频域特征对多模态大模型的幻觉影响
(arxiv 3月)Mitigating Object Hallucinations in MLLMs via Multi-Frequency Perturbations
目前仍缺乏研究探讨视觉特征在频域中对多模态大模型(MLLMs)的作用。甚至尚未有先验工作探索其在 MLLMs 中的物体幻觉现象中的作用。
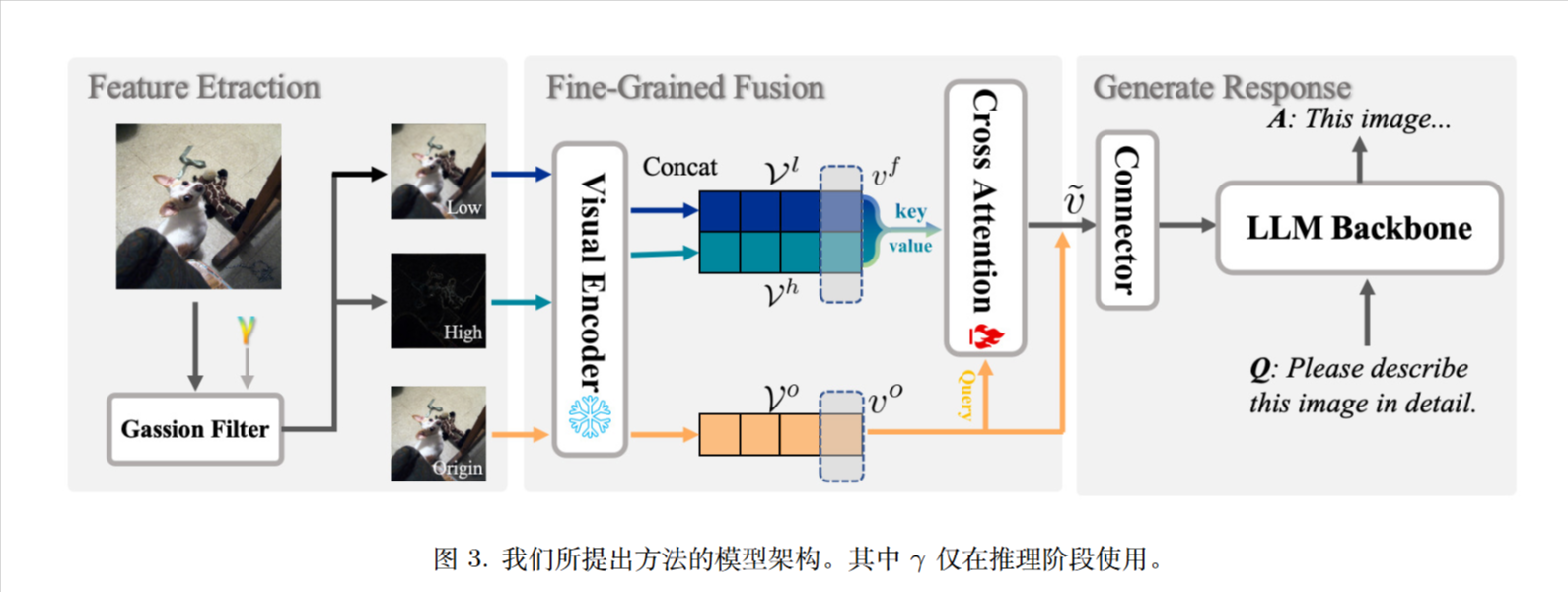
作者实验,无论“高频”还是“低频”被移除,模型的幻觉比例都会显著增加。这表明这两种信息对模型的正确理解都至关重要。
方法:
使用高斯来过滤高低频。也惯用地使用了时域卷积等于频域乘积。
使用一个衰减因子 γ 来调节低频和高频特征的强度。
$$
\begin{cases}
F_c^l(u, v) = \mathcal{F}_c(u, v) \cdot \mathcal{H}_c^l(u, v) \cdot G(\gamma) \\
F_c^h(u, v) = \mathcal{F}_c(u, v) \cdot \mathcal{H}_c^h(u, v) \cdot G(\gamma)
\end{cases}
$$
其中 $G(\gamma)$ 是一个矩阵,其值通过从均匀分布 $U(0, \gamma)$ 中随机采样得到,其中 $\gamma \le 1$。
(arxiv 7月)On the Reliability of Vision-Language Models Under Adversarial Frequency-Domain Perturbations
