性能提升的幻觉:为什么对比解码无法缓解多模态大模型中的对象幻觉问题?
(NIPS 2025)
作者认为,目前的一些对比解码方法在POPE等基准测试上观察到的性能提升是一种假象 ,并非真正解决了幻觉问题。
在 POPE 基准上观察到的性能提升主要由两个误导性因素驱动:
R1 :一种单向调整输出分布的方法,该方法简单地使模型更倾向于生成更多的“是”类输出,从而在某些数据集上实现分布平衡。
R2 :这些方法中的自适应约束将采样解码策略退化为贪心搜索的近似,导致性能出现欺骗性的提升。
对比解码
对比解码由两个部分组成。
解码模块. $(1+\alpha)原始logits-\alpha\cdot 幻觉logits$
生成幻觉有分为指令级或者或者图像级或者模型级(从自我内部生成)。
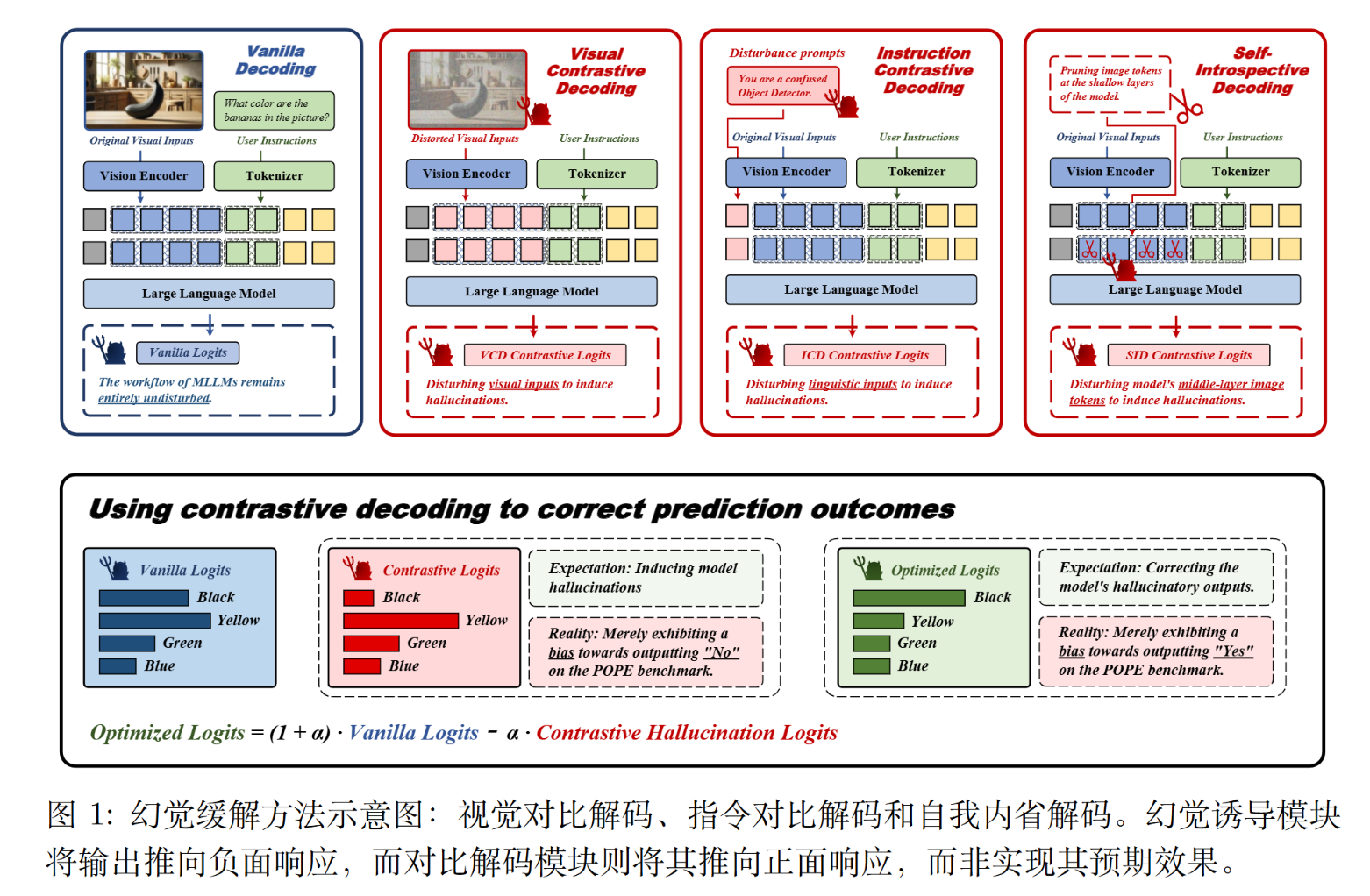
自适应合理性约束.
