五篇幻觉相关论文速览
师兄组会所提到。
2508.20181,2410.15778,2311.07362,2407.06192,2406.01920
《通过目标感知的偏好优化来缓解多模态大语言模型中的幻觉》
《Mitigating Hallucinations in Multimodal LLMs via Object-aware Preference Optimization》
BMVC 2025(CCF C,17年知乎上都称是略低于CV顶会的第二档会议)
但感觉这篇论文的含金量并不足。
CHAIR-DPO 基于 CHAIR。
$$
CHAIR=\frac{|回答y中提到的、但图像中不存在的物体|}{|回答y中所提到的所有物体|}
$$
本文将缓解幻觉问题视为一个对齐问题,通过训练让模型更“偏爱”那些不含幻觉的回答 。(这不是废话吗)
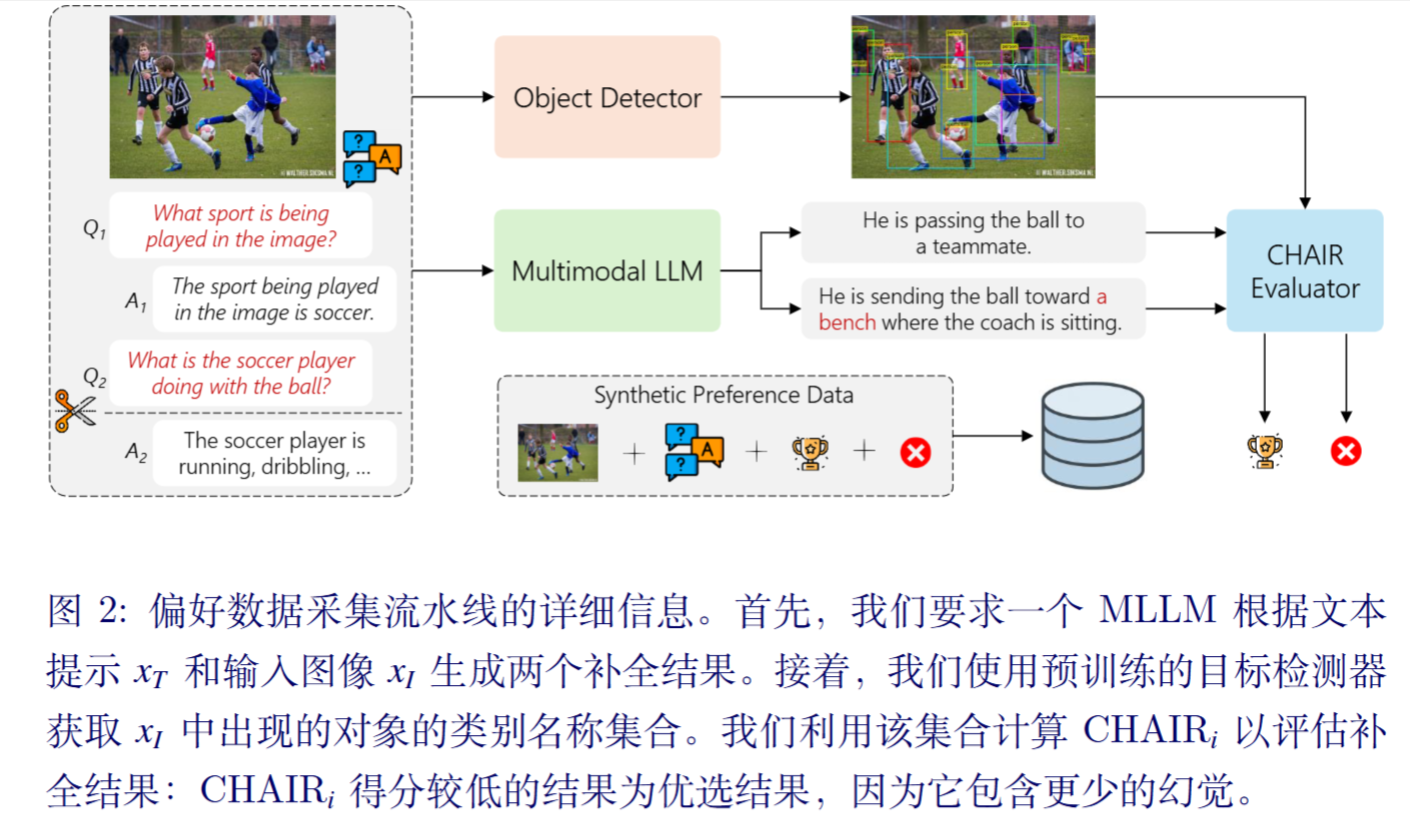
首先,对于数据集中的每个三元组,丢弃 y ,并从参考的指令微调多模态大模型$\pi_{ref}$中采样一组新的可能答案 {y1, y2} 。然后,我们将一个现成的检测器应用于图像$x_I$,该检测器经过训练以识别预定义的一组对象,将检测到的项目类别名称视为图像中实际存在的真实物体集合$x_I$。此时,可以计算生成答案的$CHAIR_i$得分,任何未出现在真实物体集合中的提及对象均被视为幻觉。
然后就是DPO了。
还有作者发现,一个关键挑战源于存在多个完成对的$CHAIR_i$得分无法区分,导致无法分配胜者和败者标签。将此类配对纳入最优化过程会引入噪声监督,因为模型被迫从随机选择的偏好标签中学习。为解决此问题,我们提出一种简单而有效的过滤策略:我们丢弃所有完成对之间$CHAIR_i$得分差为零的训练实例。
通过潜在空间引导减少视觉-语言模型中的幻觉
Reducing Hallucinations in Vision-Language Models via Latent Space Steering
ICLR 2025 Spotlight
