五篇幻觉相关论文速览(二)
师兄组会所提到。
2506.04039
2509.21997
https://aclanthology.org/2025.naacl-long.75.pdf
2505.24007
2503.13107
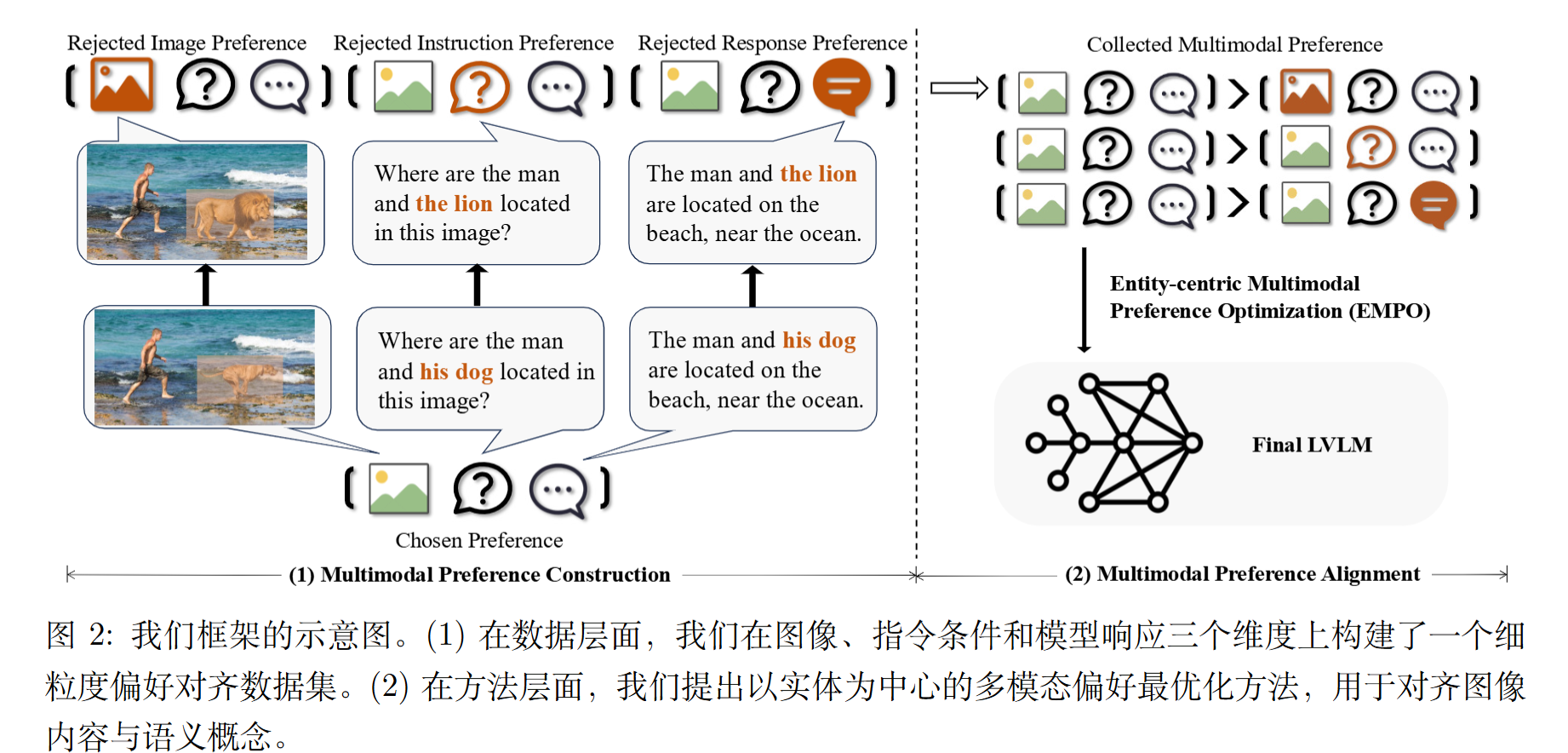
通过以实体为中心的多模态偏好最优化缓解大型视觉-语言模型中的幻觉问题
(开源仓库为空) EMNLP2025 Mitigating Hallucinations in Large Vision-Language Models via Entity-Centric Multimodal Preference Optimization
模态错位(Modality Misalignment):视觉编码器与 LLM 语义不对齐(如把“禁止机动车”错识为“禁止停车”)。
语言内生幻觉(LLM Inherent Hallucination):LLM 根据训练共现(如“road”常伴“car”)臆造不存在实体。

为了构建被拒绝的图像,作者首先使用 GPT 4o-mini识别指令和响应中的实体,确保编辑后的图
像与文本紧密对齐。
随后使用目标检测模型定位这些实体。接着,应用 Stable-diffusion-2 来移除 30% 的实体或用视觉上合理的替代品替换它们,从而生成一个作为被拒绝样本的编辑图像 $v_l$。
最后,使用 CLIP计算编辑后图像区域与实体标签之间的相似度,以确保图像已正确编辑。
对齐人类偏好包含三个层面:图像、指令和响应。
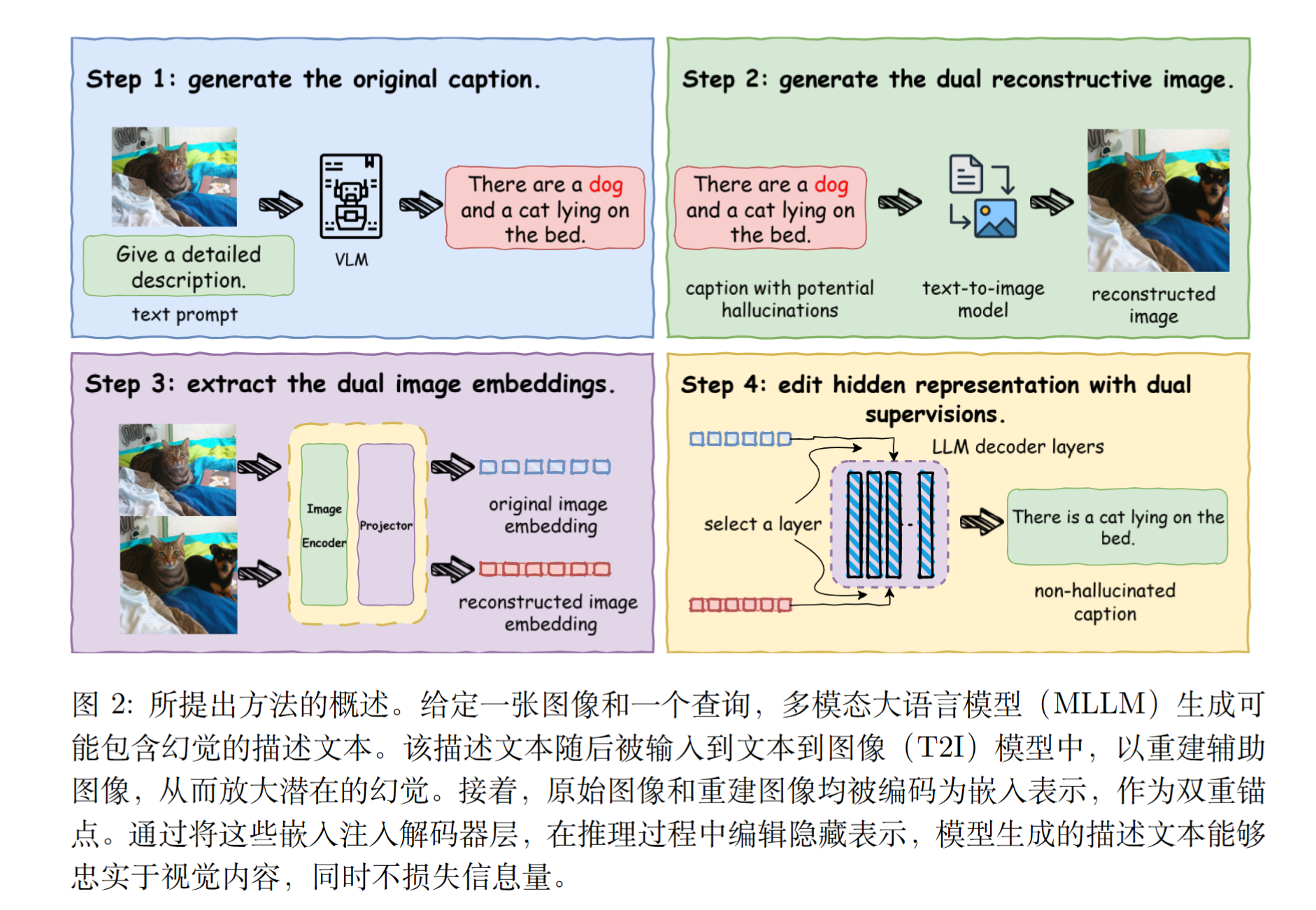
暴露幻觉以抑制幻觉:基于生成锚点的 VLMs 表示编辑
EXPOSING HALLUCINATIONS TO SUPPRESS THEM: VLMSREPRESENTATION EDITING WITH GENERATIVE ANCHORS
贡献:
1)提出了一种无需训练的自监督方法,用于缓解多模态大模型中的幻觉问题。通过直接从模型自身输出中获取监督信号,以完全端到端且即插即用的方式运行。