研究发现表明,VLM 用于区分真实内容与生成内容所学成的决策边界出人意料地脆弱,尤其是在保持图像质量的扰动下。这引发了一个假设:即 VLM,尤其是参数较少的模型,可能依赖频域特征作为真实性代理,而非基于语义内容进行预测。
将频率扰动框架扩展至自动图像描述任务,表明中频域的扰动可以显著降低 VLM 生成描述的语义丰富度,而不会改变图像的高层感知内容。
在频率域中采用稀疏且结构化的扰动能够可靠地操控模型预测,揭示了 VLM 在解读视觉输入时存在系统性漏洞。我们的发现表明,其推理过程本质上依赖于低层次图像结构,而非高层次语义。
论文主要关注于真实性检测(deepfake检测)和图像描述任务。
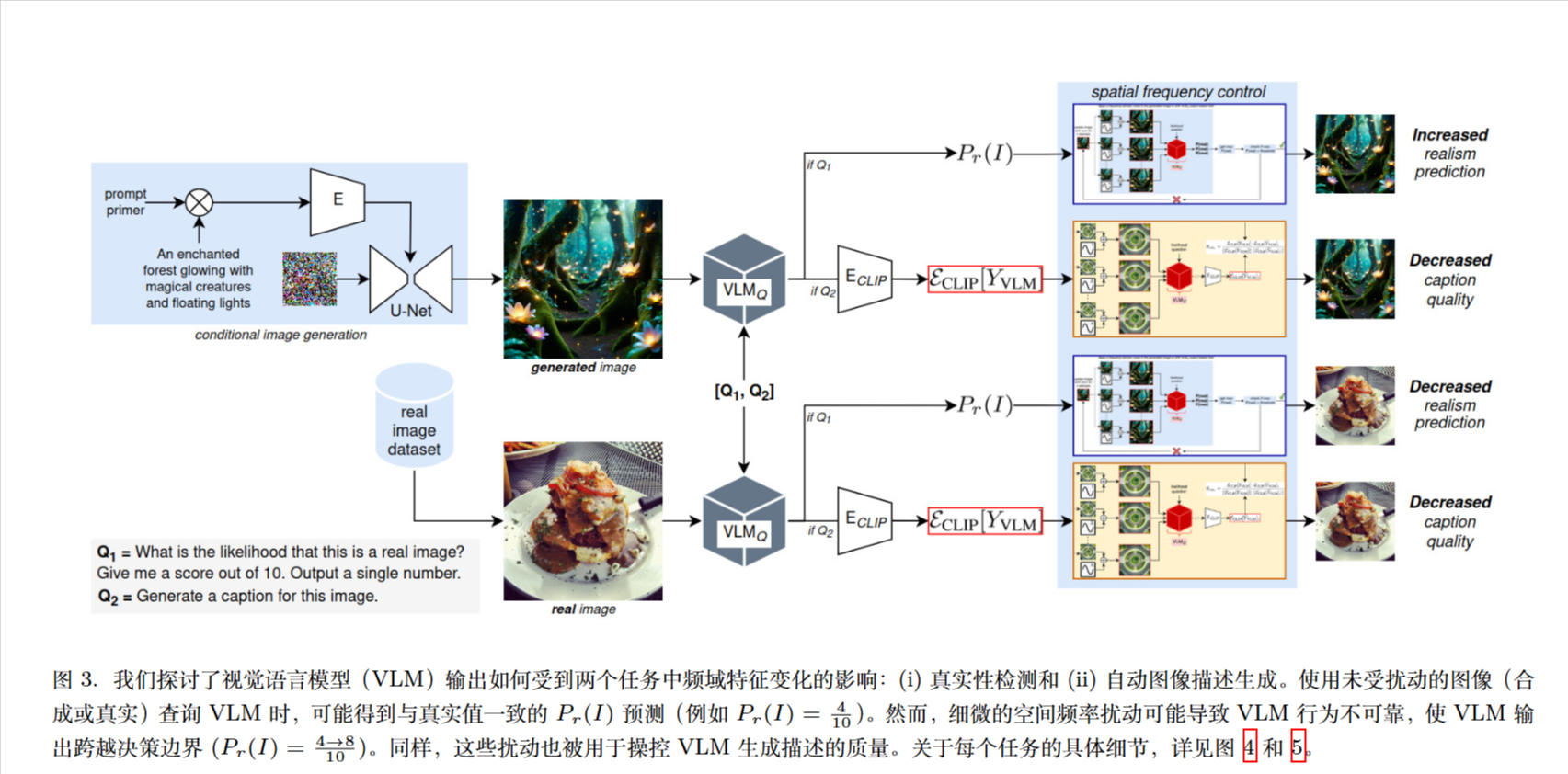
真实性检测
真实图像对高频扰动的敏感度甚至高于 AI 生成的图像 。这强烈暗示 VLM 确实在“走捷径”:它们将“高频细节的统计特征”当作判断真实性的关键指标,而不是真正理解图像内容 。
图像描述
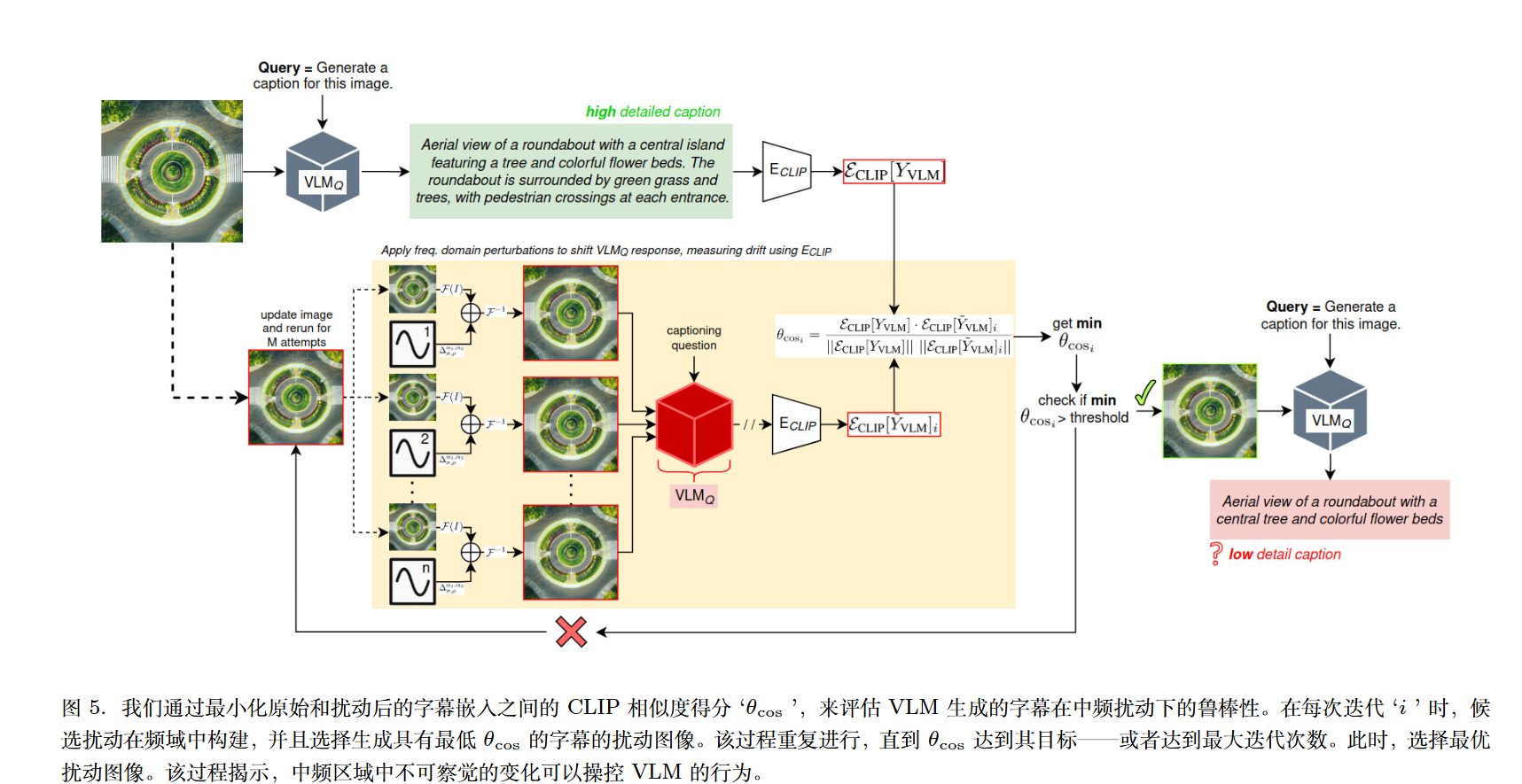
采用一个辅助的 CLIP 编码器,将原始 VLM 输出和对抗性 VLM 输出投影到共享的 CLIP 空间中。
比较原始与对抗性描述嵌入,并应用相似度阈值0.5作为攻击成功的标准。
在每一轮中,攻击者会在图像的中频带(论文假设该区域与物体特征相关)生成多组微小的“候选扰动” 。选择最好的并重复以上操作。
比较笨的方法。