代码:shengliu66/VTI: Code for Reducing Hallucinations in Vision-Language Models via Latent Space Steering
Visual and Textual Intervention = VTI
LVLMs 中的幻觉机制
幻觉可能源于对视觉编码器不稳定性的敏感性。
与计算机视觉中的传统神经网络类似,理想的视觉编码器应在图像语义保持不变时输出稳定的特征,例如在对图像进行轻微扰动后。这种情况在 LVLMs 中尤为突出,其中图像编码器和文本解码器是预训练分离的,并且仅进行了最小程度的联合微调。文本解码器对图像特征的敏感性可能会加剧两种模态之间的错位,从而导致幻觉。
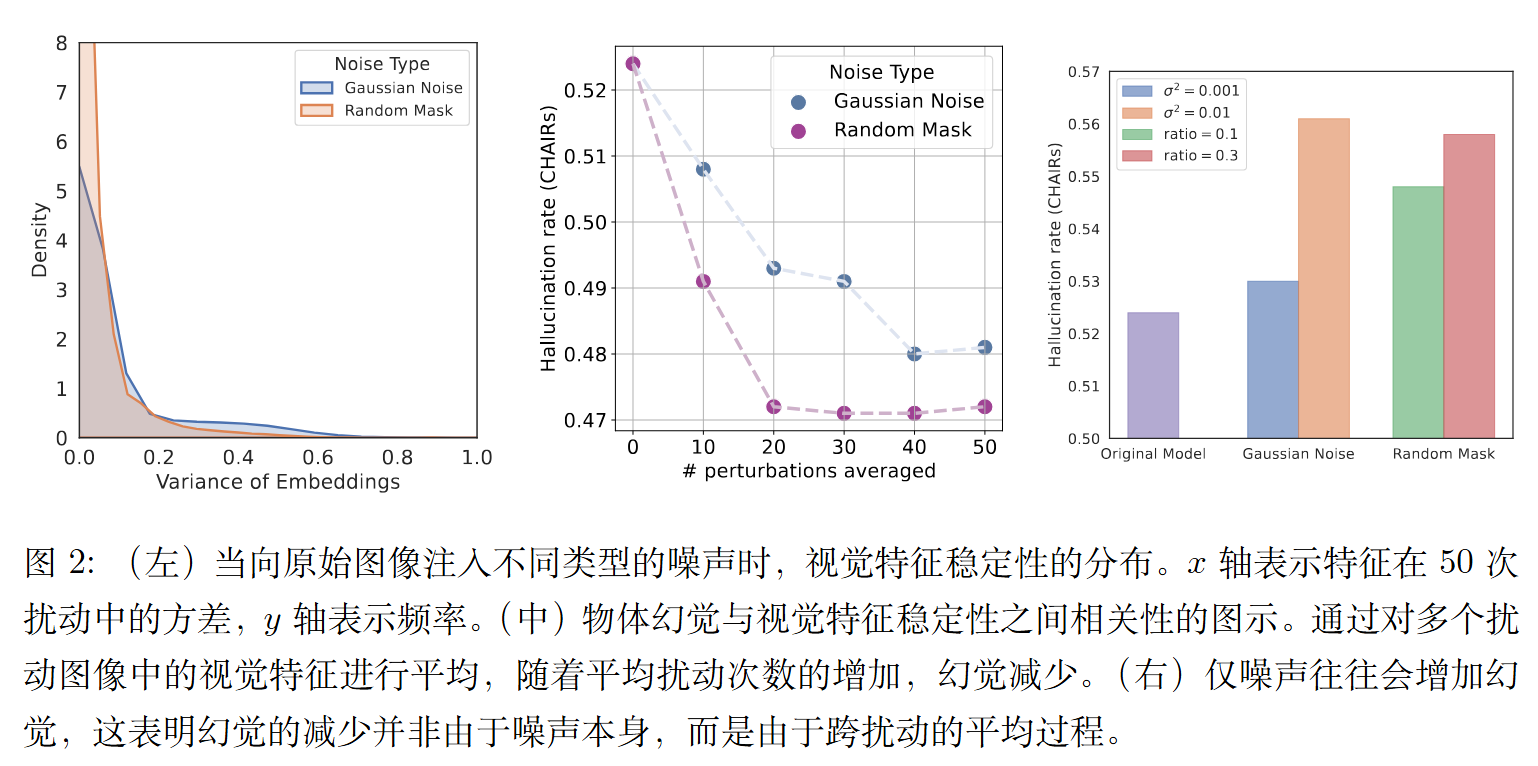
然而,如上图所示,虽然大多数视觉特征保持稳定,但约 15% 的特征表现出显著的方差,形成了长尾分布。
尽管特征平均能够缓解幻觉现象,但它也带来了显著的弊端。由于视觉编码器是在干净数据上训练的,对图像进行扰动会损害信息提取,导致细节丢失。此外,对视觉特征进行平均需要多次通过模型进行前向传播,大幅增加了计算成本。
因此,作者的目标是开发一种方法,既能有效增强视觉特征的稳定性并减少幻觉,又不牺牲信息或产生过高的计算开销。
方法
具体而言,预先计算了更稳定特征的“方向”,并在推理过程中一致地应用于所有查询示例以减少幻觉,而无需引入额外的训练或推理成本。由于有时幻觉源于文本解码器(即 LLM),进一步获取了文本方向并将其应用于文本解码器以最大化性能。
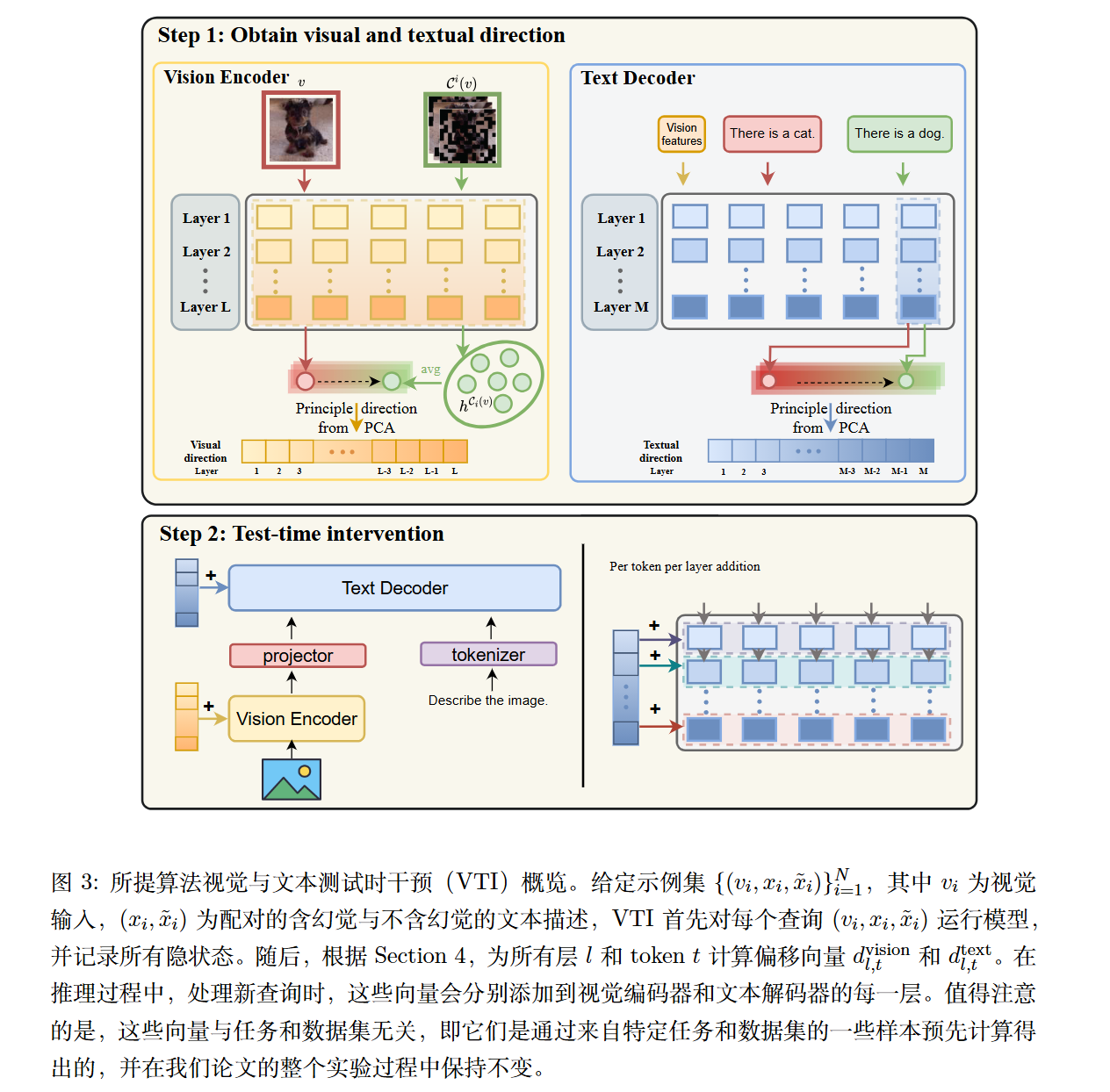
具体来说,给定视觉驶入v,其潜在状态为$h_{l,t}^v$,其中l表示层,t表示视觉token的索引。
视觉token偏移向量:
类似于特征平均,使用m种不同的随机掩码$C_i$,随机mask输入图像v。直观上,它们的平均嵌入$\bar h_{l,t}^v=\sum h_{l,t}^{C_i(v)}$是鲁棒嵌入。
