ICT:Image-Object Cross-Level Trusted Intervention for Mitigating Object Hallucination in Large Vision-Language Models
(CVPR 2025)
这篇论文主要针对物体幻觉。
作者认为产生幻觉的主要原因是:
1.过度的语言先验(Excessive Language Priors): LVLM 通常由一个视觉编码器和一个强大的大型语言模型(LLM)组成。LLM 的参数量和能力远超视觉编码器 。这导致模型在回答时,过度依赖其在训练中学到的语言知识(先验),而忽视了当前的视觉输入 。
2.细粒度视觉语义捕获不准: 当前的视觉解码器难以准确捕捉图像中的细粒度细节(如物体的精确颜色或数量) 。
已有的缓解幻觉的方法主要有三类,但都有缺陷:
- 使用额外数据进行微调: 需要大量高质量的人工标注数据,不仅成本高昂,而且需要消耗大量计算资源来更新模型参数 。
- 感知增强:这种方法结合了额外的信息,如深度图和分割图
比如CVPR 2024的《VCoder: Versatile Vision Encoders for Multimodal Large Language Models》
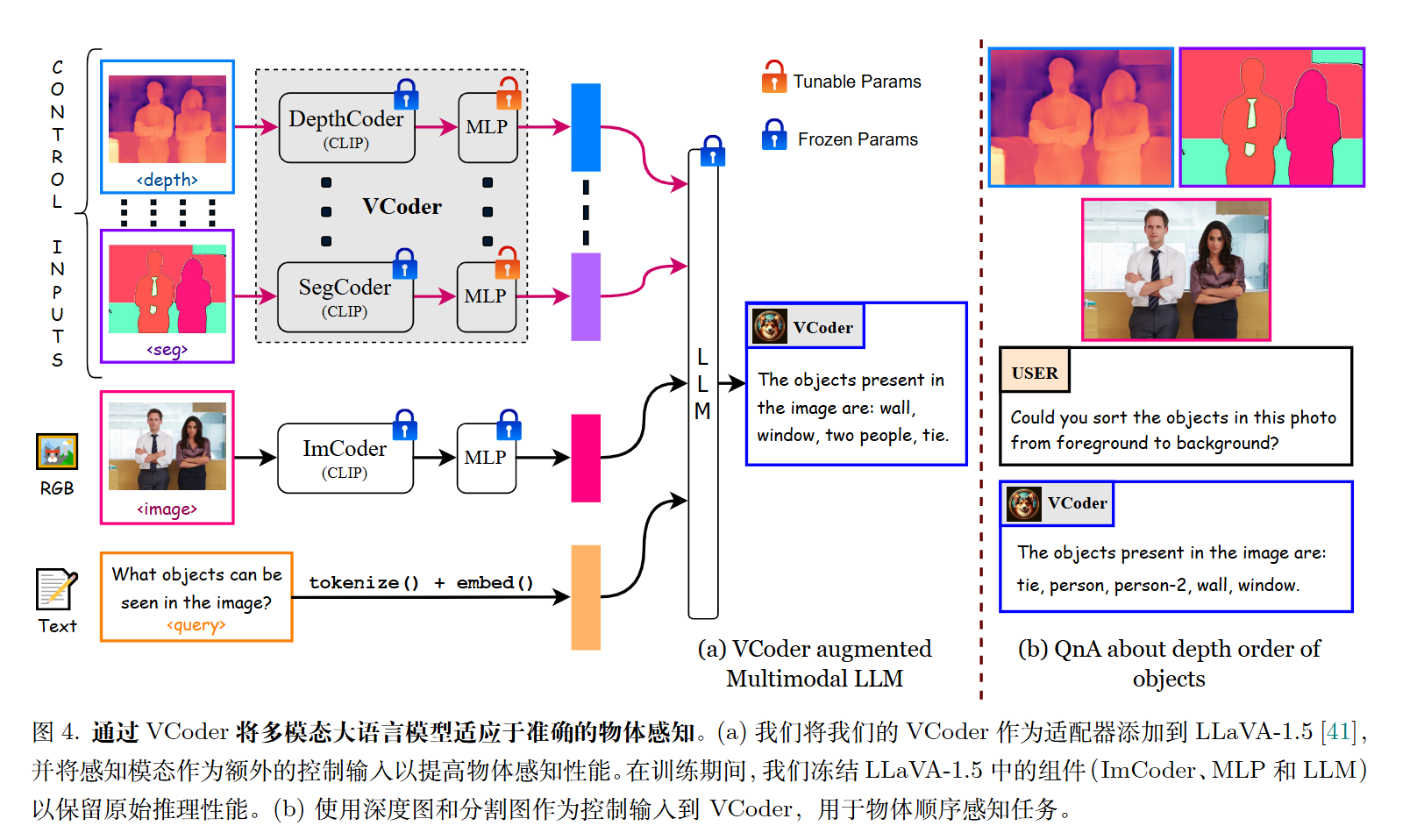
- 对比解码。缺陷:错杀有益先验: VCD 无法区分“有害的幻觉先验”和“有益的知识先验” 。它会无差别地消除所有语言先验,包括那些对正确推理有帮助的知识。推理延迟高。
方法
模型分为图像级干预和对象级干预。