$$
\begin{align}
\mathcal{V} _ {head}(y _ {<t})&=(y_t\in\mathcal{V}\mid p_\theta(y_t\mid v,x,y _ {<t})\ge \beta max_w p_\theta(w\mid v,x,y _ {<t}))\\
p _ {cd}(y_t\mid v ,x)&=0\text{ if }y_t \notin \mathcal{V} _ {head}(y _ {<t})
\end{align}
$$
POPE
POPE是评估多模态大模型(MLLMs)的对象幻觉的数据集。与基于描述的方法不同,它将幻觉检测问题定义为一个二分类任务,采用直接的是或否问答形式(例如,“图像中是否有椅子?”),从而实现更清晰的解释性。该基准确保了“是”和“否”样本的均衡分布(各占 50%)。
误导性性能提升
单向的“Yes”偏见
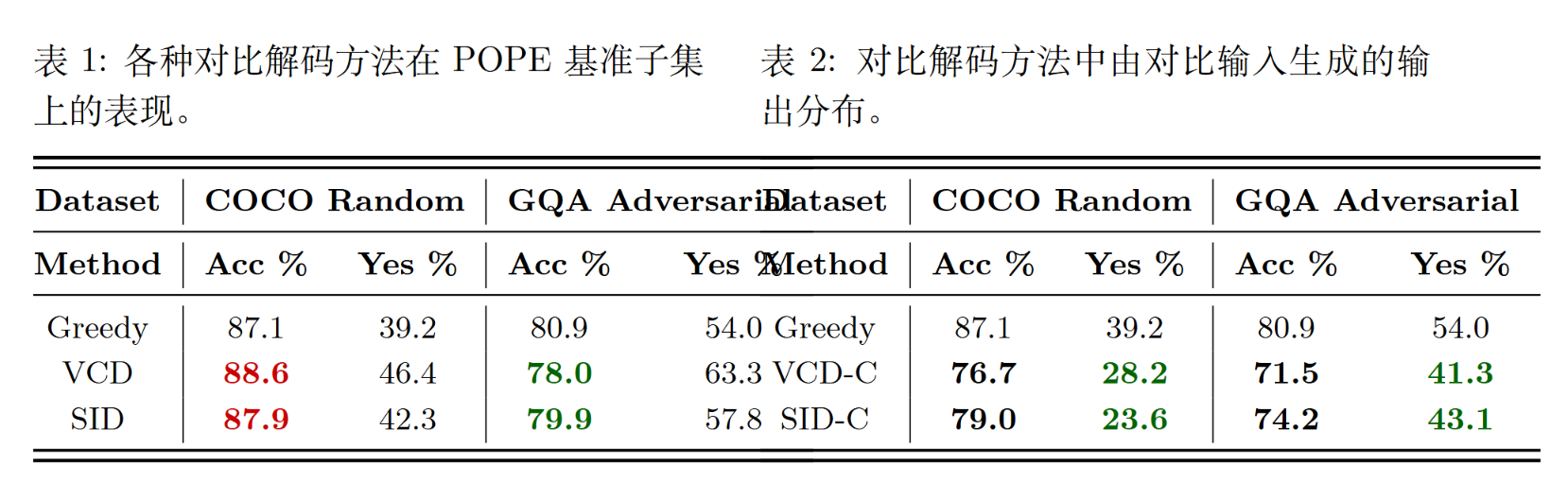
MLLM(如LLaVA)在回答POPE问题时,其原始输出严重偏向于“否”(No)。
而VCD和SID 均显著地将模型输出分布向“Yes”倾斜。
对比解码这种“强行增加Yes”的策略,恰好中和了模型本身的“No”偏见,使得“Yes/No”的比例趋于平衡(POPE的真实答案是50% Yes / 50% No ),从而在表面上提高了准确率 。
