RoseLoRA:面向知识编辑与微调的预训练语言模型行与列稀疏低秩适配
(EMNLP 2024)
动机
参数高效微调 (PEFT)是比较流行的微调方法,其中最流行的是 LoRA (Low-rank Adaptation) 。LoRA的原理是在模型的权重矩阵 $W^o$ 上,额外学习两个低秩矩阵 $B$ 和 $A$($W = W^o + BA$),微调时只训练 $B$ 和 $A$ 。
虽然B、A的参数很少,但是BA是一个稠密矩阵。这在知识编辑中是致命的。(因为知识编辑的目标是精确地修改模型内部的某个特定知识(例如,“法国的首都是巴黎”),同时必须保持所有其他知识不变 。)
LoRA的稠密更新使得选择性修改变得非常困难。
故RoseLoRA的目标是寻找一种PEFT方法,既能高效微调,又能实现稀疏更新。
方法
实现稀疏更新(即让 $BA$ 稀疏)面临两大挑战:
1.直接$||BA||_0$约束是NP-hard问题。
2.A和B系数≠BA稀疏。

创新方案
RoseLoRA采用的方案是强制$A$ 矩阵的每一行 (row-wise) 和$B$矩阵的每一列(column-wise)保持稀疏。
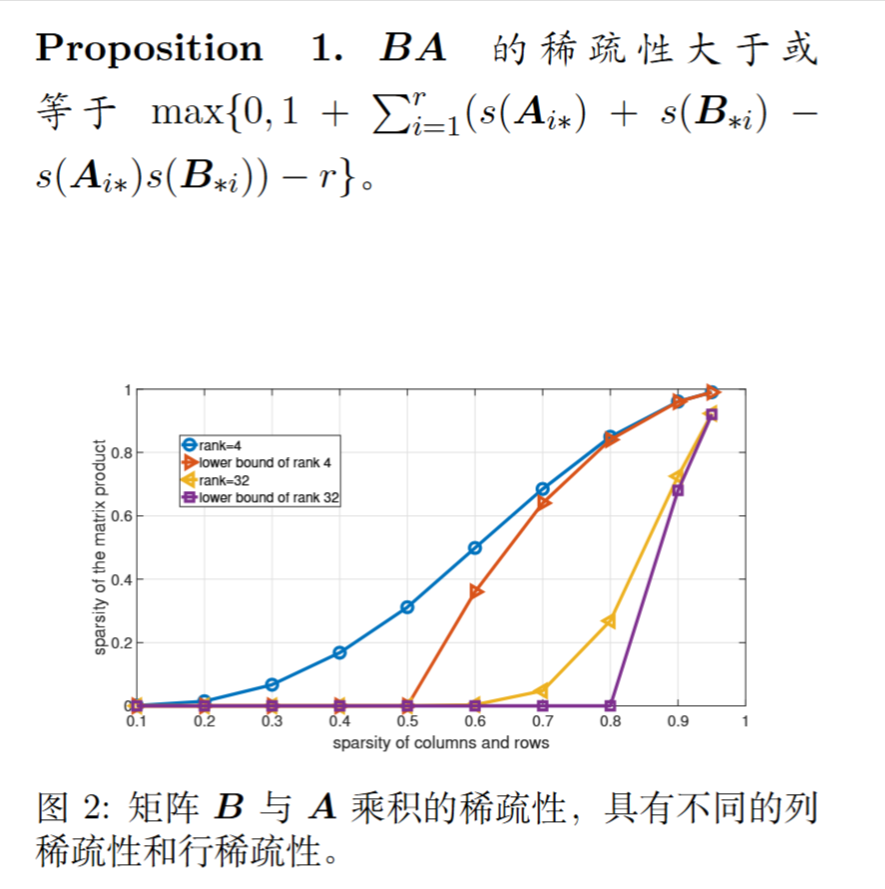
论文从理论上证明了,通过约束 $A$ 的行和 $B$ 的列的稀疏度,可以为最终乘积 $BA$ 的稀疏度提供一个数学上的下限保证。这意味着只要控制了 $A$ 的行和 $B$ 的列,就必然能得到一个稀疏的 $BA$ 更新。
具体方法
重要性评分(敏感度):它使用“敏感度”(Sensitivity)来评估每个参数的重要性。一个参数的敏感度被定义为其权重的绝对值与梯度的绝对值的乘积 ($I = |W \cdot \nabla\mathcal{L}|$) 。这个分数反映了如果将该参数设为零,会对模型的损失产生多大影响 。
迭代剪枝:在训练的每一步中,RoseLoRA会对于 $A$ 的每一行和 $B$ 的每一列,剪枝掉那些敏感度分数最低(即最不重要)的参数,将它们设为零。
稀疏预算:剪枝的比例(稀疏度)会随着训练的进行而逐渐增加,直到达到最终的目标稀疏度 。
$$
\tau^{(t)} = \begin{cases} 1, & t \le t_i \\ \tau + (1-\tau)(1 - \frac{t - t_i}{t_f - t_i})^3, & t_i < t \le t_f \\ \tau, & t_f < t \le T \end{cases}
$$