Kaggle Grandmasters playbook:7 种经过实战考验的表格数据建模技术
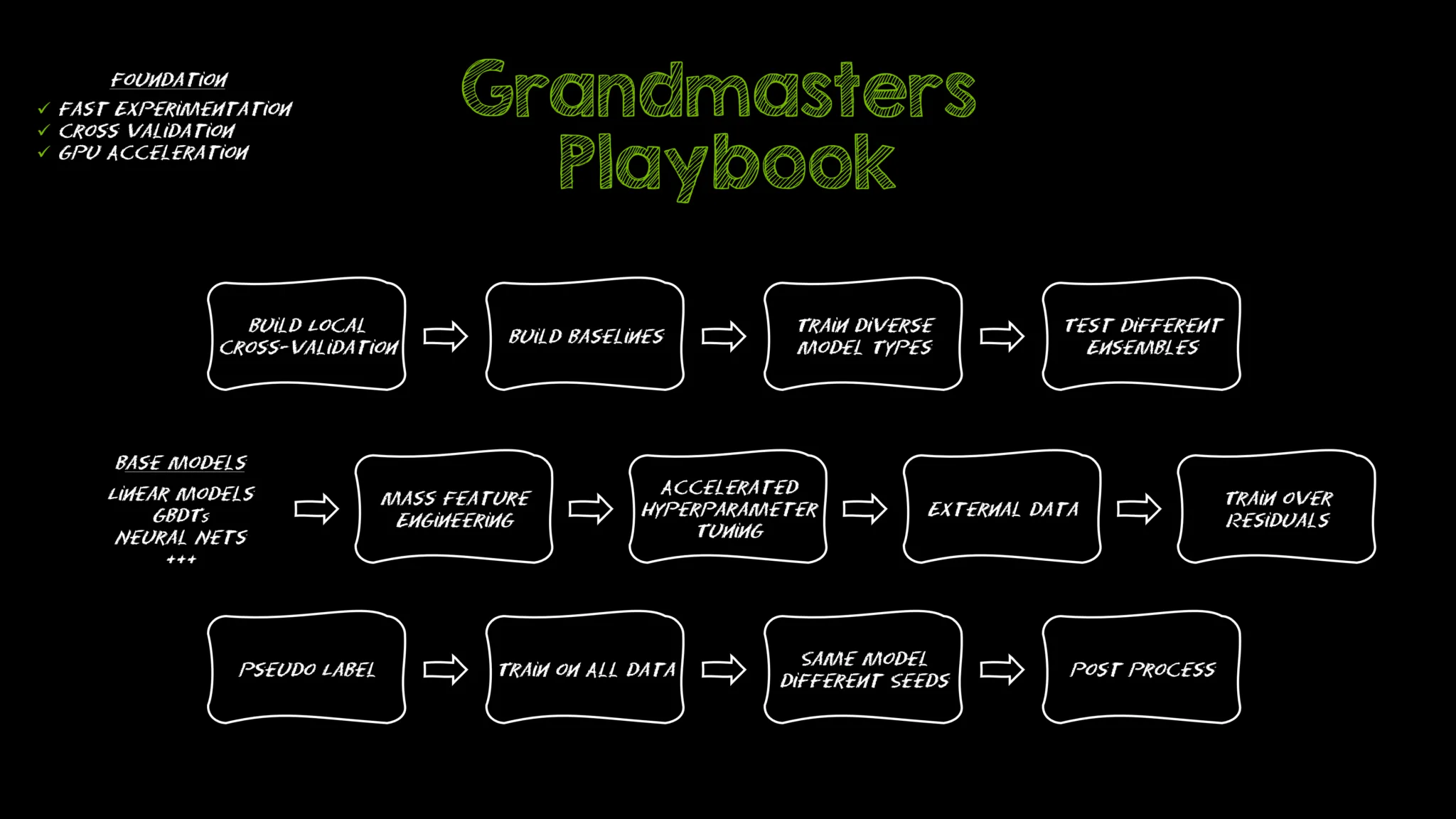
在数百场 Kaggle 比赛中,我们改进了一本剧本(playbook),使我们始终接近排行榜的榜首——无论我们处理的是数百万行、缺失值还是行为与训练数据完全不同的测试集。这不仅仅是建模技巧的集合,它还是一个可重复的系统,用于快速解决现实世界的表格问题。
以下是我们经过实战考验的七种技术,每一种技术都通过 GPU 加速变得实用。无论您是攀登排行榜还是在生产中部署模型,这些策略都可以为您带来优势。
我们提供了指向每种技术过去比赛的示例文章或笔记本的链接。
**注意:**Kaggle 和 Google Colab 笔记本电脑附带免费的 GPU 和加速插入式,就像您将在下面预装的那样。
核心原则:制胜工作流程的基础
在深入研究技术之前,值得暂停一下,介绍一下为本手册中的所有内容提供动力的两个原则:快速实验和仔细验证。这些不是可选的最佳实践,它们是我们处理每个表格建模问题的基础。
快速实验
在任何比赛或实际项目中,我们最大的杠杆是我们可以运行的高质量实验的数量。迭代次数越多,发现的模式就越多,当模型失败、漂移或过度拟合时,我们就能更快地发现,因此我们可以及早纠正方向并更快地改进。
在实践中,这意味着我们优化了整个管道的速度,而不仅仅是我们的模型训练步骤。
以下是我们如何使其发挥作用:
- 使用 pandas 或 Polars 的 GPU 插入式替换来加速数据帧作,以大规模转换和设计功能。
