大模型天生具有某些能力
(ICLR 2025)两篇串起来阅读。
《MLLMs Know Where to Look: Training-Free Perception of Small Visual Details with Multimodal LLMs》
&《MLLM CAN SEE? DYNAMIC CORRECTION DECODING FOR HALLUCINATION MITIGATION》
涉及小细节的时候模型知道看哪里
motivation
通过更聚焦的视觉裁剪逐渐靠近路牌时,模型对正确答案的概率逐渐增加,这表明模型逐渐感知到了越来越多的与路牌相关的信息。
比如
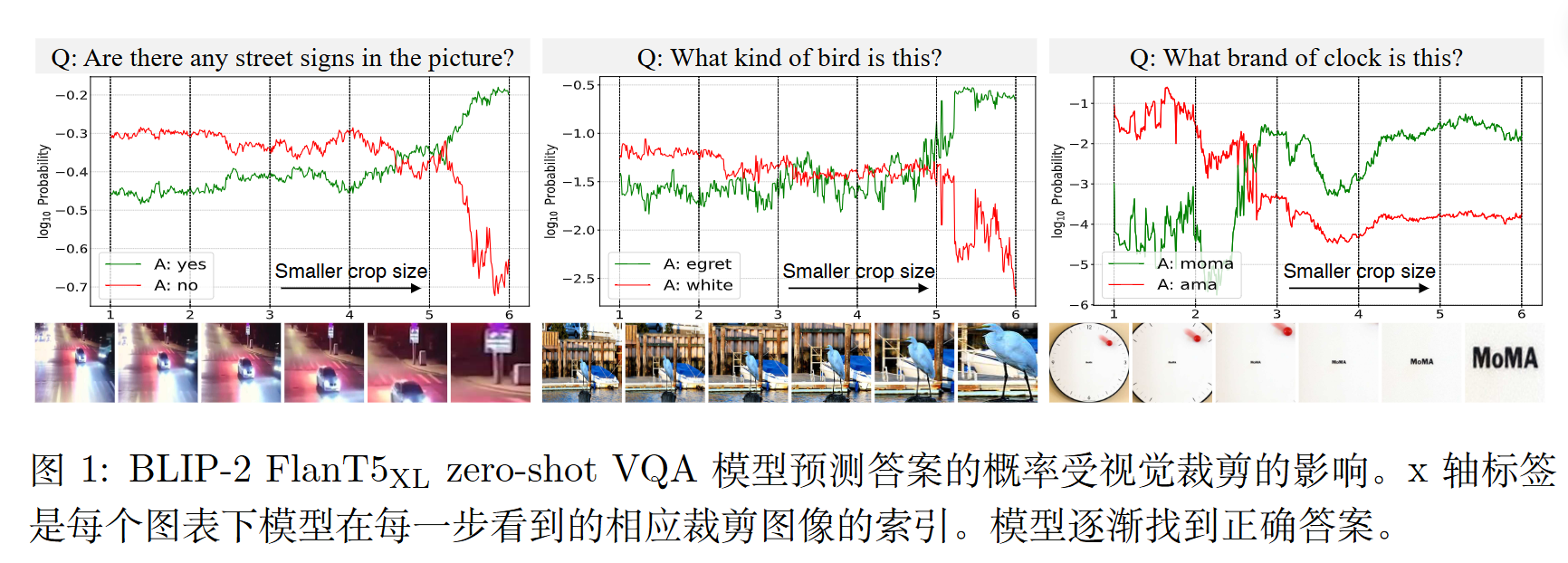
模型答错,有两种可能:1) 没找到(定位局限);2) 找到了但看不清(感知局限) 。
作者者提取了 MLLM 内部 Transformer 层的注意力图,以分析模型在回答问题时“正在看”图像的哪个部分 。
为了使分析更准确,他们提出了一种“相对注意力 (Relative Attention)”。即用“特定问题”(如“时钟是什么牌子?”)的注意力图,除以“通用问题”(如“描述这张图片”)的注意力图 。这能有效筛除模型对背景或全局信息的“默认关注”,只保留与当前问题强相关的注意力 。