(TDSC 2025)A Multimodal Adversarial Attack Method via Frequency Domain Enhancement and Fine-grained Cross-modal Guidance
大多数现有的基于频率的方法仅关注视觉模态,而忽略了与语言的跨模态交互。
现有的对抗攻击方法通常采用空间域增强来提高对抗 样本在黑盒模型中的可迁移性。旋转、裁剪和翻转等技术 增加了样本的多样性。然而,这些增强技术仍然依赖于原 始数据的变换,这可能导致模型在训练过程中过度拟合细 节和噪声,最终限制对抗样本的泛化能力。
方法
图像模态:频域增强 (Frequency-domain Enhancement)
动机:减少对高频细节和噪声的依赖,转而攻击更稳定的低频结构信息,以提高迁移性 。
使用DFT来消除高频。
结合空间增强:在频域增强的基础上,仍然辅以多尺度变换和高斯噪声等空间域增强手段,以增加样本多样性 。
文本模态:细粒度跨模态指导 (Fine-grained Cross-modal Guidance)
动机:现有的文本攻击只关注词级别,粒度太粗 。作者类比图像的频率,认为词级别特征(Word-level)类似高频(细节),而句子级别特征(Sentence-level)类似低频(全局)。
多级特征提取:使用BERT模型
- 提取词级别特征 $h _ {w_i}$ (每个token的隐藏状态)。
- 提取句子级别特征 $h_s$ ([CLS] token的嵌入)。
细粒度重要性评分:为了找到最值得替换的“关键词”,作者设计了一个新的评分公式 $S_i$ :
