Mitigating Hallucinations in Large Vision-Language Models by Self-Injecting Hallucinations
(EMNLP 2025 )
Autonomous Preference Alignment via Self-Injection =APASI
motivation
LVLM幻觉模式的三个关键观察 :
物体共现:模型倾向于幻觉出那些经常与图像中真实存在的物体一同出现的物体(例如,在有“沙发”的场景中幻觉出“椅子”或“桌子”)。
语言先验:模型在生成内容时会过度依赖语言中的常见搭配,而非完全基于视觉信息 。
位置因素:幻觉内容通常出现在回复的后半部分 。
算法
APASI 针对前面的三个观察,进行构建偏好对:
- preffered $y_i^+$:原始相应
- dis-preffered $y_i^-$:故意注意幻觉后生成的响应
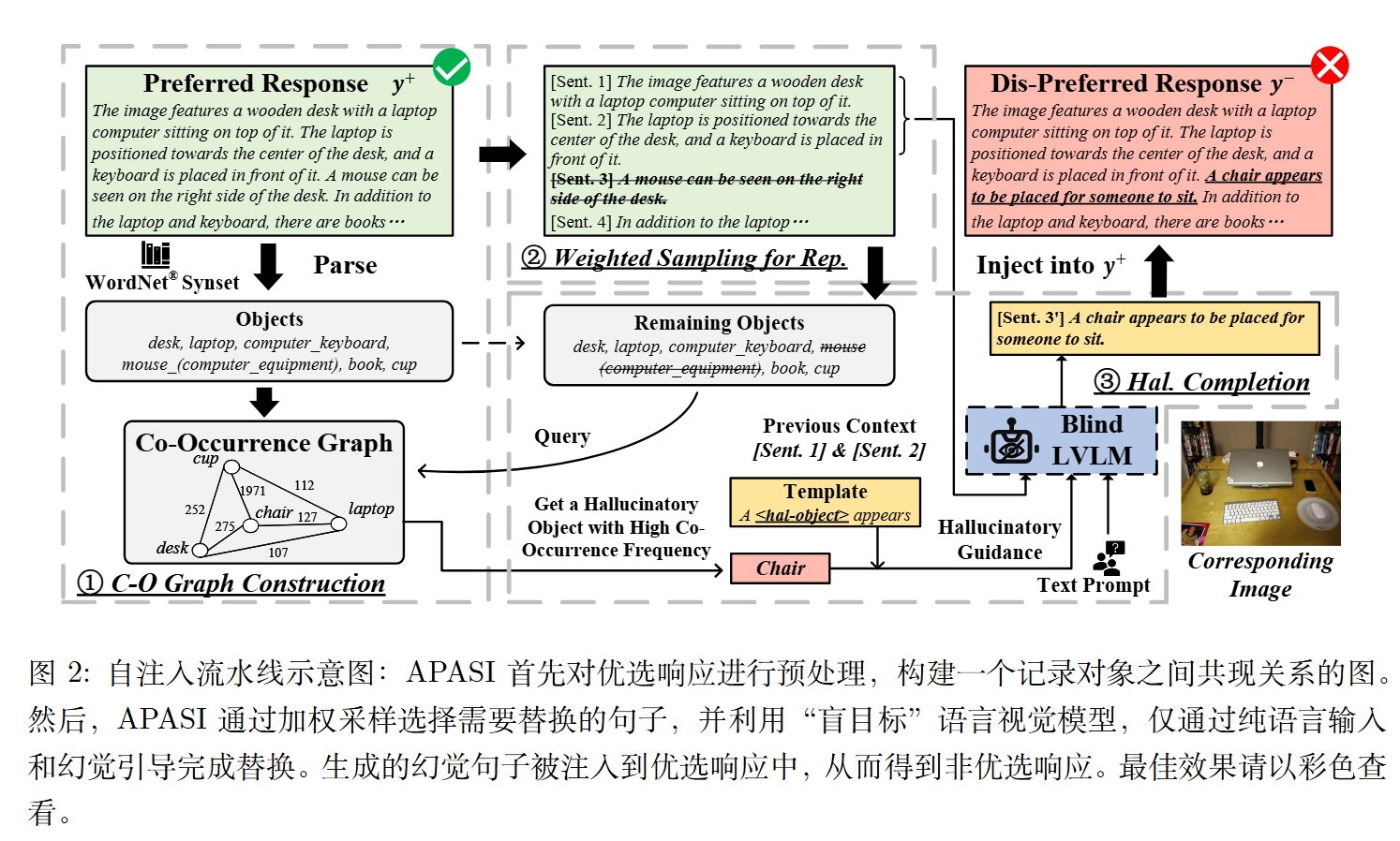
构建共现图(Co-Occurrence Graph Construction)
对$y_i^+$进行预处理,通过WordNET工具箱和同义词集S解析成一组物体标签。
构建一个图。其中节点代表物体标签,边权重代表连接物体的共现频率。
加权采样
以概率/注入率$\rho$对原始句子替换为幻觉对应的句子。
由于考虑幻觉通常出现在响应的后半部分,我们经验性设定最后一个句子被采样的概率为第一个句子的两倍,并线性插值,即第k个句子的权重为$w_k=1+\frac{k-1}{L}$
幻觉补全与注入
假设APASI在$y_i^+$中采样第k个句子,用一个幻觉句子$y_{i,k}^-$替代,即:
$$
y_i^-=(y_{i,1}^+,…,y_{i,k-1}^+,y_{i,k}^-,y_{i,k+1}^+,…,y_{i,L}^+)
$$
对于一个待替换的句子,APASI会查询共现图,找到一个与回复中其他句子所描述物体共现频率高,但实际图片中不存在的物体。然后将其放到预定义的引导模板中,例如,“一个<幻觉物体>出现了”)来引导一个**“盲”LVLM** (即不给它看图片,只给它文本上下文) 来完成一个描述这个幻觉物体的句子 。
最后得到$y_i^-$。
课程学习的迭代对齐
为缓解偏好对齐中的分布偏移问题,APASI采用一种迭代对其策略。在迭代t时,使用最新优化的模型$M_{\theta_{t-1}}$进行偏好数据构建,包括生成偏好响应和注入幻觉。随后,Mθt−1 通过DPO目标与偏好数据进行优化,得到$M_{\theta_t}$ ,用于下一次迭代的数据构建。
还引入了一种课程学习机制,逐步增加对齐任务的难度。
该课程学习机制具体地根据一个单调递减的课程函数 $f_c(t)$,在每次迭代 t 中降低注入率$\rho$。随着 $\rho$的减小,优选响应$y^+$与非优选响应$y^-$之间的差距逐渐缩小,使得区分偏好对中细微差异的挑战性显著增强。

代码未公开。
所以我们也不知道这个$f_c(t)$选的是什么。