故视觉方向如此计算:$\Delta_{l,t}^v=\bar h_{l,t}^v-h_{l,t}^v$
由于期望的视觉方向应能轻松应用于新的图像查询。为了去除方向向量中的图像特定信息,仅保留特征平均带来的变化。
获取N个样本,并计算$[\Delta_{l,t}^{v_1},\Delta_{l,t}^{v_2},…,\Delta_{l,t}^{v_N}]$主方向$d_{l,t}^{vision}$。
不同于其他论文,本论文使用的是归一化的SVD,也就是PCA。
文本偏移向量:
精心挑选N张无幻觉的图像描述,记为$x$,并采用GPT模型生成带有幻觉的版本$\tilde x$。
简单地使用原始对应的图像v作为视觉输入,文本方向为:$\Delta_{l,t}^{x_i,v_i}=h_{l,t}^{x_i,v_i}-h_{l,t}^{\tilde x_iv_i}$
其中$h_{l,t}$代表在生成输出最后一个 token 时,第 t 个文本 token 在第 l 层的隐状态。特别地,因为文本解码器是因果建模的,我们仅使用最后一个 token 的潜在状态,t=last token。同样地只取主方向$d_{l,t}^{text}$。
作者有点符号混用。
由于视觉编码器并非因果建模,在前向传播过程中对所有层的潜在状态在所有 token 位置进行了位移调整:
$$
h_{l,t}^v:=h_{l,t}^v+\alpha\cdot d_{l,t}^{vision}
$$
对于文本,我们通过文本方向来调整文本解码器的潜在状态:
$$
h_{l,t}^{x,v}:=h_{l,t}^{x,v}+\beta\cdot d_{l,t=last token}^{text}
$$
1 | |
Volcano: 通过自我反馈引导修正减轻多模态幻觉
Volcano: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision
方法

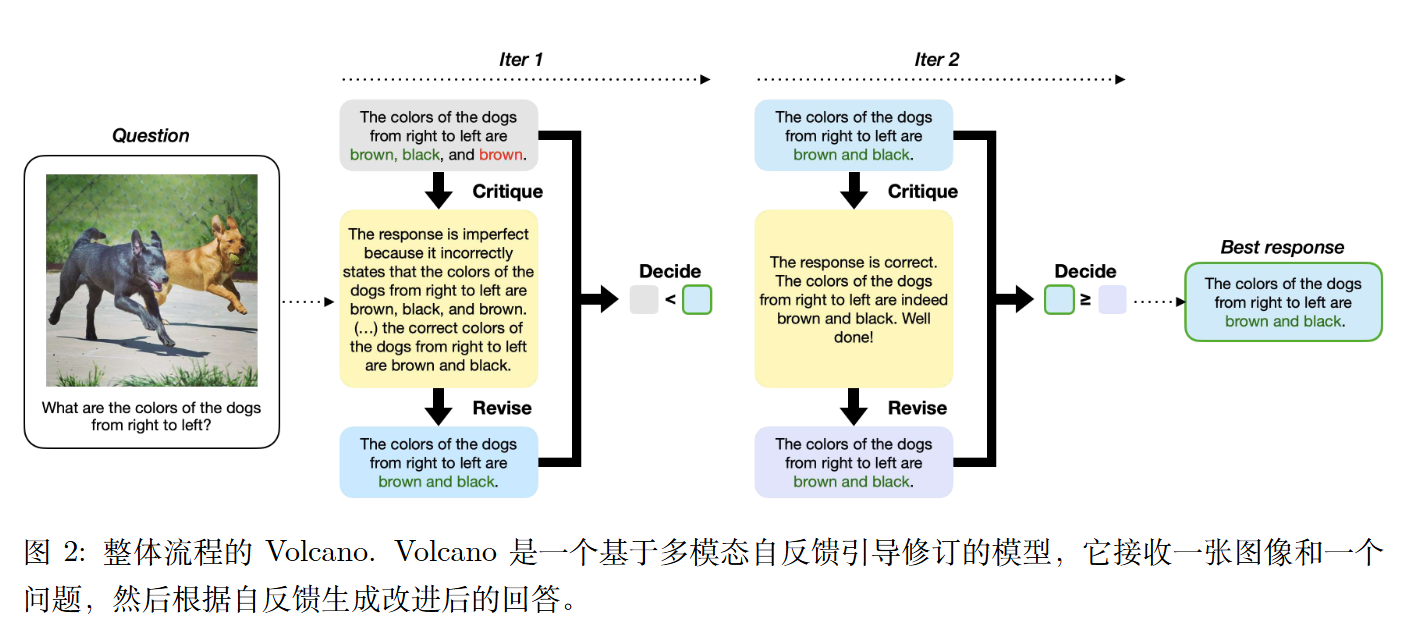
迭代式自我修订
Volcano 是一个通过四阶段顺序过程生成改进响应的单一模型。
首先,类似于其他 LLM,它为图像 $R_{initial}$ 和问题 $I$ 生成初始响应 Q ,并将最佳响应 $R_{best}$ 初始化为 $R_{initial}$ 。此阶段在整个创建最终响应的过程中只执行一次。
其次,它根据$R_{best}$ 生成反馈F (阶段 1) 。使用此反馈,它自我修订 $R_{best}$ (阶段 2)。由于无法保证修订后的响应 $R_{revised}$ 会比现有的 $R_{best}$更好,因此需要确定哪一响应对于给定的 Q 和I 更好。此时,Volcano 被提供 Q 、I 以及两个响应,并经历决定哪个响应更好的过程 (阶段 3)。在阶段 3 中,$R_{revised}$ 和 $R_{best}$ 的顺序是随机的,以防止位置影响结果。 (作者对此引用了《Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models》,但并未找到具体文字,只找到“Li et al. (2022c) 发现大型语言模型有时会 错误地将偶然相关性,例如位置接近或高度共 现的关联,当作事实知识。”)
如果模型认为 $R_{revised}$ 比 $R_{best}$ 更好,则 $R_{best}$ 会被更新为 $R_{revised}$ ,并重复从阶段1 到阶段 3 的过程,直到达到预定的最大迭代次数。否则,循环将提前停止,$R_{best}$ 将被选为最终输出。
数据采集
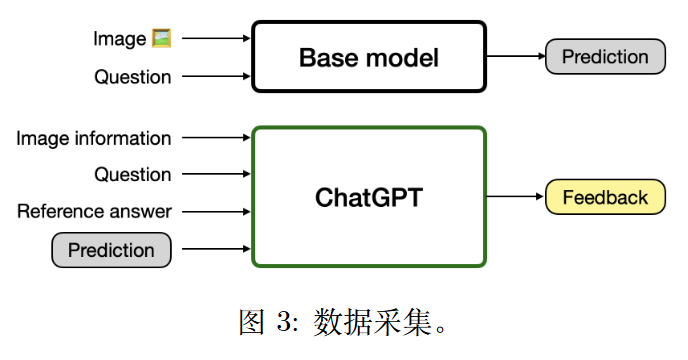
从开源的 LMM 中收集视觉问题的初始回答,并使用专有 LLM 生成反馈和修改。
专有的大语言模型可能会利用黄金答案(Gold Answer,预先准备好的、完全正确的回答)来生成反馈,这可能导致在推理时由于未提供黄金答案而产生潜在的不准确性。为了避免这种情况,作者给大语言模型明确的提示,使其在生成反馈时关注文本格式的图像细节。
在构建修订数据时,作者建立了一个系统,将现有的黄金答案作为输出进行预测,使用从上一步骤中获得的反馈数据、图像、问题和初始回答作为输入,而不涉及任何分离的模型生成过程。
定性分析
作者还定性分析反馈如何有效减少多模态幻觉。
视觉信息量
对于每个实例,执行top-k 平均汇聚(作者尝试了最小值、最大值、平均值,但是还是top-k提供了最清晰的可视化效果)来聚合初始响应或反馈词元在每个图像特征上的注意力权重。具体来说,在隐藏层上对前 3 个注意力权重求平均,在自注意力头上的前 3 个权重求平均,然后在输出词元上对前-l 个权重求平均,其中 l 是初始响应和反馈中较短输出的长度。
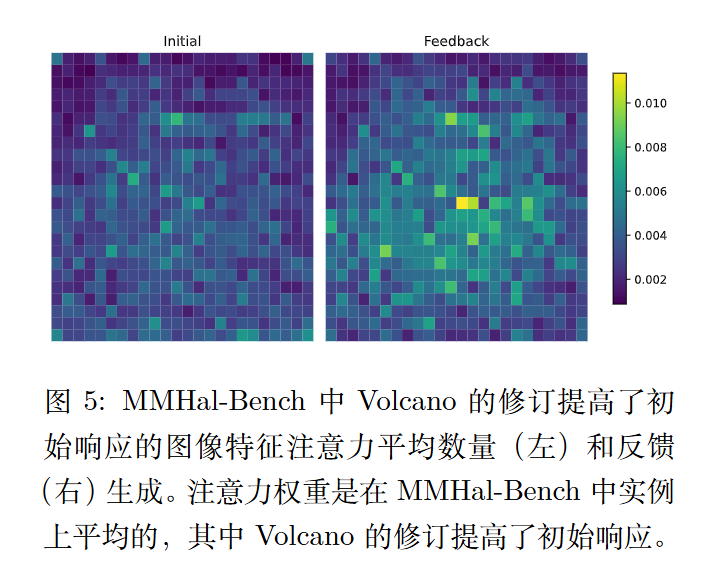
视觉信息的覆盖
作者进一步进一步通过实验研究单个词元的注意力如何有助于关键视觉信息的覆盖。
将输出中所有词元的注意力权重与输出中一部分词元的注意力权重进行比较。对于后一种过程,生成过程中最强烈关注图像特征的词元被视为显著词元并被选择。
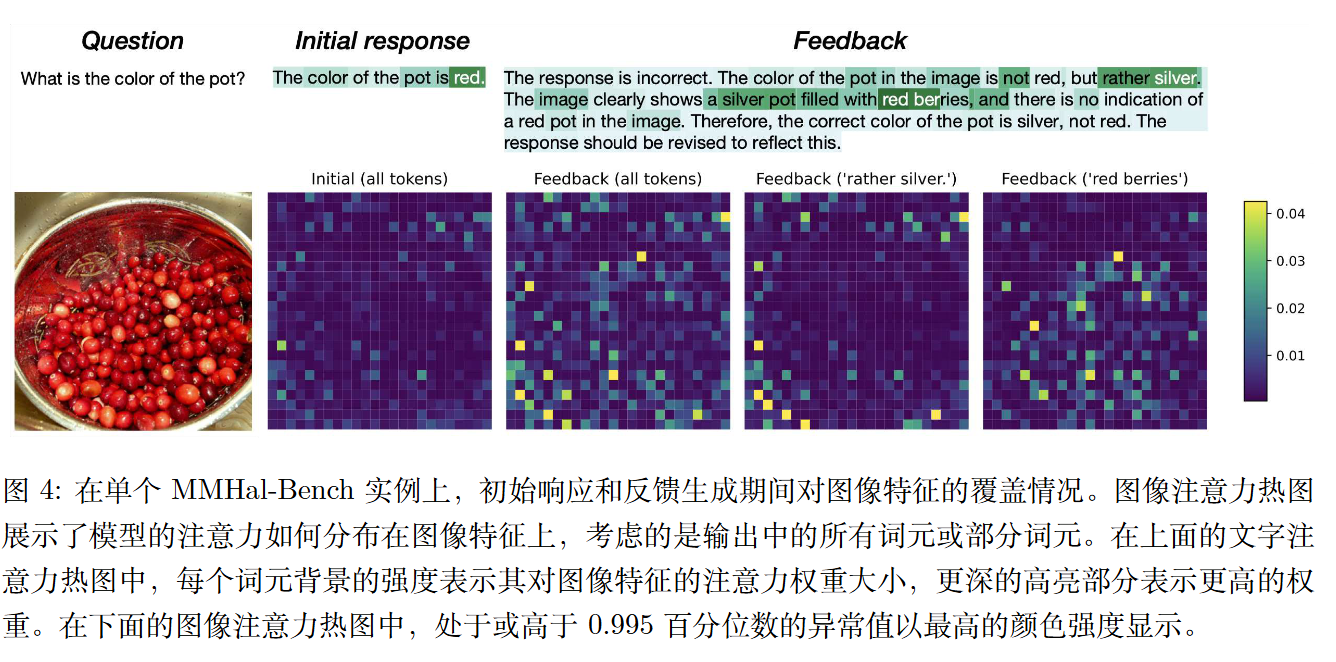
此示例中的任务是识别图像中锅的颜色,初始响应错误地回答为(“红色”),然后反馈更正了答案(“银色”)。
这种修正可以通过生成每个词元时对图像特征的注意力分布差异来解释。
基于所有关注图像特征的词元的热力图,当 Volcano 生成初始响应时,它主要关注外边缘的特征,对应于锅的边缘;在生成反馈时,它关注整个图像,包括对应于银色锅的外部区域和包含红色浆果的内部区域。
关注图像特征的特定词元的热力图显示,在改进初始响应的过程中,Volcano 在生成这些词时确实关注了对应于关键颜色描述符“银色”和“红色”的确切图像区域。
局限性
Volcano 需要多次调用模型,因此比直接生成响应的效率更低。平均而言,Volcano 的运行速度比基础模型慢约2 到 3 倍,对于给定的图像和指令生成响应需要 5.8 秒,而 LLaVA-1.5 只需要 2.7 秒。作者用来减少总体执行时间的一个策略是将迭代次数限制为 3 次。
视觉语言模型中的多对象幻觉