- $S_i^{KL}$:计算原始文本嵌入与Mask掉单词 $w_i$ 后的文本嵌入之间的KL散度。这衡量了该词对整个句子信息的改变程度。
- $S_i^{cos}$:计算词级别特征 $h _ {w_i}$ 和句子级别特征 $h_s$ 之间的余弦相似度($1 - \text{sim}$)。这衡量了该词与全局上下文的关联度。
- 最终得分:$S_i = \lambda S_i^{KL} + (1-\lambda)S_i^{cos}$ 。$\lambda$ 是一个超参数(实验中设为0.7)。
生成对抗文本:根据 $S_i$ 得分选择Top-k个词进行替换 ,并利用图像嵌入作为指导,通过梯度迭代优化对抗文本的嵌入。
$$
t _ {i+1}^{adv}=t _ {i}^{adv}+\alpha\cdot sgn(\frac{\sum _ {j=1}^{\epsilon_t} \nabla h _ {v_j}(h_v,h_t)}{||\sum _ {j=1}^{\epsilon_t} \nabla h _ {v_j}(h_v,h_t)||})
$$
生成对抗图像:最后,使用生成的对抗文本嵌入 $h _ {tj}^{adv}$ 作为指导 ,计算相似度矩阵:
$$
sim _ {ij}=h _ {v_i}\cdot h _ {tj}^{adv^T}
$$
对经过频域增强的图像使用PGD等方法进行攻击,目标是最大化地破坏图像和对抗文本之间的对齐关系。
额外阅读
2.[1903.00073] On the Effectiveness of Low Frequency Perturbations