少即是多:从 EOS 决策角度缓解多模态幻觉
(ACL 2024)
motivation
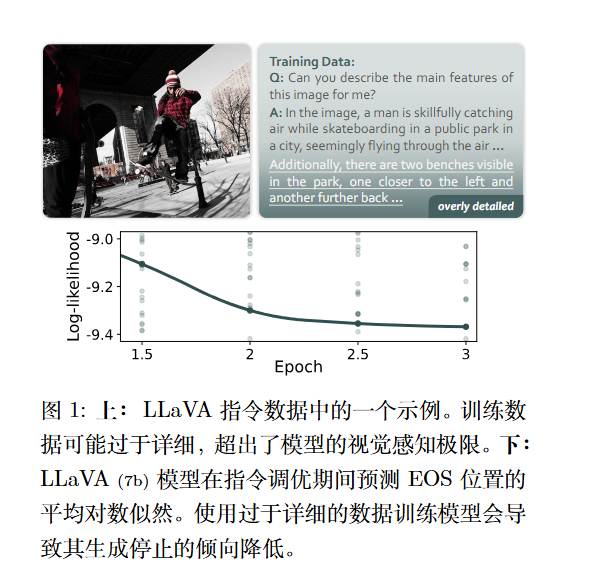
一个关于多模态模型(LVLMs)产生“幻觉”(即生成与图像不符的文本内容)的新观点 。作者认为,一个常被忽视的关键原因是训练数据“过度详细” 。
即许多训练数据(如LLaVA的 instruction data)包含了极其丰富的细节,这些细节甚至超出了模型当前的视觉感知能力 。模型在训练时,为了强行拟合这些它“看”不到的细节(为了匹配标注的长度和详细程度),被迫开始“凭空编造”内容,从而导致了幻觉 。
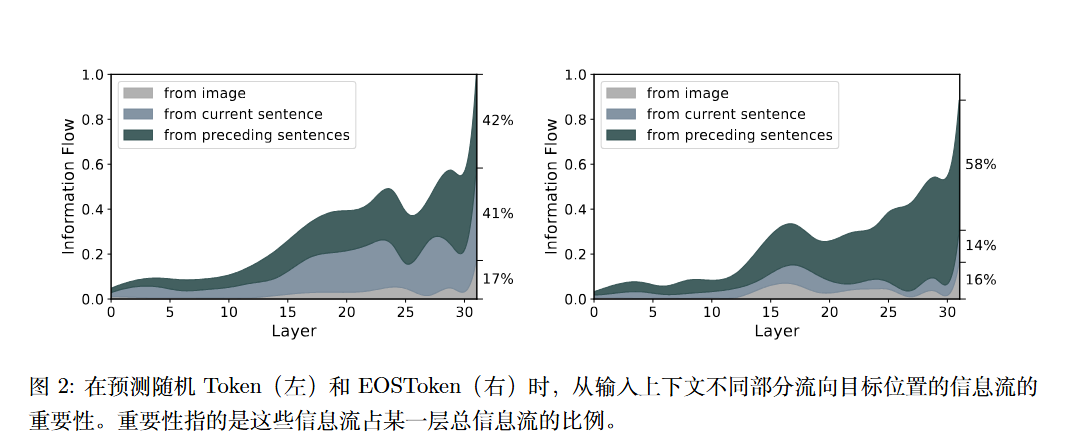
作者通过实验发现:预测普通内容的时候,模型更依赖当前句子的信息。预测$v_{EOS}$时,模型显著更依赖于“所有前面的句子”。
(使用的是显著性矩阵$I=\left|A\odot \frac{\partial\mathcal{L}(x)}{\partial A} \right|$)
另外,作者也去消除语义和增加语义以探索$v_{EOS}$的变化。
- image-:应用高斯噪声掩码
- image+:将图像与随机图像拼接,以引入当前文本中未描述的视觉信息。(作者还实现了一种变体,将输入图像替换为随机新图像而非进行拼接,以避免增加绝对信息丰富度)
- text-:使用注意力掩码来隐藏部分暴露的文本。作者使用的是掩码前 30个 token,以确保序列末尾部分$v_{EOS}$预测的相邻上下文连贯性。
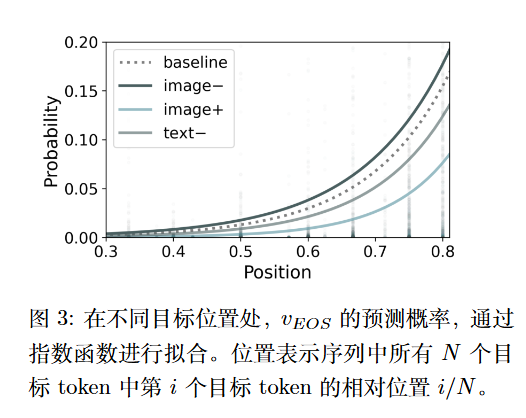
这些实验证实,模型确实在通过比较“已生成的文本”和“感知到的视觉信息”来评估完整性,并以此决定是否停止 。模型天生就具备这种根据视觉感知极限“适可而止”的潜力 。
标准训练(MLE)的缺陷
标准的“最大似然估计”(MLE)训练目标会破坏上述的“适可而止”机制。
在训练时,当模型在某个位置(比如句子中间)认为“我已经描述完了”($p_{v_{EOS}}$ 概率很高),但此时的标签(label)并不是 $v_{EOS}$,而是一个普通的内容 token(因为训练数据过度详细,要求它继续说) 。
在这种情况下,MLE 会惩罚模型产生 $v_{EOS}$ 的想法,迫使它降低 $p_{v_{EOS}}$,并鼓励它继续生成内容。这就等于在训练模型“即使超出了你的视觉感知极限,也要继续说”,从而加剧了幻觉。
方法
选择性EOS监督(Selective EOS Supervision, SES)
这是一种改进的训练目标(Learning Objective)。
目标: 在不影响学习内容生成的同时,保护模型在非 $v_{EOS}$ 位置上“想要停止”的内在倾向。
具体做法:
当标签是 $v_{EOS}$ 时: 保持原样,使用标准 MLE 训练,让模型学会何时该停止。
当标签不是 $v_{EOS}$ 时: 修改 softmax 计算。在计算概率分布时,将 $v_{EOS}$ token 排除在外 。
EOS监督评分(Scoring EOS Supervision)
这是一种数据过滤策略(Data Filtering Strategy)。
目标: 识别并过滤掉那些“有害”的(即会严重抑制模型 EOS 倾向的)训练数据。
具体做法:
设计两个分数来评估每条数据 :
$S_{pos}$(正面效应): 评估数据在“应该停止”的位置($y = v_{EOS}$)教会模型停止的能力。$S_{pos}$ 越高,说明模型在此处本不想停而数据强迫它停,正面效应越强 。
$S_{neg}$(负面效应): 评估数据在“不该停止”的位置($y \ne v_{EOS}$)抑制模型停止倾向的程度。$S_{neg}$ 越高,说明模型在此处本想停而数据强迫它继续说,负面效应(危害)越大 。
$S_{final} = S_{neg} - S_{pos}$ 。$S_{final}$ 越高的数据,被认为“危害越大”。
移除训练集中 $S_{final}$ 分数最高的数据(例如,移除Top 20%)。