Multi-Object Hallucination in Vision Language Models
NeurIPS 2024
简介
系统地研究了一个重要问题:当大型视觉语言模型(LVLMs)被要求同时关注和识别图像中的多个物体时,它们会如何产生误解(例如,凭空捏造不存在的物体或分散注意力) 。
系统地研究多目标幻觉,论文提出了一个名为ROPE (Recognition-based Object Probing Evaluation,基于识别的物体探测评估) 的自动化评估协议。
为了避免使用文字描述物体时可能产生的歧义(比如一张图里有多个苹果,说“苹果”就不知道指哪个),ROPE 在图像上使用红色的边界框直接框出要识别的物体,从而精确指向特定对象 。
ROPE 设计了标准化的问答格式(例如,要求模型以 obj1: <class1>, obj2: <class2>, ... 的格式输出),这样就可以通过简单的文本解析来自动评估模型的准确性,无需依赖人类或其他“黑箱”模型进行评判 。
ROPE 在测试时考虑图像中对象类别的分布,将 ROPE 分为四个子集:
In-the-Wild(真实场景):随机选择和排序图像中的5个物体,类别分布混合 。
Homogeneous:所有被框出的5个物体都属于同一个类别(例如,5个都是苹果)
Heterogeneous:5个被框出的物体分别属于5个不同的类别 。
Adversarial:前4个物体属于同一类别,最后一个物体属于不同类别(例如,4个苹果,1个橙子),用来测试模型是否会因为惯性而出错 。
主要发现简介如下:
(1)与仅关注单一对象相比,LVLM 在被要求关注多个对象时会产生更多幻觉;
(2) 测试对象类别分布影响幻觉行为,揭示出 LVLM 可能依赖捷径和虚假相关系数;
(3) LVLM 的幻觉行为受到数据特定因子、显著性与频率以及模型内在行为的影响。
主要发现
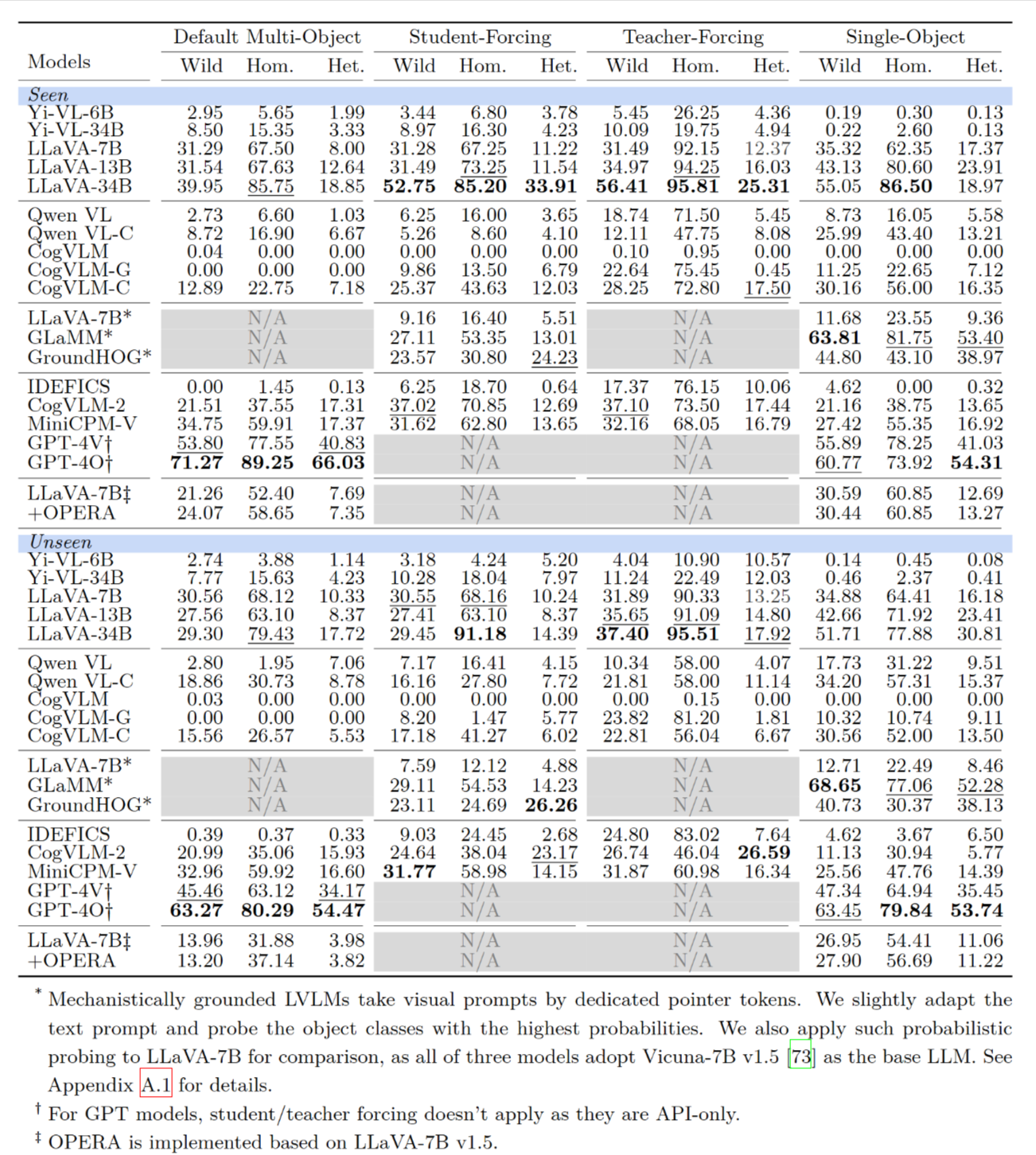
