缓解多模态幻觉通过注意力引导的集成解码
(ICLR 2025)《Do You Keep an Eye on What I Ask? Mitigating Multimodal Hallucination via Attention-Guided Ensemble Decoding》
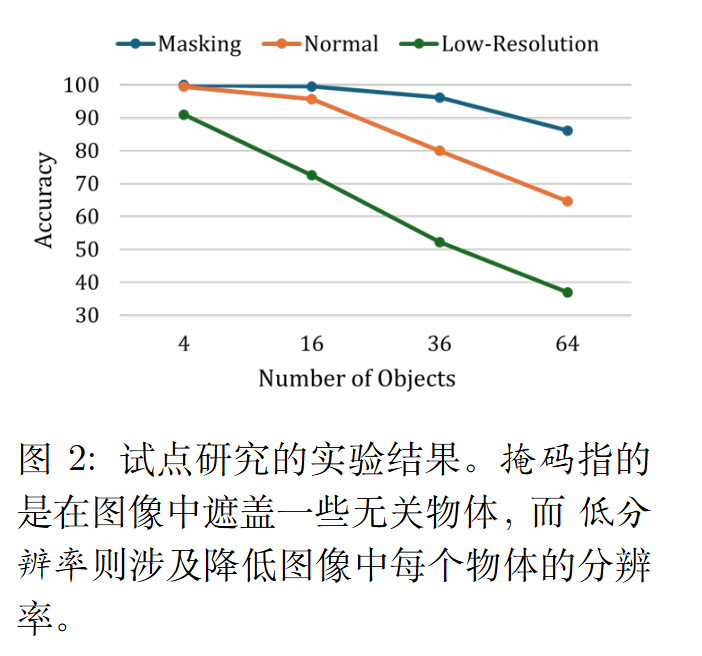
motivation
两个可能对模型性能产生负面影响的关键因子:
(1) 图像中存在无关物体
(2) 图像中物体的分辨率较低。
作者实验了一下:
(1) 对不必要的区域进行掩码处理,以减少无关物体的影响
(2) 降低图像中物体的分辨率,以评估它们对模型性能的影响。
方法
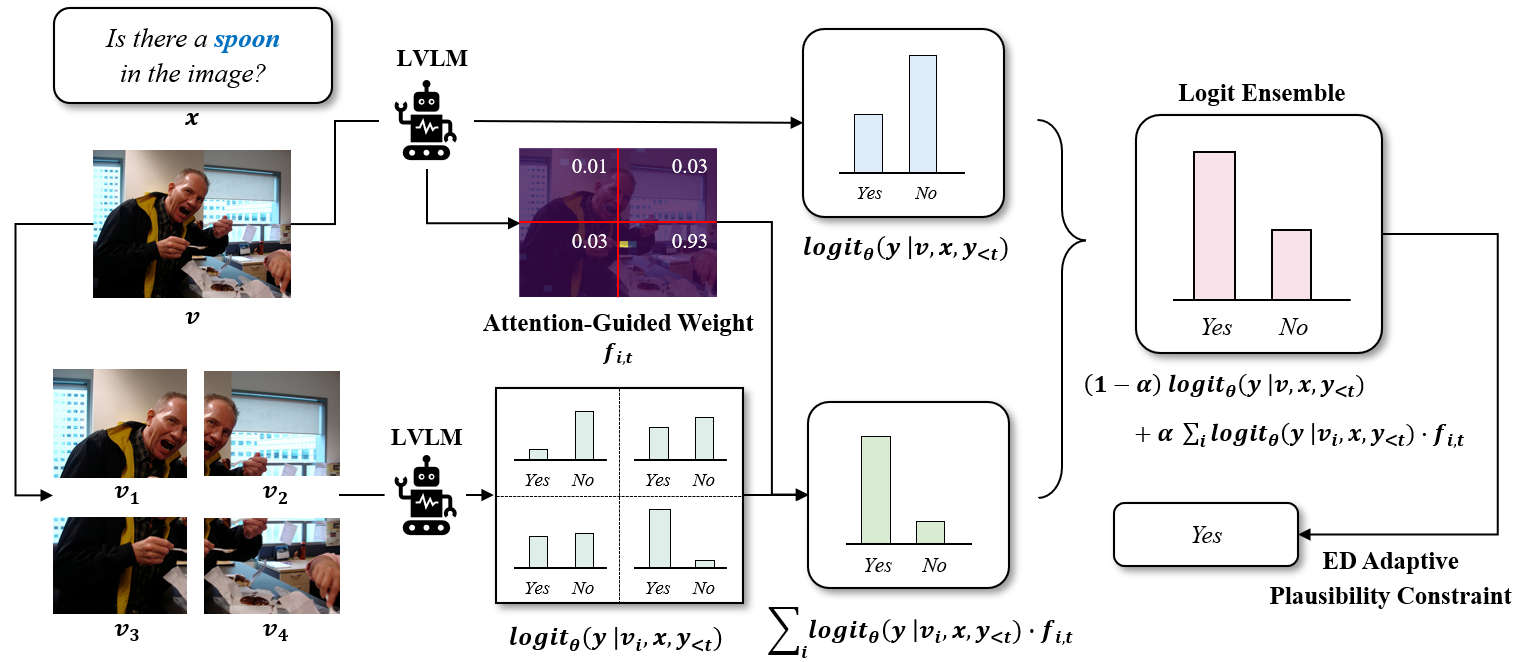
在多头注意力机制中,识别出平均注意力得分最高的 H 个头,并将其平均以获得单一的注意力矩阵。最终得到的注意力矩阵$\hat A_t$ 被重塑为大小为 d × d 的矩阵:
$$
\hat A_t=\frac{1}{H}\sum _ {j=1}^H sorted\left(\frac{1}{K}\sum _ {i=1}^K sorted(A_t)[i]\right)[j]\in R^{d\times d}
$$
再对每个子图中的注意力求和,再接个softmax:
$$
\begin{align}
s _ {k,t}&=\sum \hat A _ {t,i,j} \text{ for k }=1,2,…N
\\
f _ {k,t}&=\frac{exp(s _ {k,t}/\tau)}{\sum _ {j=1}^N exp(s _ {j,t}/\tau)}