- 使用 NVIDIA cuML 或 XGBoost、LightGBM 和 CatBoost 的 GPU 后端训练模型。
GPU 加速不仅适用于深度学习,而且通常是使高级表格技术大规模实用的唯一方法。
本地验证
如果你不能相信你的验证分数,你就是盲目飞行。这就是为什么交叉验证 (CV) 是我们工作流程的基石。
我们的方法:
- 使用 k 折交叉验证,其中模型对大部分数据进行训练,并在保留的部分上进行测试。
- 旋转折叠,以便数据的每个部分都经过一次测试。
这提供了比单个训练/验证拆分更可靠的性能衡量标准。
专业提示: 将您的简历策略与测试数据的结构相匹配。
例如:
- 将 TimeSeriesSplit 用于与时间相关的数据
- 将 GroupKFold 用于分组数据(如用户或患者)
有了这些基础——快速行动并仔细验证——我们现在可以深入研究技术本身。每一个都建立在这些原则之上,并展示了我们如何将原始数据转化为世界一流的模型。
1. 从更智能的 EDA 开始,而不仅仅是基础知识
大多数从业者都知道基础知识:检查缺失值、异常值、相关性和特征范围。这些步骤很重要,但它们是赌注。要构建在现实世界中经得起考验的模型,您需要更深入地探索数据 - 我们发现一些有用的快速检查,但许多人忽略了:
训练与测试分布检查: 发现评估数据与训练何时不同,因为分布偏移可能会导致模型验证良好,但在部署中失败。
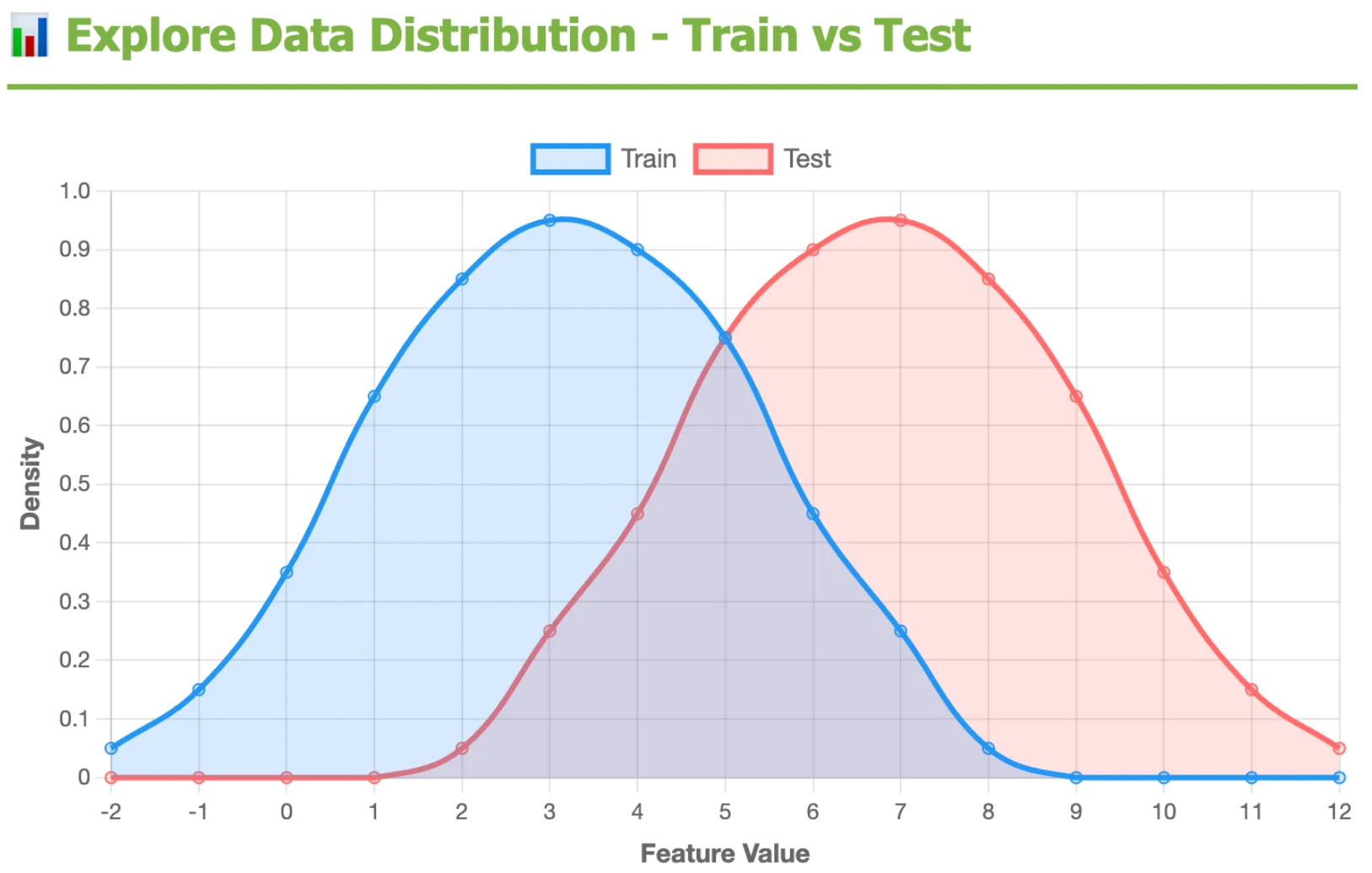