2)引入了一种新颖的幻觉放大机制,利用 T2I 模型将字幕语义投影到视觉空间中。这使得原本隐式的幻觉变得可观测,并提供了一种轻量级的方法来构建可靠的监督信号。
3)同时锚定原始图像中的语义,并抑制重构图像中的幻觉方向。这种双重引导仅去除幻觉成分,同时保留真实语义,实现了忠实性与信息丰富性之间的平衡。
4)实验结果表明,显著优于现有方法。
方法
概述
给定一张输入图像,使用视觉语言模型(VLM)生成一个初始描述,该描述可能包含幻觉对象或关系。为了揭示描述中潜在的幻觉内容,基于描述使用文本到图像(T2I)模型合成一张重构图像。
这种重构能够自然地将幻觉内容放大并外化到视觉空间中。
因此,原本在文本语义空间中隐含且难以检测的幻觉,在投影到图像后变得可感知。原始图像和重构图像均通过图像编码器和投影头,获得嵌入表示,分别记为 f (I) 和 f (I′)。
其中,f (I) 作为干净的语义锚点,引导表示向忠实的视觉语义方向发展;而 f (I′) 则显式捕捉通过重构放大的幻觉方向。通过同时将图像 token 嵌入拉向 f (I) 并推离 f (I′),的方法建立了一种对抗性修正机制,无需手工设计的度量指标或外部监督。
因此,该设计将幻觉抑制转化为完全自监督的过程,实现了无需人工干预的端到端修正。
潜在表示编辑
$$
K’ _ {h,l}=K _ {h,l}+\alpha f(I)-\beta f(I’),h\in \mathcal{H} _ {img},l\in[1,L]
$$
K表示嵌入。
f (·) 表示图像编码器与投影器的联合变换。
没有代码,不知道联合变换和$\alpha$是啥
通过图像标记注意力引导解码减轻多模态大型语言模型的幻觉
ACL
Mitigating Hallucinations in Multi-modal Large Language Models via Image Token Attention-Guided Decoding
抢占式幻觉减少:一种用于多模态语言 模型的输入级方法
An Input-Level Approach for Multimodal Language Model
准备三种图像变体:
原始图像 (org):未作任何处理的图片 。
降噪图像 (NR):使用中值滤波技术去除图像中的噪点,同时保留边缘清晰度 。