在多种主流的视觉语言模型(如 LLaVA, GPT-4V, GPT-4O, CogVLM ,Yi-VL等)上进行了实验,得出了三个关键结论:
多目标任务比单目标任务更容易产生幻觉: 实验结果清晰地表明,与一次只识别一个物体相比,当模型被要求同时识别多个物体时,其准确率显著下降,幻觉现象更加严重 。
被测物体的类别分布会影响幻觉行为: 模型在处理同质物体(都是同一类)时表现最好,而在处理异质物体(每个都不同类)时表现最差,幻觉最多 。这表明模型可能依赖于某种“捷径”或虚假的关联性来做出判断,而不是真正地逐一识别每个物体 。
对抗性测试揭示了模型的“思维捷径”: 在“AAAAB”这样的对抗性测试中,模型在识别前几个相同的物体(A)时准确率很高,甚至越来越高。但当识别到最后一个不同的物体(B)时,准确率会断崖式下跌,模型极大概率会把它也错误地识别成A 。这有力地证明了模型并没有真正理解任务,而只是在利用语言偏见和重复先前答案这样的“捷径” 。
影响幻觉的因素分析
深入分析了可能导致多目标幻觉的多种因素:
数据特定因素
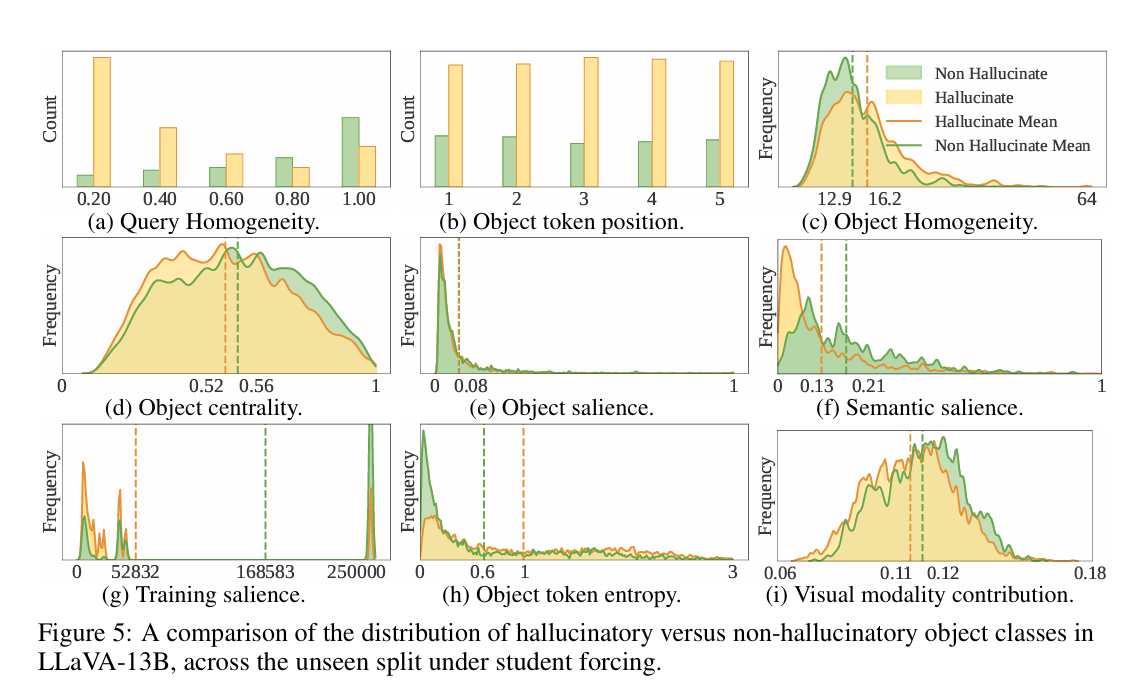
查询同质性(Query Homogeneity): 当任务中需要识别的物体类别越单一时,模型幻觉越少 。
物体在图像中的位置(Object Centrality): 位于图像边缘的物体比位于中心的物体更容易被错误识别 。
显著性和频率因素
物体显著性:先前的研究表明,较小的物体更难被检测和定位到。本文将物体显著性定义为物体实例分割掩码占据的像素数量与图像总像素数量的比值。
语义显著性(Semantic Salience): 如果某一类别的物体在图像中多次出现(例如,桌子上有很多罐子),那么模型在识别这个类别的单个物体时更不容易出错 。
训练数据频率(Training Salience): 模型对于在训练数据中频繁出现的物体类别,更不容易产生幻觉 。
模型内在行为
模型不确定性(Object Token Entropy): 当模型对自己的预测感到不确定时(表现为输出词元的熵更高),更容易产生幻觉 。
对视觉信息的关注度(Visual Modality Contribution): 分析发现,模型在做判断时,对文本信息的依赖远大于视觉信息。当模型对视觉信息的关注度降低时,产生幻觉的可能性会略微增加 。
结论
简单提升模型参数可能不够: 仅仅增加语言模型的参数量可以减少单目标幻觉,但对更复杂的多目标幻觉问题效果不明显 。
训练数据是关键: 需要构建更多样化、更平衡的训练数据,包含更多需要同时理解多个物体的指令,特别是那些不常见的、位于图像边缘的物体 。
应用上的建议: 在要求高准确率的场景下,可以考虑将复杂的多目标识别任务分解成多个单目标识别任务,即一次只问一个物体,以减少幻觉的风险 。
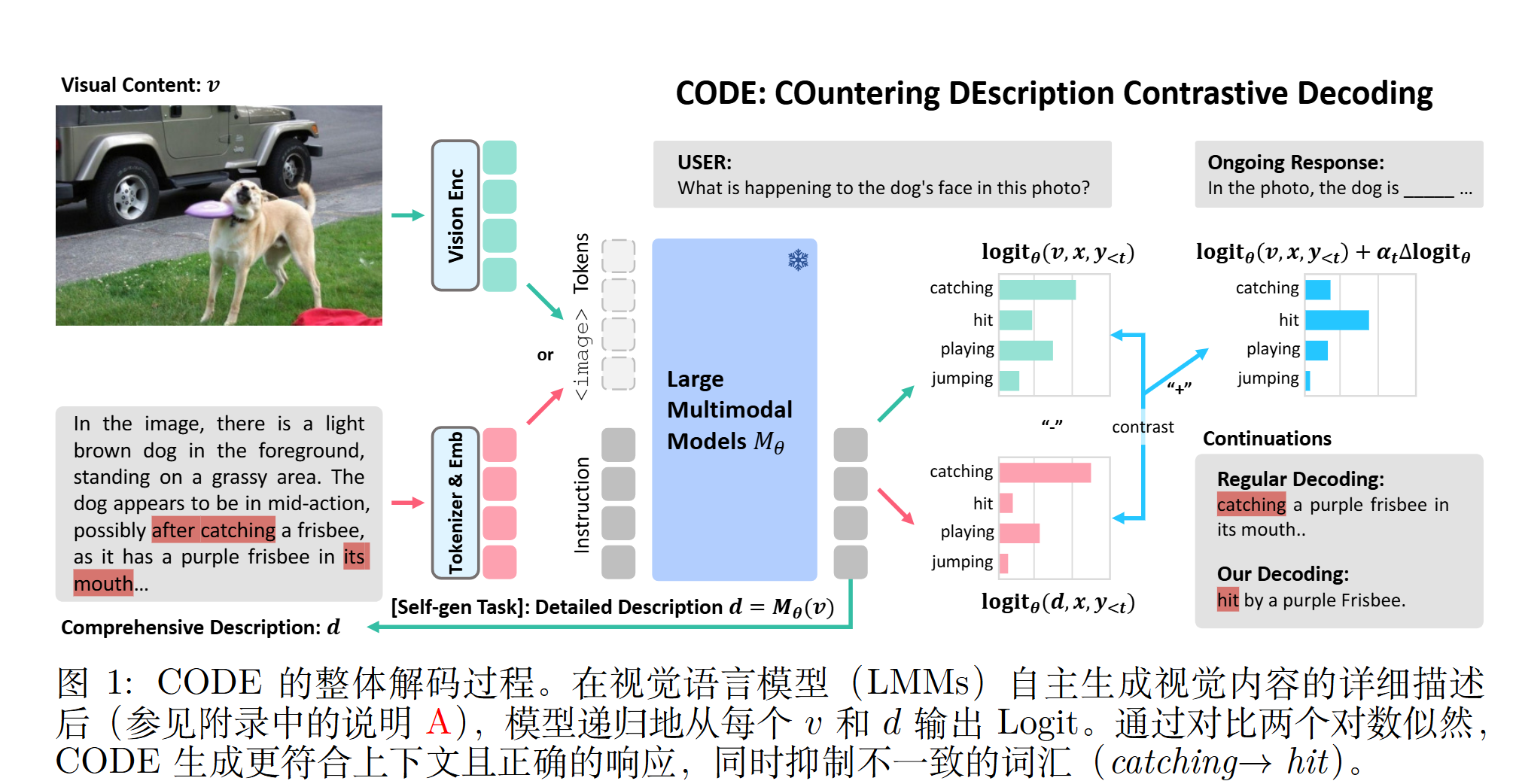
CODE:对比自生成描述以应对大型多模态模型中的幻觉问题
CODE: Contrasting Self-generated Description to Combat Hallucination in Large Multi-modal Models
NeurIPS 2024
CODE (COuntering DEscription Contrastive Decoding)
贡献:
- CODE是一种无需训练的解码策略,利用自生成的描述来减少大型多模态模型中的幻觉现象。通过对比描述所包含的 Logit 信息与实际视觉内容,CODE 提升了模型响应的视觉一致性和连贯性。
- 在对比解码阶段引入了动态限制策略。通过根据 token 在词表中的分布来调整其层级预测,有选择性地调控信息流,从而确保生成更具上下文相关性的响应。
- 在多种基准上验证了有效性。
方法

实验
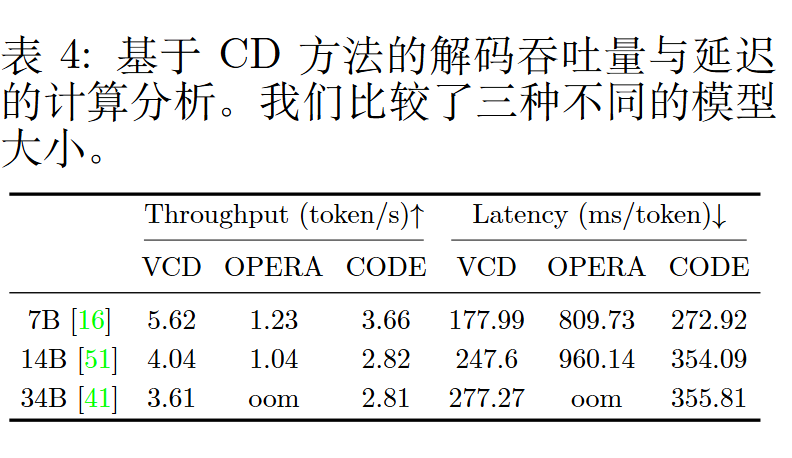
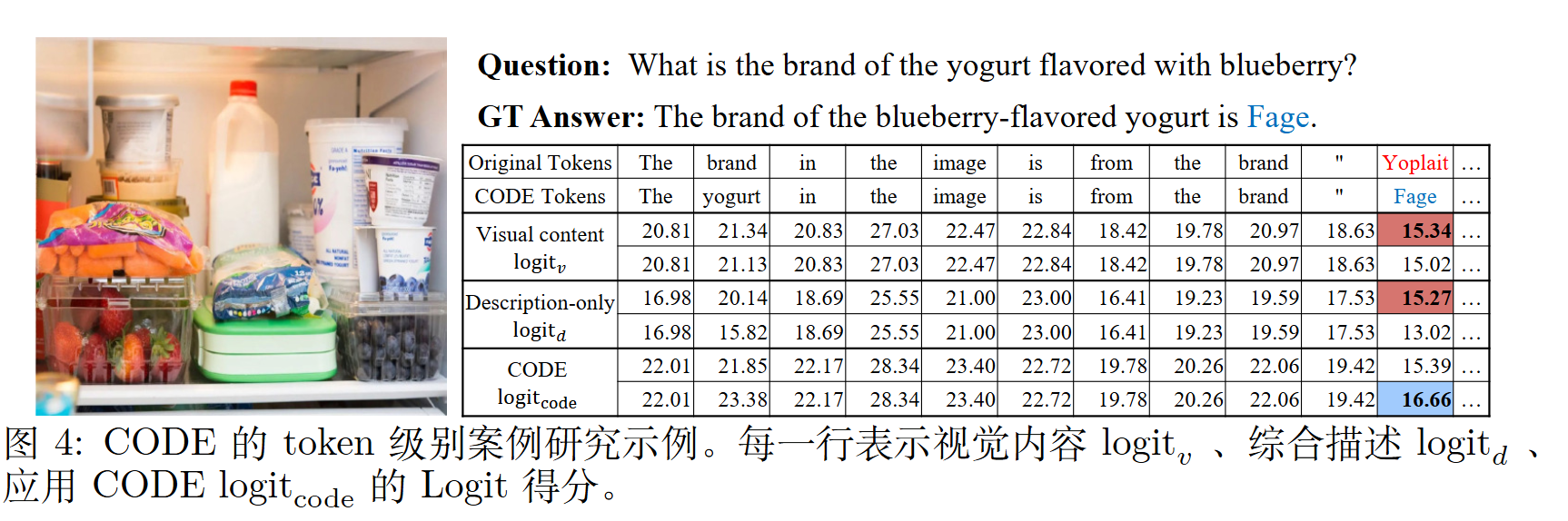
代码流程已经写得还明白了。
直接把有界散度代入$\alpha$很能work有点太奇了
失败案例
作者推断,仅依赖自生成的描述并不总是足够,尤其是在描述本身存在偏见或不准确的情况下。
