ChunkLLM:A Lightweight Pluggable Framework for Accelerating LLMs Inference
(arxiv 2025)2510.02361
ChunkLLM 不仅在短文本基准上达到与基线相当的性能,同时在长上下文基准上仍保持 98.64% 的性能,并维持48.58% 的关键值缓存保留率。特别地,在处理 120K 长文本时,ChunkLLM相较于原始 Transformer 实现了最高达 4.48× 的加速比。
现有方法的局限性:
- 线性注意力(Linear Attention)(如Mamba, RWKV):虽然高效,但其结构与传统Transformer不同,导致难以迁移预训练好的模型,通常需要从头训练 。
- 稀疏注意力(Sparse Attention):如滑动窗口 或固定模式,但这些方法往往依赖特定任务,泛化能力受限 。
- 块选择(Chunk Selection):现有的分块方法要么是固定长度(导致语义不完整),要么是基于分隔符(如句号),但分隔符本身存在歧义(例如,句号也可能出现在数字或缩写中)。此外,这些方法通常需要在每生成一个新token时都重新进行块选择,引入了额外的计算开销 。
方法
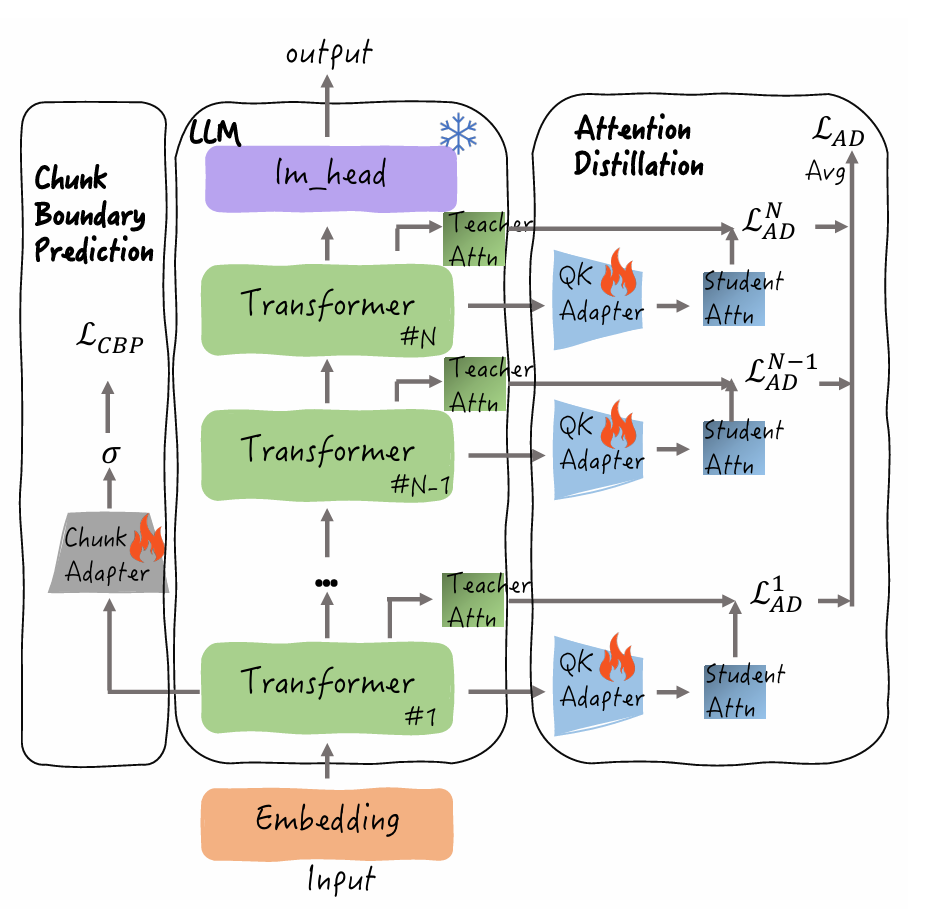
chunk adapter
用来检测一个Token是否为块的边界。
它连接在模型的第一个Transformer层的输出上 。
$$
\hat{y}_i = \begin{cases}
1, & \text{Sigmoid}(\text{FFN}(\mathbf{H}_i^{l_1})) > \alpha, \\
0, & \text{otherwise}
\end{cases}
$$
Chunk Adapter使用pySBD工具(一个基于规则的句子边界检测工具)对训练数据进行预处理,自动标注出”块”的边界作为标签 。
QK Adapter
使用知识蒸馏来让”块”级别的注意力分数尽可能接近于原始LLM的完整注意力分数。
推理
作者发现了一个现象,命名为”块内注意力一致性”(Intra-Chunk Attention Consistency,ICAC)。
这意味着:在同一个语义块中生成的token,它们倾向于关注(Attend to)同一组历史块 。