上图比较训练(蓝色)和测试(红色)之间的特征分布可以发现明显的转变——测试数据集中在更高的范围内,重叠最小。这种分布转移可能会导致模型验证良好,但在部署中失败。
分析目标变量的时间模式: 检查趋势或季节性,因为忽略时间模式可能会导致模型在训练中看起来准确,但在生产中中断。
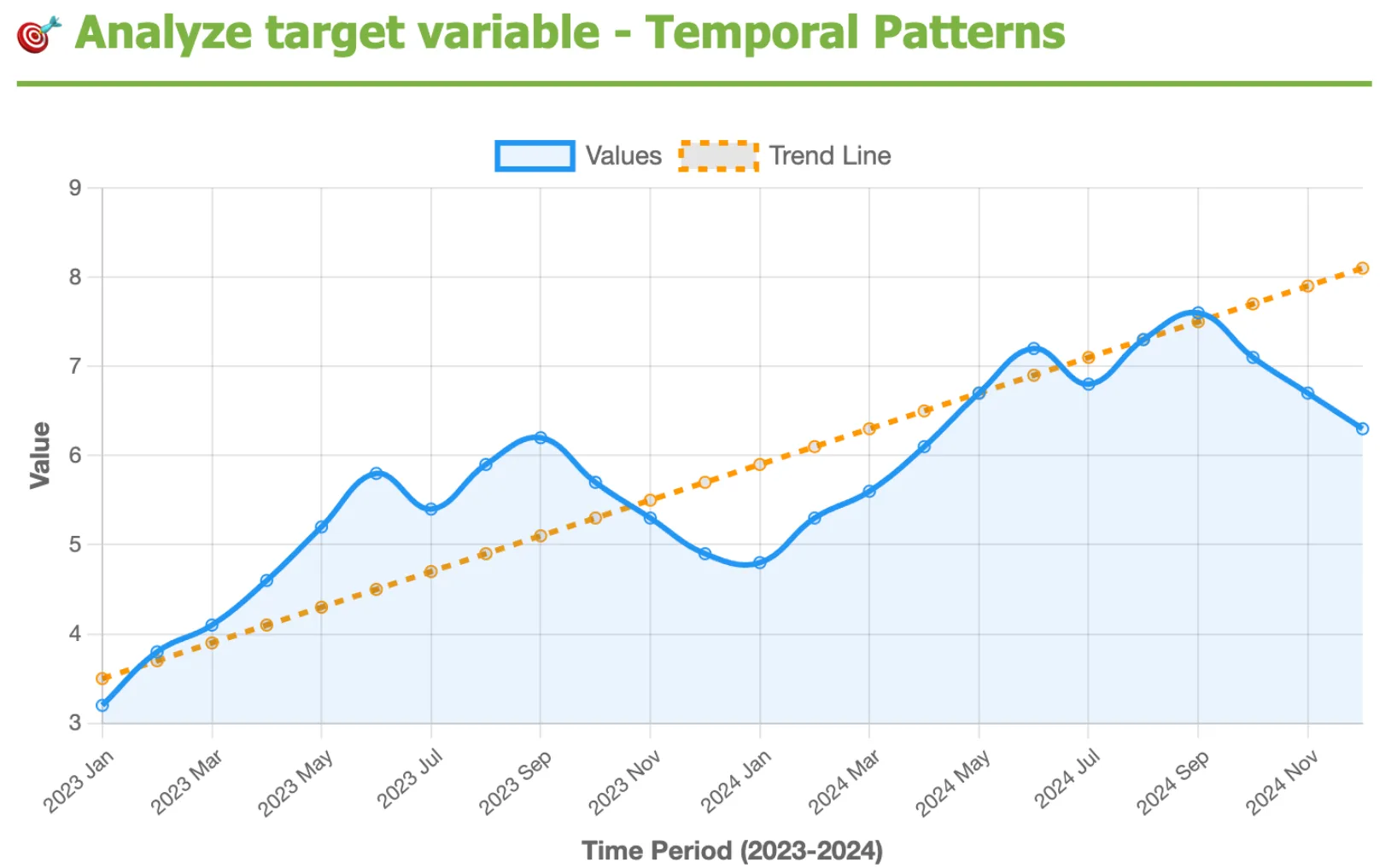
随着时间的推移分析目标变量,可以发现季节性波动和加速增长的强劲上升趋势。忽略此类时间模式可能会误导模型,除非使用时间感知验证。
这些技术并不新鲜,但它们经常被忽视,忽视它们可能会使项目沉沦。
为什么重要: 跳过这些检查可能会破坏原本可靠的工作流程。
在行动中: 在 Amazon KDD Cup ‘23 的获胜解决方案中,该团队发现了测试分布偏移和目标时间模式的列车——这些见解塑造了最终方法。 阅读全文 >
使用 GPU 变得实用: 现实世界的数据集通常是数百万行,这在 pandas 中可能会变慢。通过使用 NVIDIA cuDF 添加 GPU 加速,您可以在几秒钟内大规模运行分布比较和相关性。 阅读技术博客 >
2. 快速构建多样化的基线
大多数人构建一些简单的基线(可能是均值预测、逻辑回归或快速 XGBoost),然后继续。问题在于,单个基线并不能告诉您太多有关数据格局的信息。
我们的方法不同: 我们立即跨模型类型启动一组不同的基线。了解线性模型、GBDT 甚至小型神经网络如何并排执行,为我们提供了更多的背景信息来指导实验。
