $\alpha=0.8$,在属性任务中 $\alpha=0.4$)。这种方式能更好地处理不同粒度的信息。