故MLLM 的主要瓶颈不是定位局限(不知道在哪看),而是感知局限(看到了但看不清) 。
方法
直接训练更高分辨率的模型计算成本极高。故作者提出了 ViCrop (Visual Cropping),一种无需训练、可扩展的自动视觉裁剪方法 。
作者提出了三种裁剪方法。
(1)相对注意力裁剪 (rel-att):
- 直接使用“相对注意力”图谱 。
- 注意力最集中的区域即为需要裁剪的区域 。
- 缺点:需要模型进行两次前向传播(一次问特定问题,一次问通用问题) 。
(2)梯度加权注意力裁剪 (grad-att):
这是一种更高效的替代方案,旨在只进行一次前向传播 。
它利用模型决策(即输出答案的 logit)对注意力得分的梯度 (gradient) 来为注意力图加权 。
梯度的大小反映了该处注意力对最终答案的“重要性”或“敏感度”,从而强调了与回答问题最相关的注意力区域 。
(3)输入梯度裁剪 (pure-grad):
- 这是一种更通用的方法,不依赖于模型的注意力结构(因此也适用于非 Transformer 架构) 。
- 它直接计算模型决策相对于输入图像像素的梯度 ($||\nabla _ {x}v(x,q)|| _ {2}$)。
- 梯度值高的区域表明这些像素对模型的决策影响最大。该方法还结合了高通滤波器来强调边缘,忽略天空等平坦区域。