\end{align}
$$
最终对比解码为
$$
p _ {ED}(y_t | V, x, y _ {<t}) = \operatorname{softmax} \left[ (1 - \alpha) \operatorname{logit} _ {\theta}(y_t | v, x, y _ {<t}) + \alpha \sum _ {k=1}^{N} \operatorname{logit} _ {\theta}(y_t | v_k, x, y _ {<t}) \cdot f _ {k,t} \right]
$$
自适应合理性约束
同样的,他也有对比解码中常用的自适应合理性约束。
$$
\mathcal{V} _ {\text{head}}(y _ {<t}) = \left\{ y_t \in \mathcal{V} : \sum _ {k=1}^{N} p _ {\theta}(y_t | v_k, x, y _ {<t}) \ge \beta \max _ {w} \left( \sum _ {k=1}^{N} p _ {\theta}(w | v_k, x, y _ {<t}) \cdot f _ {k,t} \right) \right\}
$$
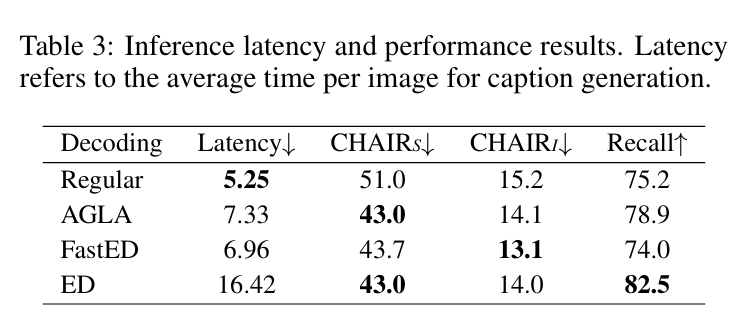
FastED
诸如VCD的对比解码的缺点是需要两次前向传播。
而这个方法更加重了这一缺点,它切N块,需要N+1次。
为了解决这个问题,作者进一步提出了FastED。即只集成原始图像和当前步骤中具有最高注意力权重的那个子图像。
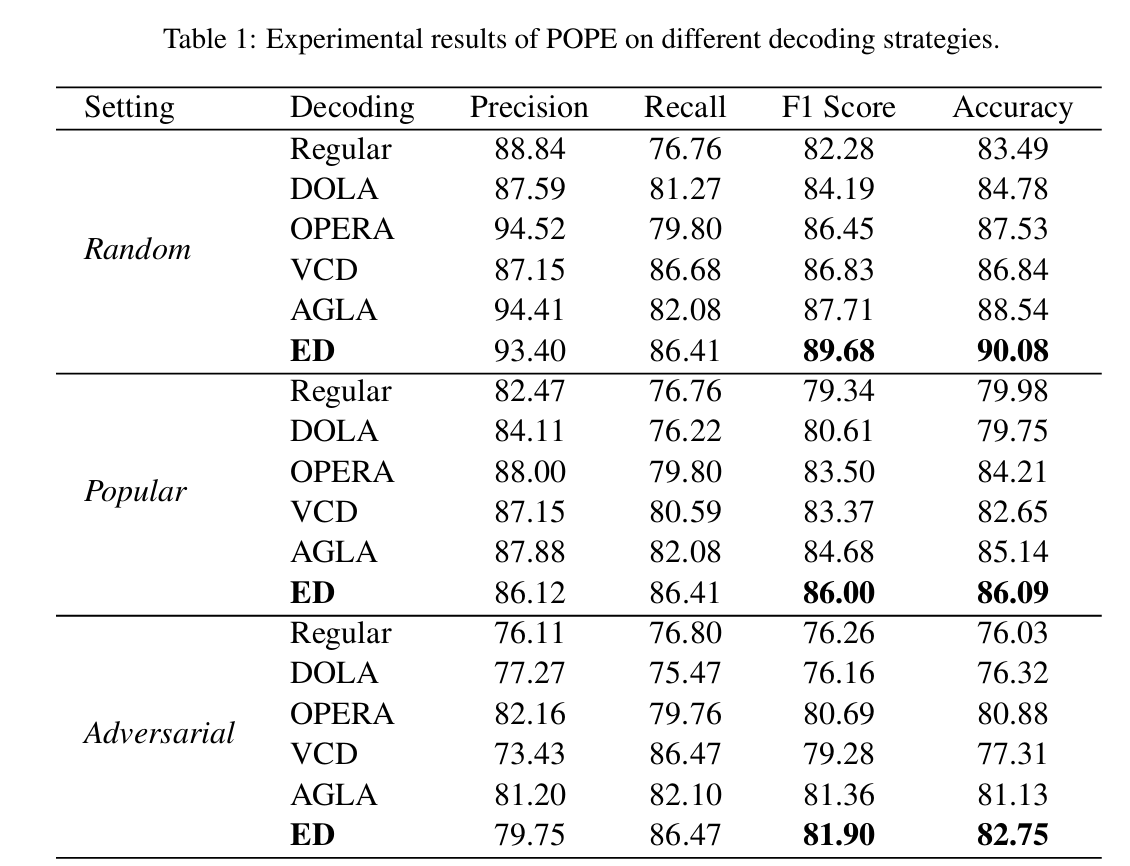
实验