为什么重要: 基线是您的直觉检查——它们确认您的模型比猜测做得更好,设置最低性能标准,并充当快速反馈循环。在数据更改后重新运行基线可以揭示您是否取得了进展,或者发现泄漏等问题。
多样化的基线还可以尽早显示哪些模型族最适合您的数据,因此您可以加倍努力,而不是在错误的路径上浪费周期。
在行动中: 在降雨数据集二元预测竞赛中,我们的任务是根据天气数据预测降雨量。我们的基线让我们走得很远——梯度增强树、神经网络和支持向量回归 (SVR) 模型的集合,没有任何特征工程,足以为我们赢得第二名。在探索其他基线时,我们发现即使是单个支持向量分类器 (SVC) 基线也会位于排行榜顶部附近。 阅读全文 >
使用 GPU 变得实用: 在 CPU 上训练各种模型可能会非常慢。借助 GPU 加速,您可以尝试所有这些方法(用于快速统计的 cuDF、用于线性/逻辑回归的 cuML,以及 GPU 加速的 XGBoost、LightGBM、CatBoost 和神经网络),因此您可以在几分钟内获得更好的洞察力,而不是几小时。
3. 生成更多特征,发现更多模式
特征工程仍然是提高表格数据准确性的最有效方法之一。挑战:在 CPU 上使用 pandas 生成和验证数千个特征太慢,不切实际。
为什么重要: 从少数手动转换扩展到数百或数千个工程特征,通常会揭示仅靠模型无法捕获的隐藏信号。
例: 组合分类列
在一次 Kaggle 竞赛中,数据集有八个分类列。通过组合它们对,我们创建了 28 个新的分类特征,这些特征捕获了原始数据未显示的交互。以下是该方法的简化片段:
1 | |
在行动中: 大规模功能工程推动了 Kaggle Backpack 和 Insurance 竞赛的第一名,数以千计的新功能发挥了作用。
使用 GPU 变得实用: 借助 cuDF,panda 作(如分组、聚合和编码)的运行速度提高了几个数量级,从而可以在几天而不是几个月内生成和测试数千个新功能。
查看下面的技术博客和培训课程,了解实践示例:
组合不同的模型(集成)可提高性能
我们发现,结合不同模型的优势通常会使性能超出任何一种模型所能达到的范围。两种特别有用的技术是爬山和模型堆叠。
4. 爬山
爬山是一种简单但强大的模特组合方式。从最强的单个模型开始,然后系统地添加具有不同权重的其他模型,仅保留可改善验证的组合。重复直到没有进一步的收益。
为什么重要: 集成可以捕捉模型之间的互补优势,但很难找到正确的组合。爬山可以自动执行搜索,通常会降低准确性并优于单一模型解决方案。
在行动中: 在预测卡路里消耗竞赛中,我们使用了 XGBoost、CatBoost、神经网络和线性模型的爬山集成来获得第一名。 阅读写入 >
使用 GPU 变得实用: 爬山本身并不新鲜——它是比赛中常见的合奏技术——但它通常会变得太慢而无法大规模应用。借助 GPU 上的 Cupy,我们可以矢量化度量计算(如 RMSE 或 AUC)并并行评估数千种权重组合。这种加速使得测试比在 CPU 上可行的更多的集成变得实用,通常会发现更强的混合。
以下是用于在 GPU 上评估爬山合奏的代码的简化版本:
1 | |
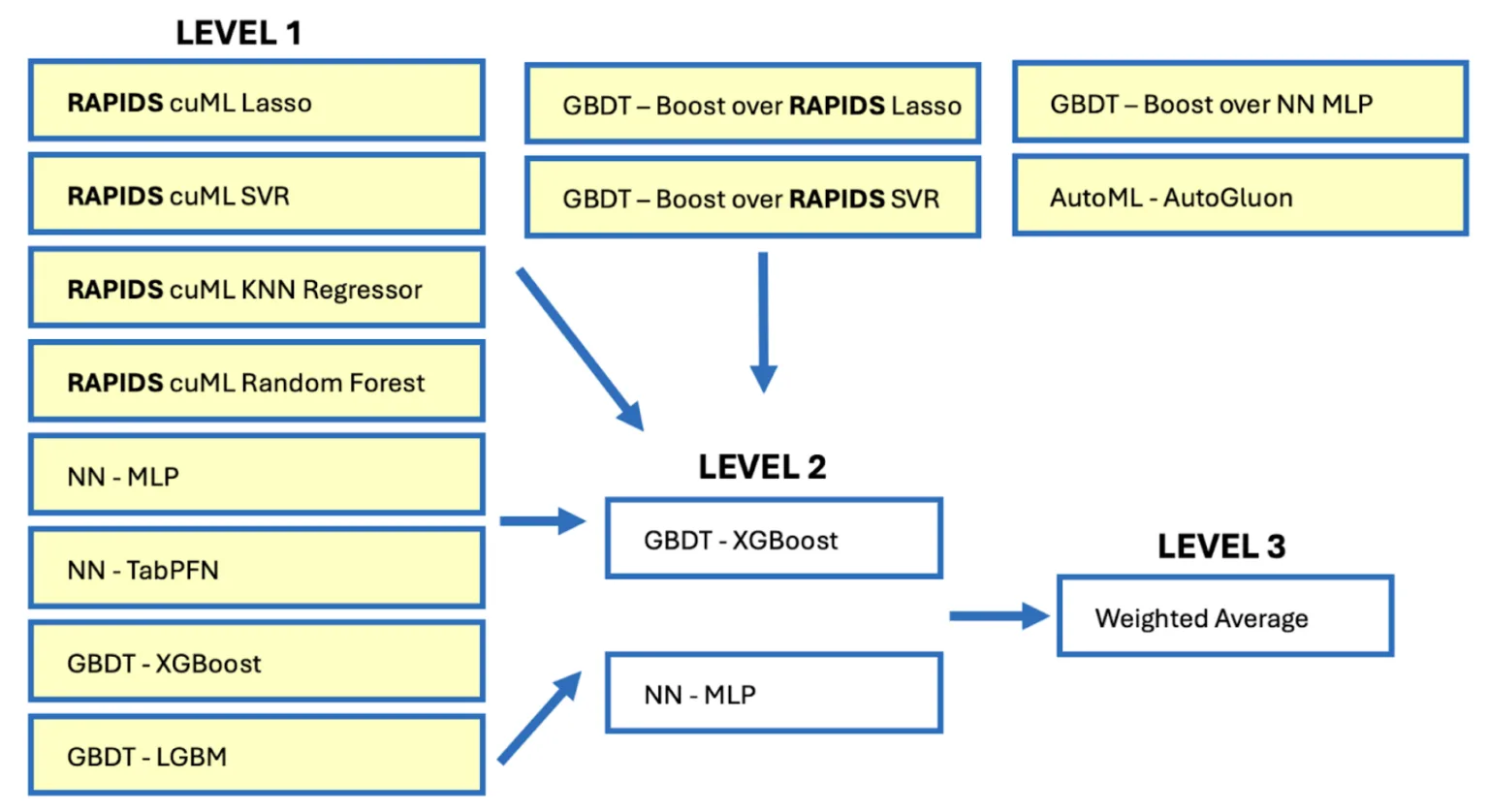
5. 堆叠
堆叠通过在另一个模型的输出上训练一个模型,使集成更进一步。堆叠不是用权重(如爬山)对预测进行平均,而是构建一个二级模型,该模型学习如何最好地组合其他模型的输出。
为什么重要: 当数据集具有不同模型以不同方式捕获的复杂模式时,堆叠尤其有效,例如线性趋势与非线互。
专业提示: 两种堆叠方式:
- 残差:根据第 1 阶段出错的地方(残差)训练第 2 阶段模型。
- OOF 功能:使用阶段 1 预测作为阶段 2 的新输入功能。
这两种方法都有助于通过捕获基础模型遗漏的模式从数据中挤出更多信号。
在行动中: 堆叠被用于在播客收听时间竞赛中赢得第一名,该竞赛使用了不同模型(线性、GBDT、神经网络和 AutoML)的三级堆栈。 阅读技术博客 >
6. 将未标记的数据转换为具有伪标记的训练信号
伪标记将未标记的数据转换为训练信号。您可以使用最佳模型在缺少标签的数据(例如,测试数据或外部数据集)上推断标签,然后将这些“伪标签”折叠回训练中以提高模型性能。
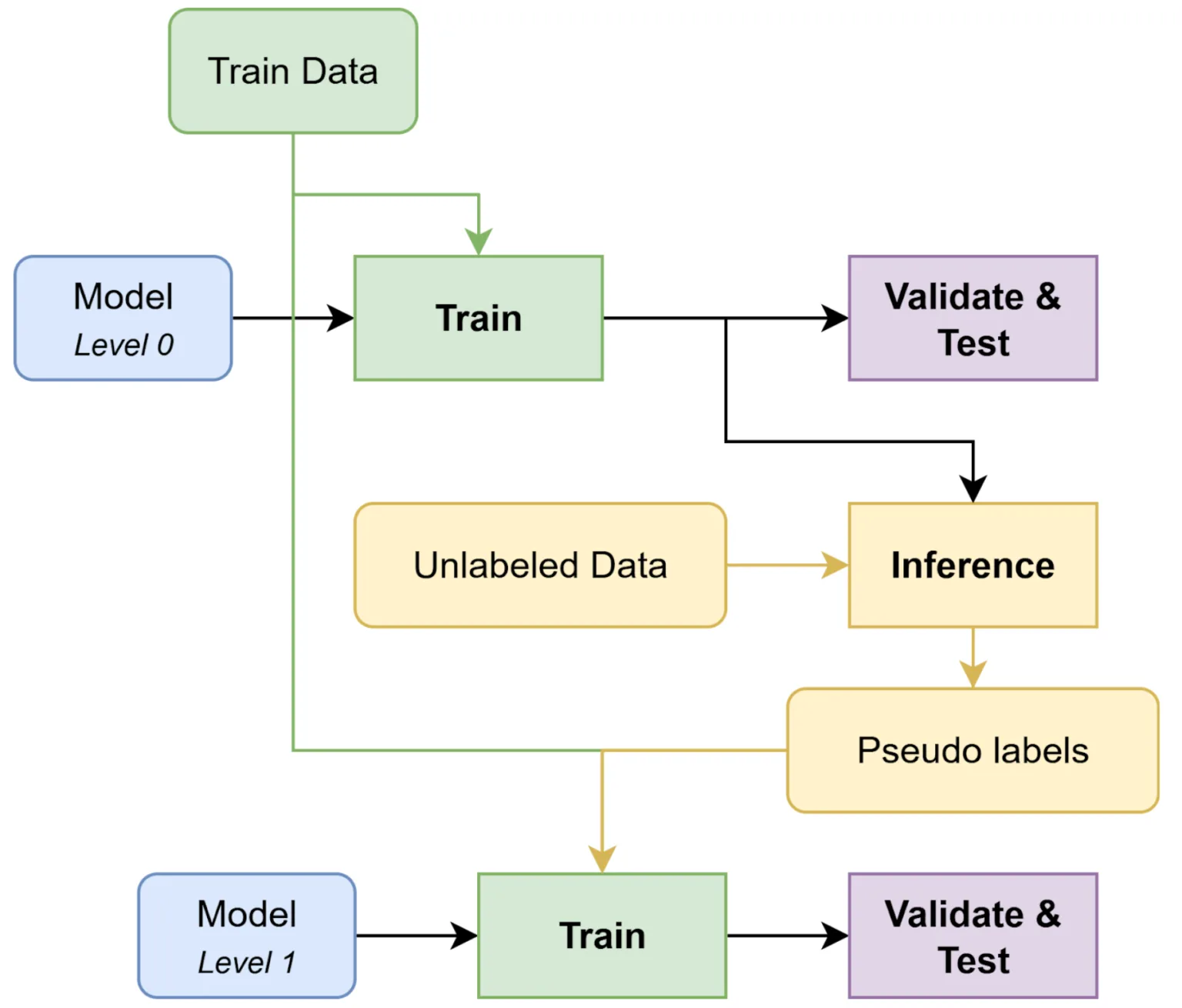
伪标记将未标记的数据转换为训练信号。您可以使用最佳模型在缺少标签的数据(例如,测试数据或外部数据集)上推断标签,然后将这些“伪标签”折叠回训练中以提高模型性能。
为什么重要: 更多数据 = 更多信号。伪标记提高了鲁棒性,起到了知识蒸馏的作用(学生模型从强有力的教师的预测中学习),甚至可以通过过滤掉模型不同意的样本来帮助去噪标记的数据。使用软标签 (概率而不是硬 0/1)可以增加正则化并减少噪声。