确定了其中一种生成的“重要性图谱”后,论文使用滑动窗口技术来确定最佳的裁剪边界框。
模型在前面的层中能识别视觉对象
motivation
作者通过实证分析发现,尽管 MLLMs 在最终输出中错误地生成对象,但它们实际上一定程度上能够在前面的层中识别视觉对象。
作者推测,这可能是由于语言模型的强知识先验抑制了视觉信息,从而导致幻觉。
基于此,作者提出了一种新颖的动态校正解码方法(DeCo),该方法自适应地选择适当的前面层,并将知识按比例整合到最终层以调整输出 logit。
发现
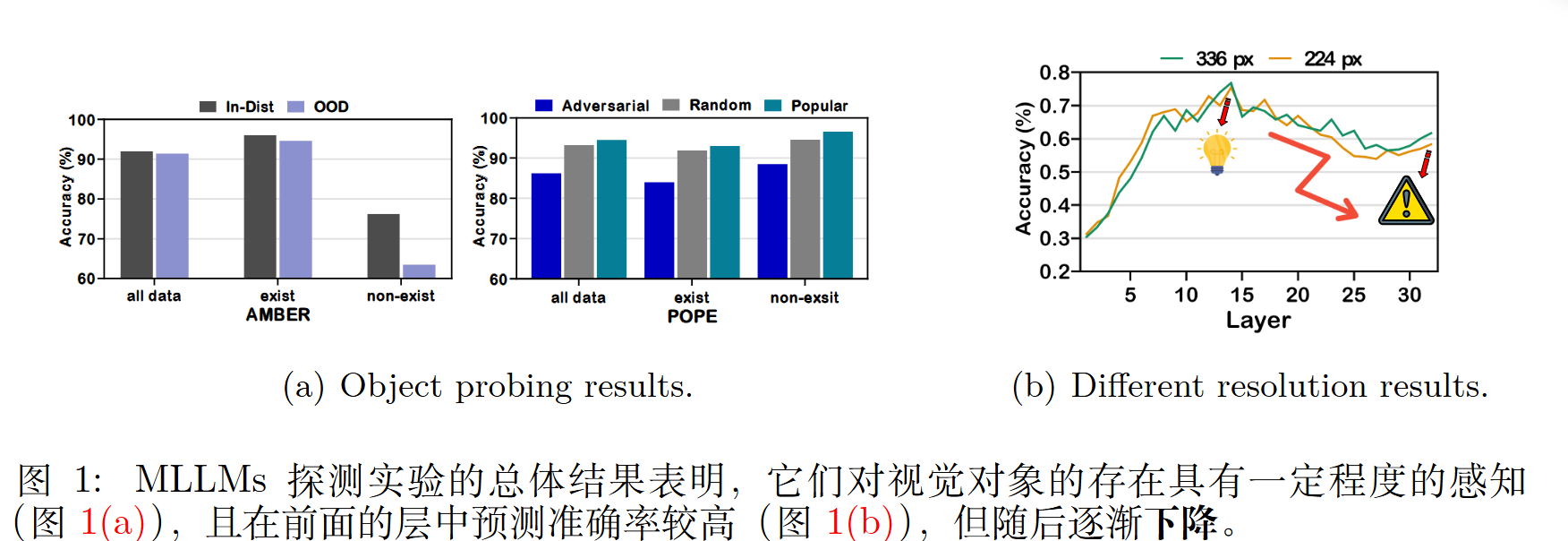
发现一:MLLM 在某种程度上“知道”物体是否存在。
作者在 MLLM 的每一层(共32层)的隐藏状态上训练了简单的“探针”分类器 ,用于判断某个物体是否存在于图像中。
探针实验显示,即使模型最终“编造”了一个不存在的物体,模型中间层(特别是前序层)的探针分类器也能以高准确率(约 80%)判断出该物体是“不存在”的 。
这种识别能力在前序层中(例如 10-15 层附近)达到峰值,但在更深的层(靠近输出层)中,准确率反而逐渐下降 。
发现二:语言模型的“知识先验”压制了视觉信息
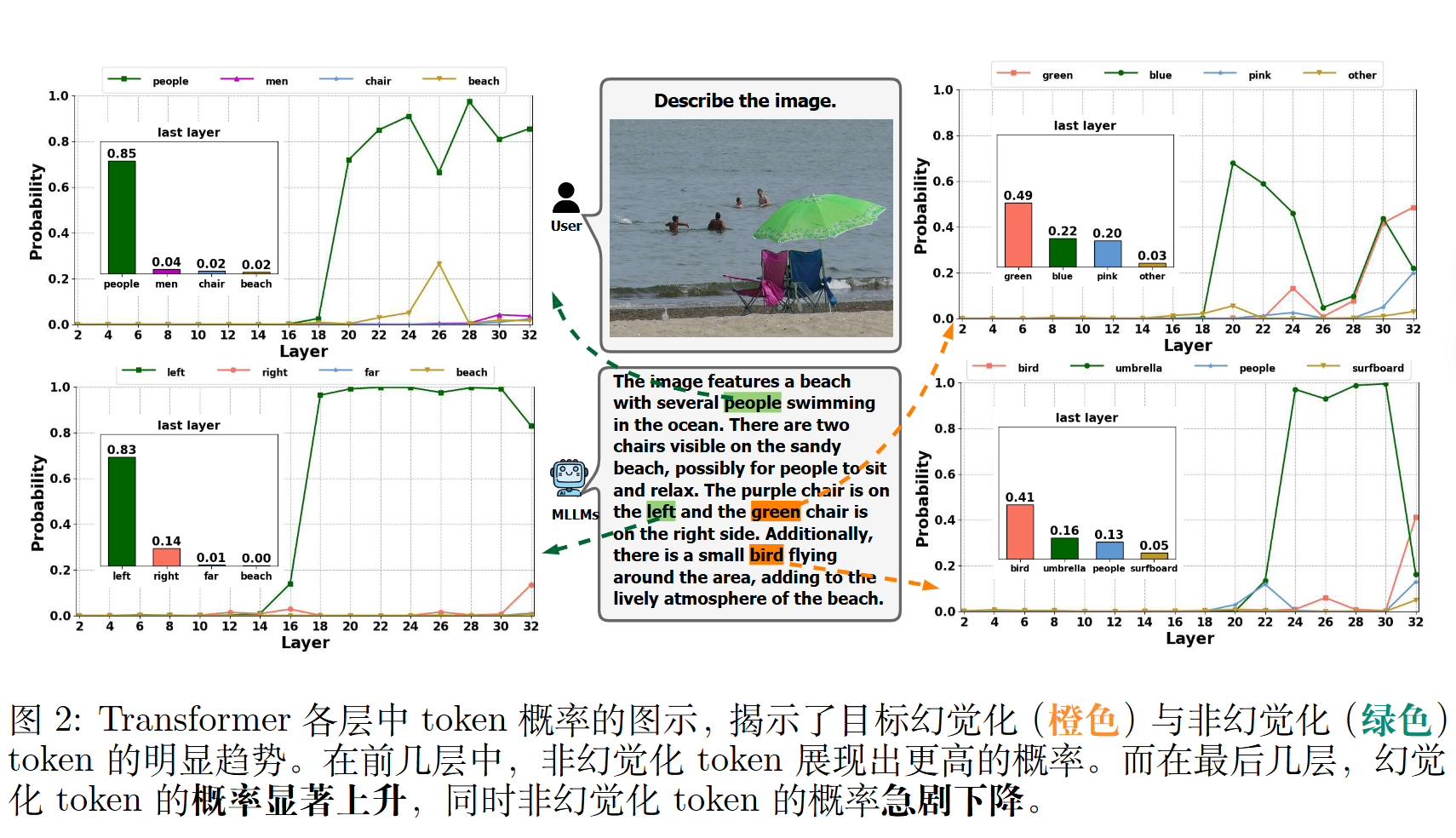