在另一些模型已经偏向“Yes”的数据集(如GQA-Adversarial)上,使用对比解码会进一步加剧“Yes”偏见,反而导致性能下降 。
采样解码退化为贪婪搜索
且在有些论文中,认为贪心搜索在绝大多数任务上均优于直接采样。(出自《Contrastive decoding: Open-ended text generation as optimization》)。许多对比解码方法报告了采用采样策略带来的性能提升,这需要对这些说法进行更深入的审视。
当应用自适应合理性约束时,许多候选选项因不满足条件而被剔除。
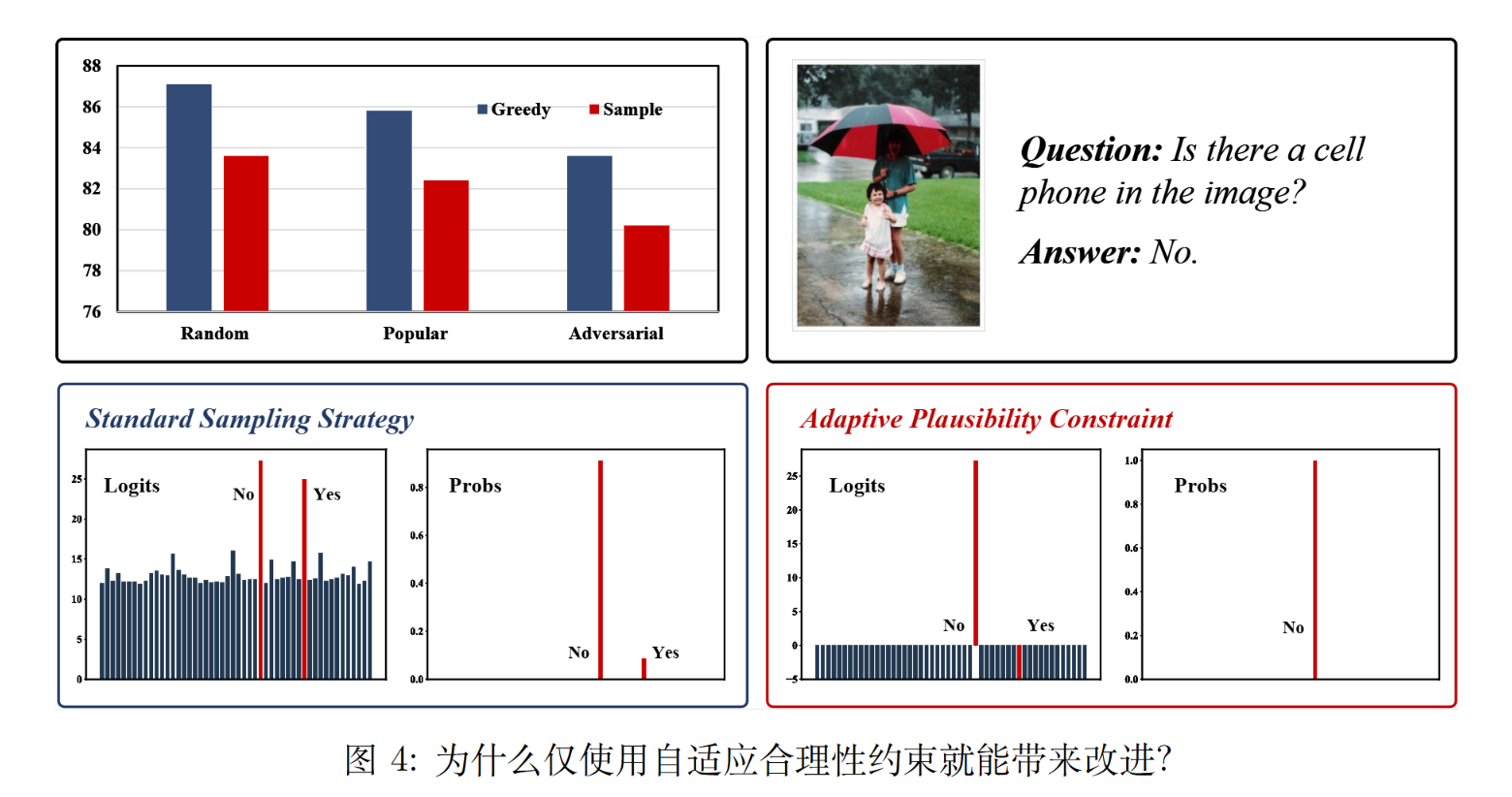
比如上图中,LLaVA-v1.5-7B 模型生成的正确答案分布为:是:8.8%