前一个模块使用的是类似VCD的全局高斯加噪(diffusion),使 LVLM 能够关注图像,从而减少对语言先验的过度依赖。
后一个模块使用Grounding DINO,根据提示词去找到对应的物体。鼓励 LVLM 更密切地注意图像中的物体,有助于减轻关键物体的遗漏并减少幻觉。
计算偏移量
$$
S=\frac{1}{B}\sum (A^{(l)} _ {i,n}-A’^{(l)} _ {i,n})
$$
其中A为原始,A‘为扰动。
并构造可信数据对$(q+O_i,V_i)$和不可信数据对$(q+O_i,V_i’)$。
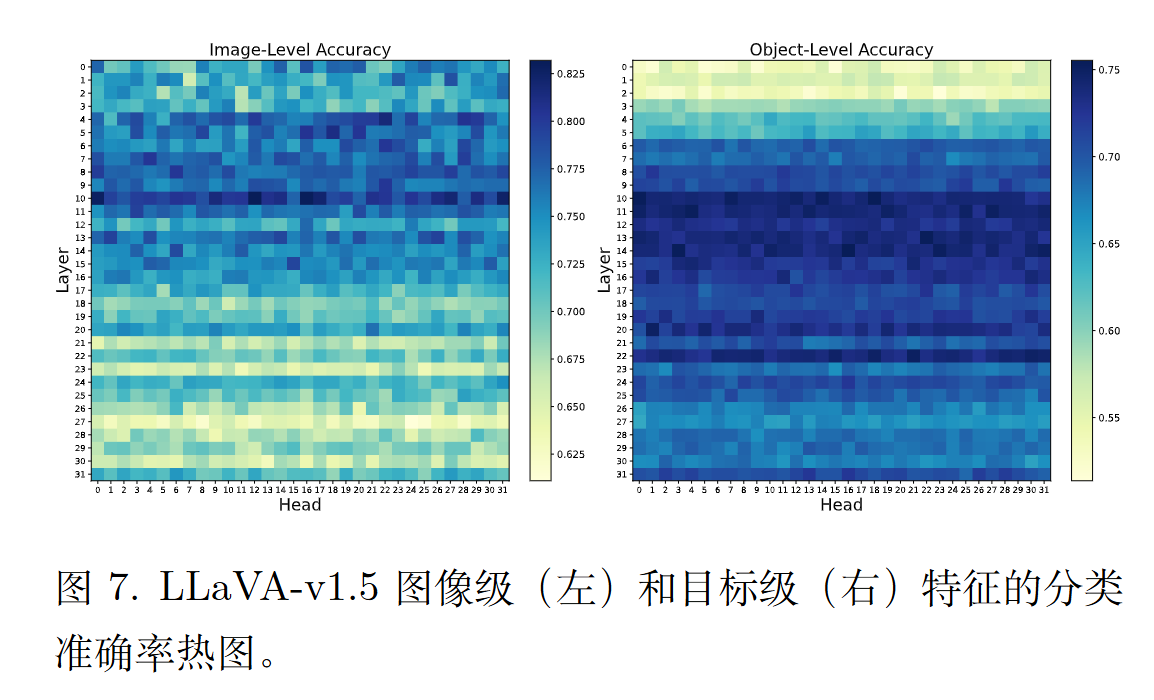
作者还有一个筛选注意力头的过程。即使用二分类器(SVM),特征是注意力头的激活值,标签是可信or不可信。选择准确率top-k个注意力头。
缺点是一个像 LLaVA-v1.5 这样的模型拥有很多注意力头(例如,32层,每层32个头,总共1024个头) 。这样就有1024的头,太多了。
最后将将图像级和对象级的干预模块进行整合。
$$
H^{(l+1)} = H^{(l)} + \sum _ {n=1}^{N} \left( \text{Attn}_n^{(l)}(H^{(l)}) + 1 _ {\text{img},n}^{(l)} \alpha S_n^{(l)} + 1 _ {\text{obj},n}^{(l)} \beta S _ {\text{obj},n}^{(l)} \right) \cdot W_o^{(l)}
$$
实验
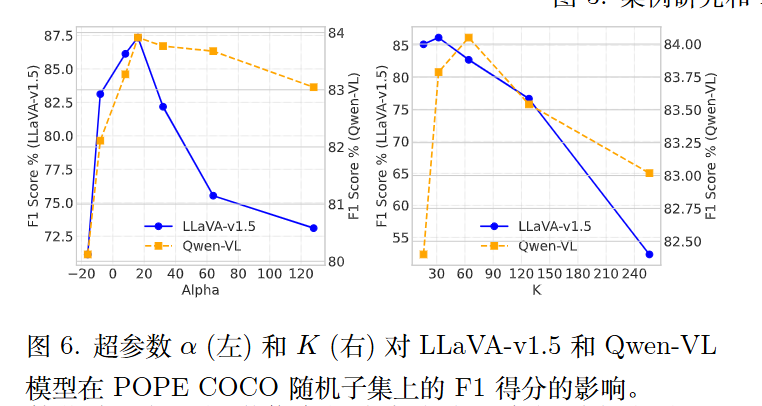
可以看出参数还是比较敏感的。