作者进行了一项实验,在不输入任何图像的情况下,仅凭语言模型固有的知识先验,模型仍然倾向于生成那些原始的幻觉词元(重叠率高达 91.05%) 。
方法
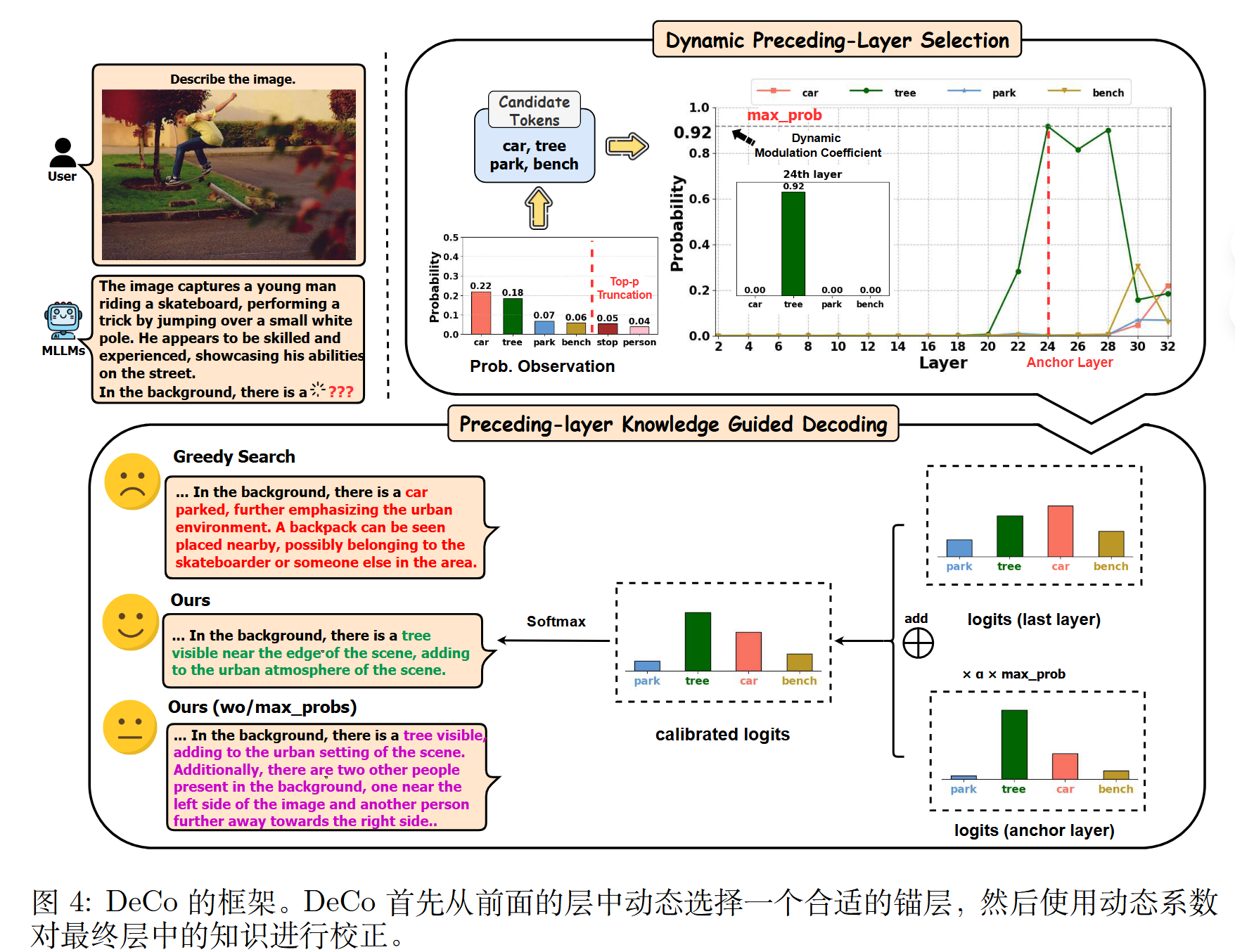
作者做法基于一个假设:关键 token 通常出现在MLLM 最后一层输出 Logit 的顶部位置。
步骤一:动态前序层选择 (Dynamic Preceding-Layer Selection)
- 获取候选词元:首先,模型正常计算到最后一层,得到一个词汇表的概率分布。使用 Top-p 采样等策略,筛选出一小组“候选词元” ($\mathcal{V} _ {candidate}$) 。
$$ \mathcal{V} _ {candidate}(x_T|x _ {<T}) = \left\{ x_T \in \mathcal{V} : \sum _ {v \in \mathcal{V}_p} P(x_T = v | x_0,x_1, …, x _ {T-1}) \le p \right\} $$
- 定位“锚点层”:DeCo 会回溯到指定的前序层区间(例如第 20 到 28 层) 。它会检查在这些层中,哪一层给出的“候选词元”的概率最高 。
- 选定锚点层:这个在前序层中赋予候选词元最高概率的层,被选为“锚点层” ($\mathcal{A}$) 。DeCo 假设这一层包含了最准确的视觉知识。
步骤二:前序层知识引导解码 (Preceding-layer Knowledge Guided Decoding)
动态软调制 (Dynamic Soft Modulation):为了防止纠正过程过于“生硬”而破坏句子的流畅性 ,DeCo 引入了一个动态系数 $max _ {prob}$ 。这个系数就是“锚点层”赋予那个最高概率词元的概率值 。
logits 纠正:DeCo 将最后一层的 logits (记为 $\phi(h _ {T-1}^{N})$) 和锚点层的 logits (记为 $\phi(h _ {T-1}^{\mathcal{A}})$) 进行加权融合。
作者引入了一个动态调制系数,默认设置为最大概率:
$$
max_prob=max(softmax(\phi(h _ {T-1}^\mathcal{A})))
$$
最终的 logits 计算公式如下 :$$
logits = \phi(h _ {T-1}^{N}) + \alpha \times max_prob \times \phi(h _ {T-1}^{\mathcal{A}})
$$其中$\phi(h _ {T-1}^{N})$ 是最后一层的 logits ,$\phi(h _ {T-1}^{\mathcal{A}})$ 是锚点层(前序层)的 logits。