和 否:91.2%。采用贪心搜索策略时,模型始终生成正确答案” 否”。然而,在采用采样策略时,模型有 8.8% 的概率生成错误答案” 是”。
当应用自适应合理性约束时,可能只剩下否,采样策略简化为贪心搜索。
虚假改进的方法
为了证明上述两个因素是“刷分”的真正原因,作者设计了两种虚假改进方法,这些方法完全不涉及幻觉缓解,只模仿那两个误导性因素。
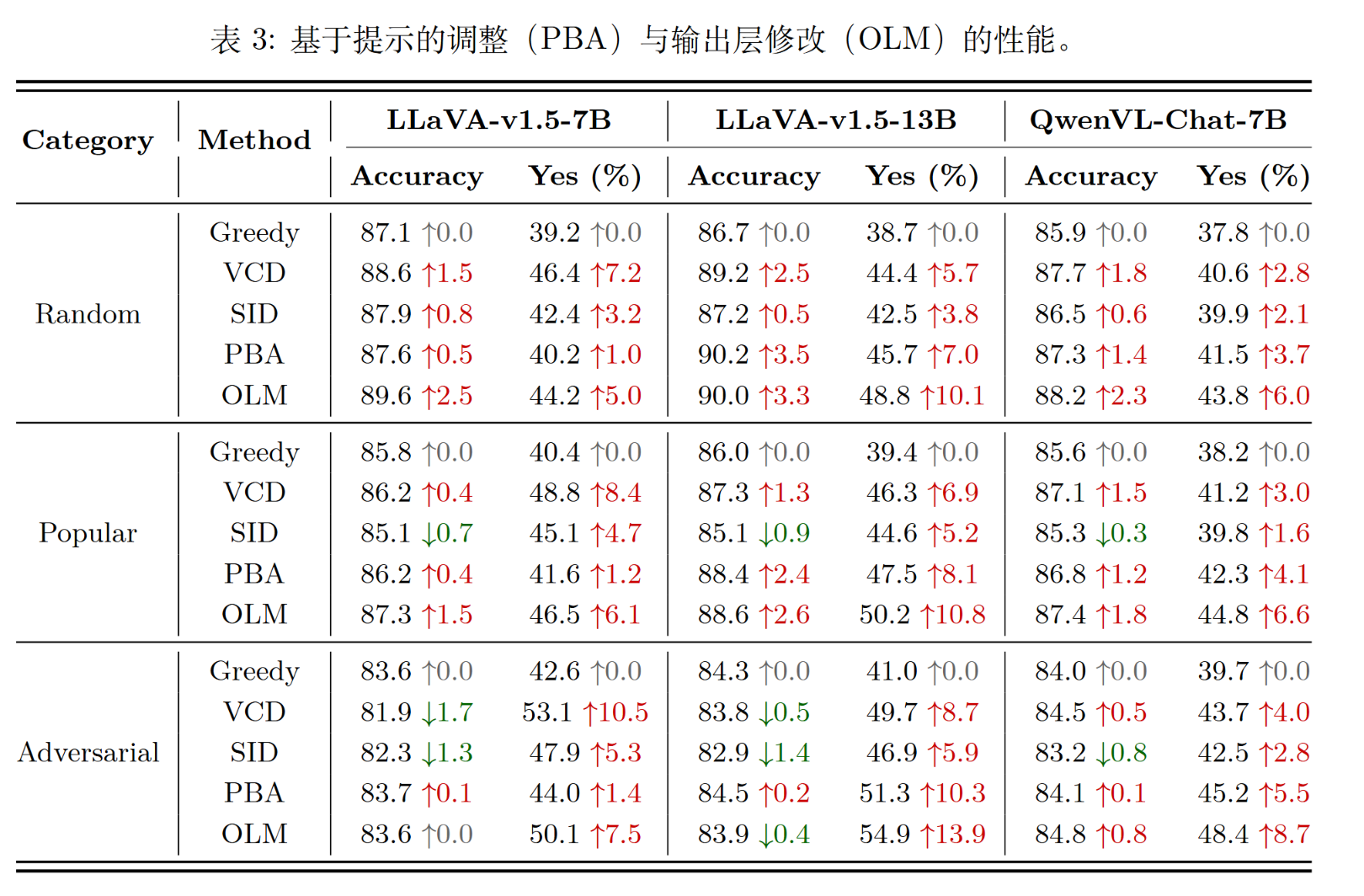
实验一:模仿“Yes”偏见
- 方法A (PBA):在提示词中加入“如果可能,请回答Yes” 。
- 方法B (OLM):在输出层修改,如果“Yes”和“No”的概率很接近,就强行改成“Yes” 。
- 结果:在POPE上,这两种“作弊”方法取得了与VCD和SID相当甚至更好的性能提升 。