边缘增强图像 (EE):使用拉普拉斯算子增强图像的边缘和细节 。
模型生成答案:
将同一个问题分别与这三种图像变体配对,输入给大语言模型(本文使用的是 GPT-3.5),从而得到三个不同的答案 。
评估与选择:
使用一个名为 SelfCheckGPT 的评估工具,通过计算 自然语言推理 (NLI) 分数 来判断哪个答案与“基准答案 (Ground Truth)”最一致 。NLI 分数越低,表示幻觉程度越低,答案越可靠 。最终,选择NLI分数最低的那个答案作为最终输出 。
NLI分数:
NLI 的任务是判断“前提”是否能推导出“假设”。在幻觉检测的场景下,“前提”是模型生成的多个参考回答中的一个样本 ($S^n$),而“假设”是当前正在被评估的句子 ($r_i$)。
计算过程主要关注两个逻辑类别:“蕴含 (entailment)”和“矛盾 (contradiction)”。
计算单个句子与单个样本的矛盾概率:
这个概率的计算公式如下:$$P(contradict | r_i, S^n) = \frac{\exp(z_c)}{\exp(z_e) + \exp(z_c)}$$
- $P(contradict | r_i, S^n)$:代表在给定一个参考样本 $S^n$ 的情况下,句子 $r_i$ 被判定为“矛盾”的概率。
- $z_c$ 和 $z_e$:分别代表 NLI 模型输出的“矛盾”和“蕴含”这两个类别的原始得分(logits)。
- $\exp()$:是指数函数,通常在多分类问题中与 Softmax 函数结合使用,用于将原始得分转换为概率。
- 这个公式的特点是它忽略了“中性”类别,只在“蕴含”和“矛盾”之间进行归一化,确保概率值在 0.0 到 1.0 之间。
计算最终的 NLI 分数 (SelfCheckGPT Score):
为了得到一个更可靠的分数,模型会生成 N 个不同的参考样本 ($S^n$),然后计算待评估句子 $r_i$ 与所有这些样本的平均矛盾概率。最终的 NLI 分数由以下公式得出:$$S_{NLI}(i) = \frac{1}{N} \sum_{n=1}^{N} P(contradict | r_i, S^n)$$