ICAC 使得在分块选择中节省计算成本成为可能。作者将分块边界预测任务融入推理阶段。仅当当前解码的 token 是分块边界时,才更新分块选择,并将预测阶段得到的完整分块整合到 K 和 V;否则,不执行任何更新。
Top-k 块选择与投票:
- 当触发”块选择”时,每一层的QK Adapter会计算出当前token对所有历史”块”的注意力分数,并选出各自的Top-k个关键块 。
- 为了整合多层的信息,作者提出了一个块投票机制(Chunk Voting Mechanism),对所有层选出的Top-k块进行投票,得出一个全局的Top-k列表 。
- 只有这些被选中的全局Top-k块的KV缓存会被保留和用于后续计算 。
实验
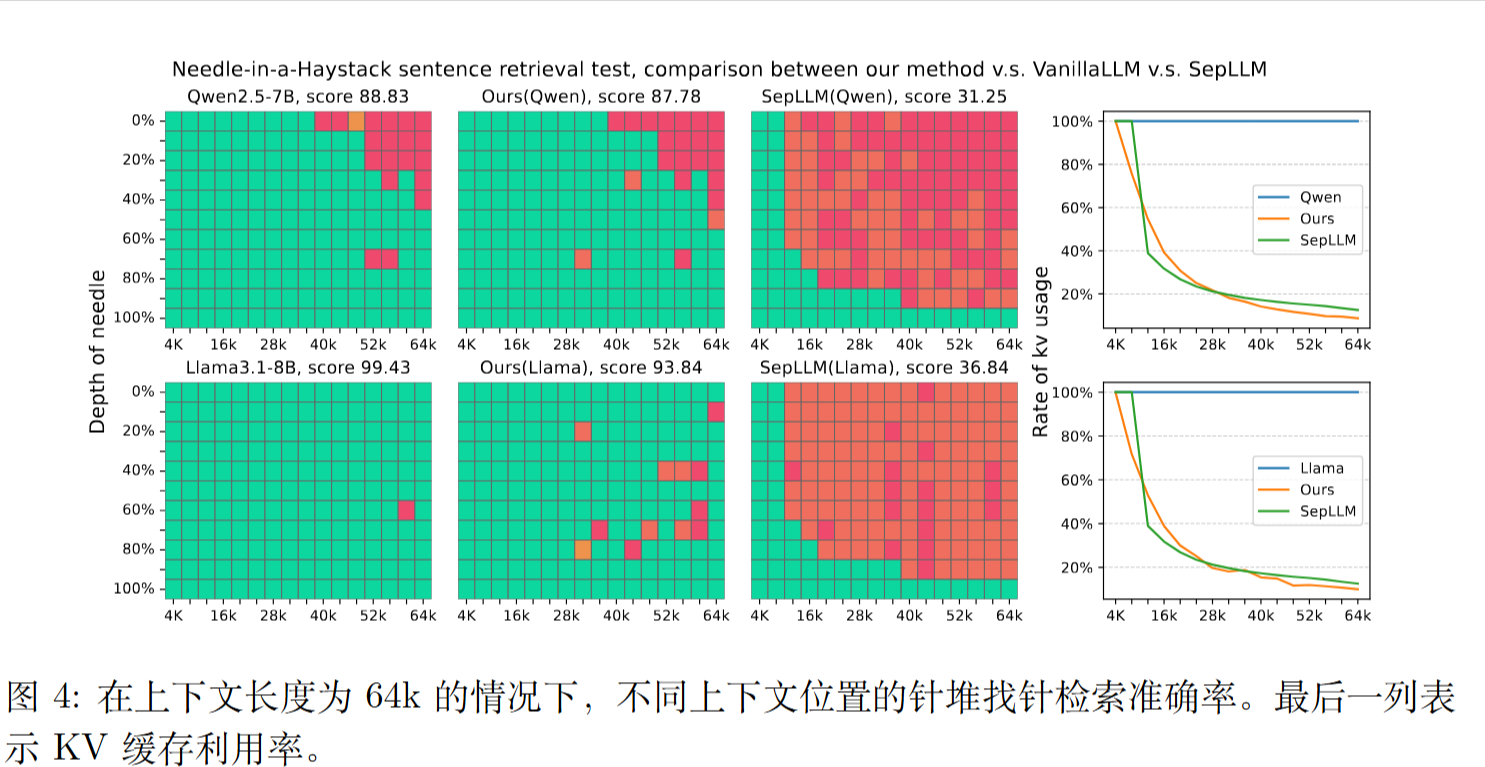
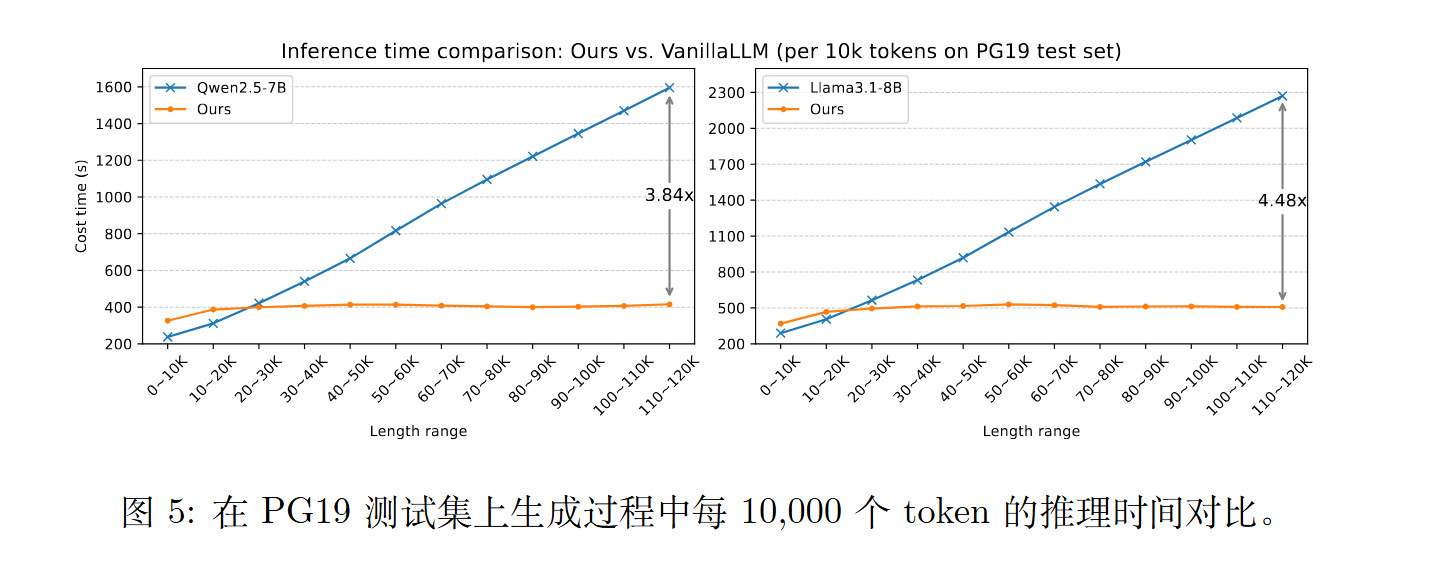
ChunkLLM:A Lightweight Pluggable Framework for Accelerating LLMs Inference
https://lijianxiong.space/2025/20251026/