有效伪标签的专业技巧:
- 模型越强,伪标签越好。集成或多轮伪标记通常优于单程方法
- 伪标签也可用于预训练。作为最后一步,对初始数据进行微调,以减少之前引入的噪声。
- 使用软伪标签。它们可以增加更多信号,降低噪声,并让您滤除低置信度样本。
- 伪标记可用于标记数据,可用于去除有噪声的样品。
- 避免信息泄露。使用 k 折时,必须计算 k 组伪标签,以便验证数据永远不会看到来自自身训练的模型的标签。
在行动中: 在 BirdCLEF 2024 比赛中,任务是根据鸟类录音对物种进行分类。伪标记在未标记的剪辑上使用软标签扩展了训练集,这有助于我们的模型更好地泛化到新物种和记录条件。 阅读全文 >
使用 GPU 变得实用: 伪标记通常需要多次重新训练管道(基线 > 伪标记 > 改进的伪标签)。这在 CPU 上可能需要数天时间,使得迭代不切实际。通过 GPU 加速(通过 cuML、XGBoost 或 CatBoost GPU 后端),您可以在数小时内运行多个伪标记周期。
7. 通过额外培训加强您的最终模型
即使在优化了我们的模型和整体之后,我们也发现了两个可以挤出额外性能的最终调整:
- 使用不同的随机种子进行训练 。更改初始化和训练路径,然后对预测进行平均,通常可以提高性能。
- 对 100% 的数据进行重新训练 。找到最佳超参数后,将最终模型拟合到所有训练数据上会挤出额外的准确性。
为什么重要: 这些步骤不需要新的架构,只需对您已经信任的模型进行更多运行即可。它们共同提高了稳健性并确保您充分利用数据。