- $S_{NLI}(i)$:就是句子 $r_i$ 的最终 NLI 分数。
- $N$:是生成的参考样本的总数。
- $\sum_{n=1}^{N}$:表示将句子 $r_i$ 与从 1 到 N 的每一个参考样本计算出的矛盾概率全部加起来。
- $\frac{1}{N}$:表示取平均值。这种对多个样本取平均的做法是为了确保分数的稳定性与可靠性。
ClearSight:面向多模态大语言模型物体幻觉缓解的视觉信号增强技术
CVPR 2025
motivation
ClearSight: Visual Signal Enhancement for Object Hallucination Mitigation in Multimodal Large Language Models
对比解码方法无需训练或依赖外部工具,具备高计算效率与广泛适用性,在学术界引起了极大关注。然而,此类方法仍存在两大不足:生成内容质量下降及推理速度较慢。
利用泰勒展开式计算注意力矩阵中每个元素的显著性得分:
$$
I_l=\left|\sum_h A_{h,l}\odot \frac{\partial \mathcal{L}(x)}{\partial A_{h.l}} \right|
$$
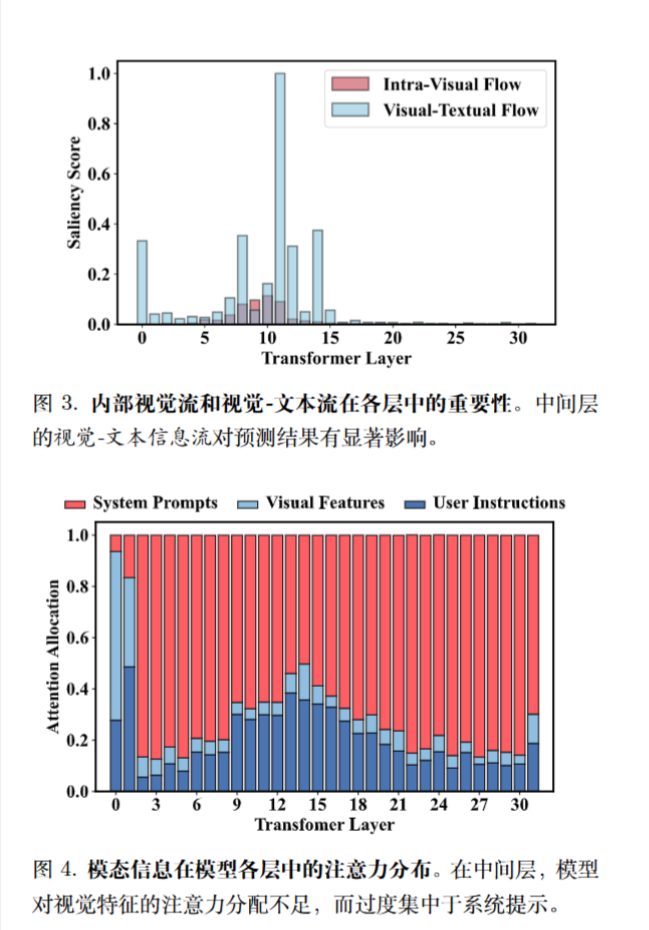
为了更清晰地描绘 MLLMs 中的视觉信息流,基于 $I_l(i, j) $引入了两个定量指标,特别关注涉及图像 token 的信息交互。
$$
\begin{align}
S_{vv}=\frac{\sum_{(i,j)\in C_{vv}}I_l(i,j)}{C_{vv}},C_{vv}=((i,j):i,j\in\mathcal{V},i\ge j)
\\
S_{vt}=\frac{\sum_{(i,j)\in C_{vt}}I_l(i,j)}{C_{vv}},C_{vt}=((i,j):i\in\mathcal{T},j\in\mathcal{V})
\end{align}
$$
方法
基于前面提出的见解,引入了一种称为视觉增强融合(VAF)的幻觉缓解方法。
在中间层(即 8 < l < 15)中修改注意力得分矩阵如下:
