Machine Unlearning
Lucas Bourtoule 等人于 2019年在 arXiv 上发表,并最终在 2021年的 IEEE Symposium on Security and Privacy (S&P) 上正式发表的论文 《Machine Unlearning》。
比较早期的模型,方法比较朴素。
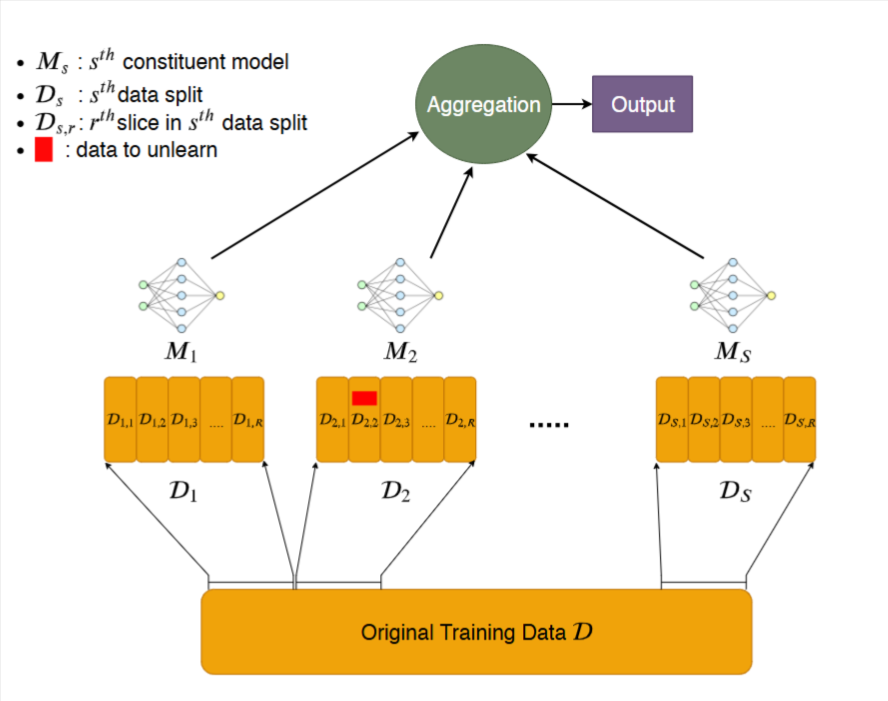
训练阶段 (Training Phase):
数据分片 (Sharding):将完整的原始训练数据集
D分割成S个互不相交的数据子集,称为“分片” (Shards)。数据切片 (Slicing):将每个分片
Dk内部的数据再进一步分割成R个互不相-交的“切片” (Slices)。隔离与增量训练 (Isolated & Incremental Training):为每一个分片
Dk单独训练一个模型Mk,过程如下:- 步骤 1: 使用随机初始化的参数,仅在第一个切片
Dk,1上训练模型。训练完成后,保存当前模型的参数状态。 - 步骤 2: 加载上一步保存的模型参数,然后在
Dk,1∪Dk,2的数据上继续训练。完成后保存新的模型状态。 - 重复此过程: 直到模型在所有
R个切片上都训练完毕。每次加入一个新的切片进行训练后,都要保存一次模型状态。
- 步骤 1: 使用随机初始化的参数,仅在第一个切片
聚合 (Aggregation):在需要进行预测时,将输入数据分别送入所有
S个独立训练好的模型。然后通过“多数投票”等策略将它们的输出结果聚合起来,得到最终的预测结果。
反学习阶段 (Unlearning Phase):
当收到一个删除数据点 du 的请求时:
定位 (Locate):首先,确定这个数据点
du属于哪个分片Dk和哪个切片Dk,r。回滚 (Rollback):加载在训练阶段保存的模型状态,具体来说,是加载在第
r个切片被引入之前保存的状态。重新训练 (Retrain):从加载的状态开始,继续执行增量训练过程。但在处理第
r个切片时,使用剔除了数据点du的数据。完成 (Complete):只有包含
du的这一个模型Mk被重新训练,其他所有模型完全不受影响。
优化策略
作者提出了如何更智能地进行分片以最小化未来的unlearning成本,称为分布感知的智能分片 (Distribution-Aware Sharding)
我们定义:
- 数据集
D - 一个常数阈值
C
流程:
排序: 根据每个数据点
du被请求删除的概率p(u),对整个数据集进行升序排序(概率最低的在前)。初始化: 创建第一个空的分片
D0。循环分配: 遍历排序后的数据集:
- 从数据集中取出当前删除概率最低的数据点
du。 - 将
du添加到当前的分片Di中。
- 从数据集中取出当前删除概率最低的数据点
检查阈值: 每次添加后,计算当前分片
Di的“预期被删除次数”E(χi)。- 如果
E(χi) ≥ C:- 将刚刚添加的数据点
du从当前分片Di中移出。 - 创建一个新的空分片
Di+1。 - 将数据点
du添加到这个新的分片Di+1中。
- 将刚刚添加的数据点
- 如果
结束: 重复步骤3和4,直到所有数据点都被分配到某个分片中。
缺点
比较早期的模型,方法比较朴素。
模型参数量大,重新训练就很耗时。
在当时,作者认为遗忘有以下难度。