在行动中: 在预测最佳肥料挑战中,对 100 种不同种子进行集成 XGBoost 模型明显优于单种子训练。对完整数据集进行重新训练提供了另一个排行榜提升。 阅读全文 >
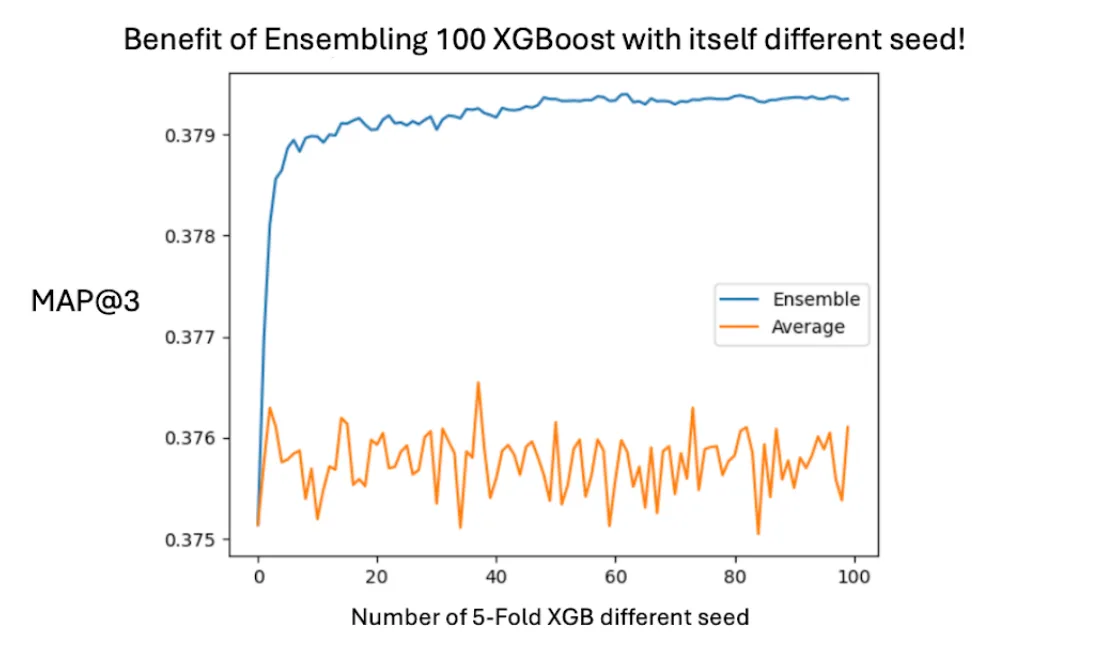
使用 GPU 变得实用: 在 GPU 上更快的训练和推理使得多次重新运行模型成为可能。在 CPU 上可能需要数天的时间在 GPU 上变成数小时——将“额外”训练变成每个项目的现实步骤。
总结:特级大师赛的战术手册
这本剧本经过实战考验,是经过多年的比赛和无数实验锻造而成的。它基于两个原则——快速实验和仔细验证——我们把这些原则应用于每个项目。借助 GPU 加速,这些先进技术变得大规模实用,使其对于现实世界的表格问题和攀登排行榜同样有效。
如果您想将这些想法付诸实践,这里有一些资源可以帮助您在已经使用的工具中开始使用 GPU 加速:
- Intro Notebook:使用 cuDF 加速 pandas(pandas 工作流程的零代码更改加速)
- Intro Notebook:使用 cuML 加速 scikit-learn(常见 ML 模型的直接加速)
- 入门笔记本:GPU 加速的 XGBoost(在几分钟内训练数百万行上的梯度提升树)
- NVIDIA cuDF 概述 :了解有关加速 pandas 和 Polars 的更多信息。
- NVIDIA cuML 概述 :具有 GPU 加速的 Scikit 学习式机器学习。