实验二:模仿“采样退化”
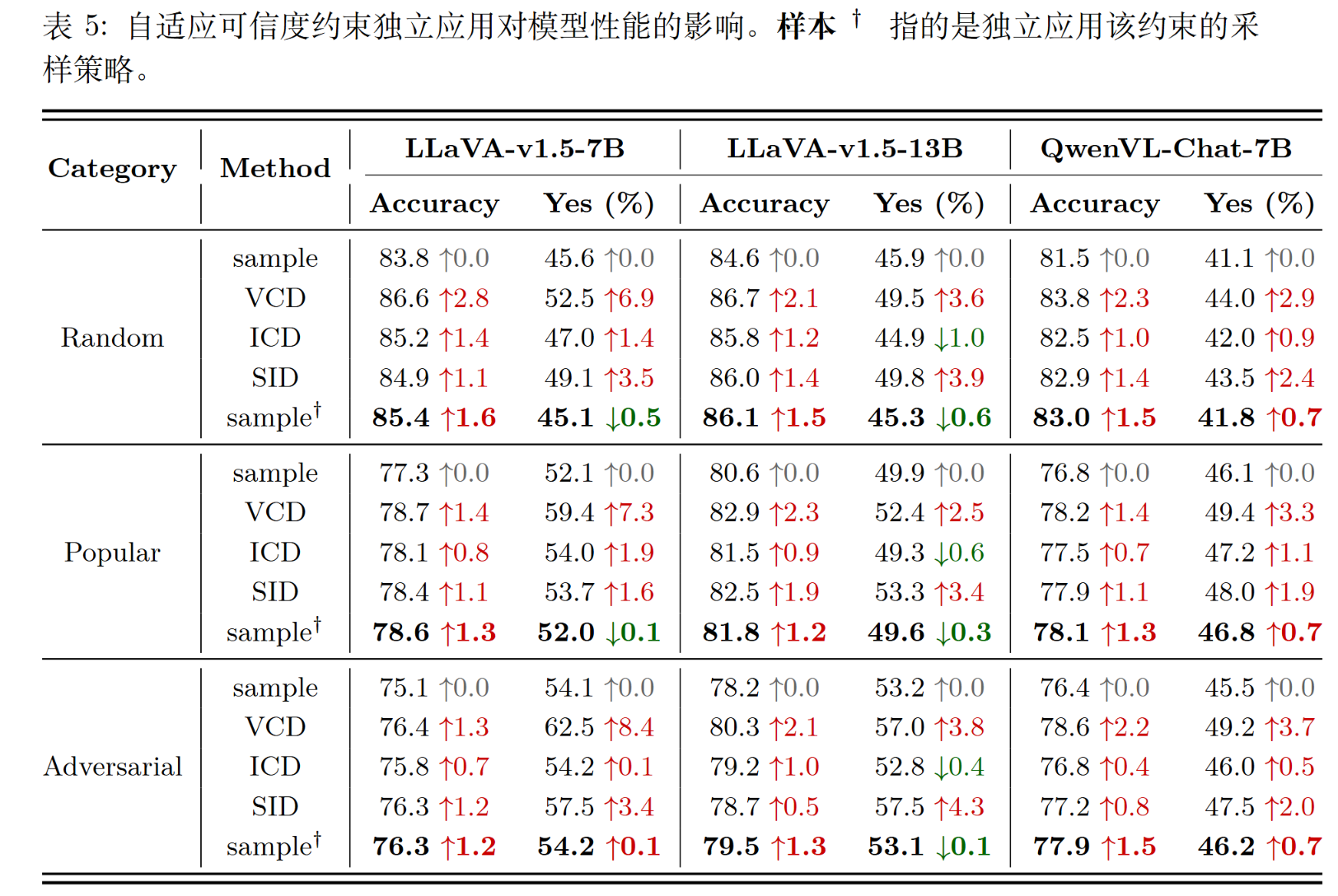
- 方法:不使用完整的对比解码,只使用“自适应合理性约束”(APC)模块,并配合采样策略 。
- 结果:仅仅使用APC这一个模块,就取得了和完整VCD、ICD、SID方法几乎相同的性能提升 。
- 结论:这有力地证明了,在采样模式下,所有的性能提升都来自APC(即采样退化为贪婪搜索),而与对比解码逻辑无关 。
其他数据集
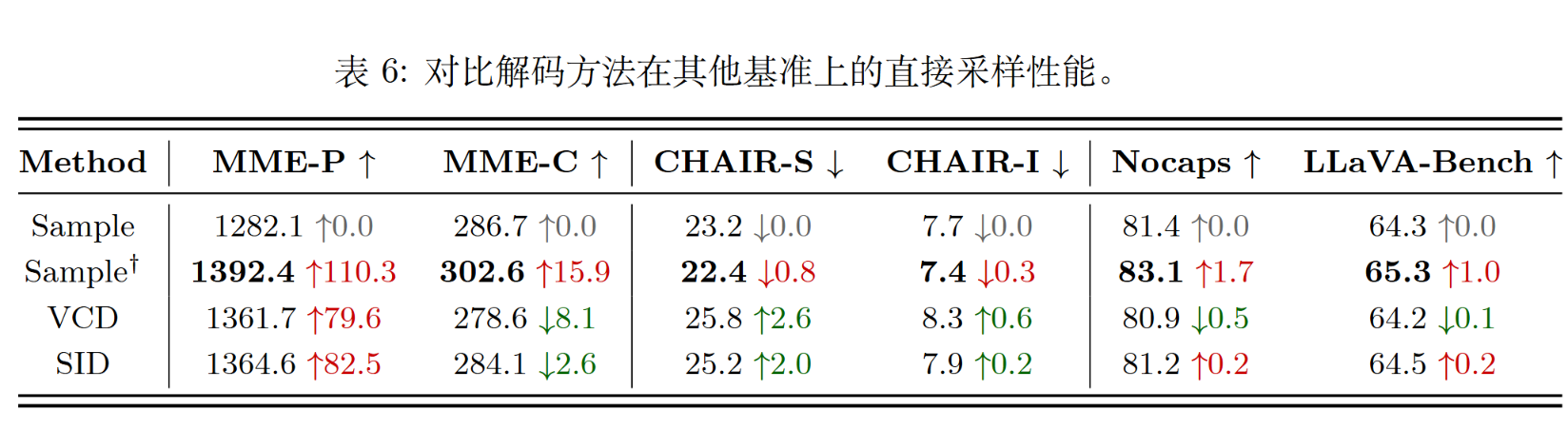
除了POPE的二分类数据集,还有CHAIR等幻觉评估数据集。作者事实上也做了一些实验。