Vision Transformers Don't Need Trained Registers
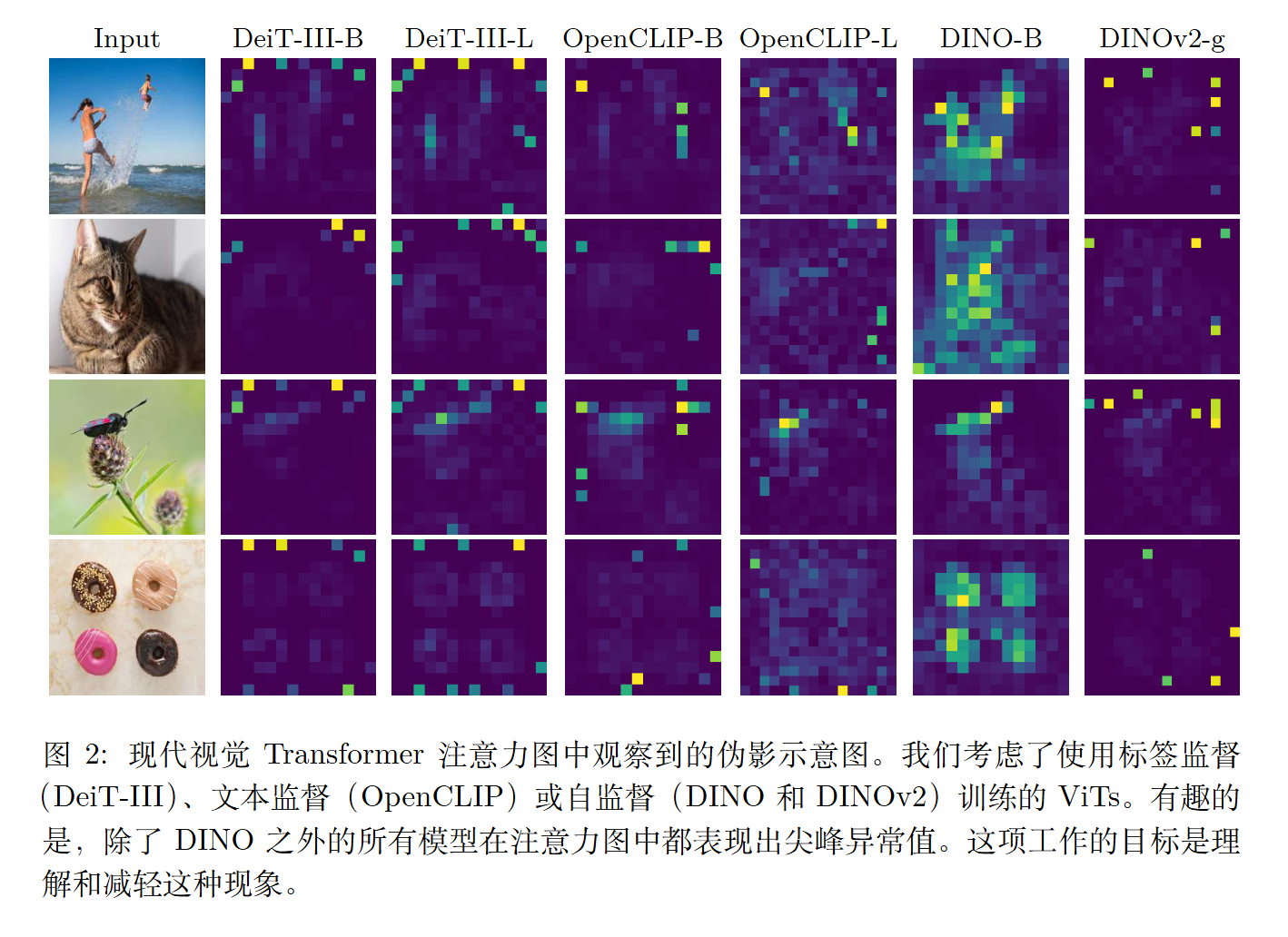
ICLR 2024的《VISION TRANSFORMERS NEED REGISTERS》指出了VIT中也会出现类似attention sinks的伪影。对于REGISTERS我们是否需要可训练呢?
ICLR 2024的《VISION TRANSFORMERS NEED REGISTERS》指出了VIT中也会出现类似attention sinks的伪影。
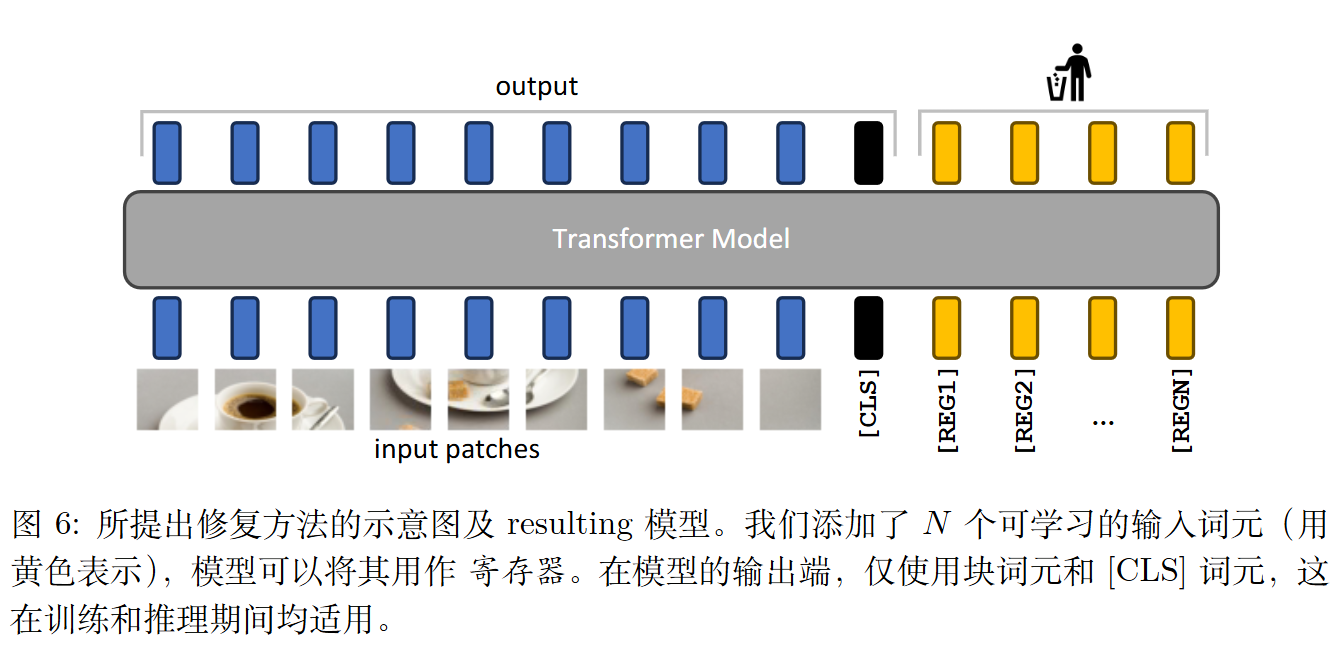
应对的方法类似于streamingllm,即额外添加一些元素来承载多余的注意力。
反驳
但最近9月的一篇arxiv(2506.08010)指出我们其实不需要在训练就加入,我们完全可以在测试时再把多余的注意力移走。
作者提出了一种如何移动的方法。

我们可以随意移动。
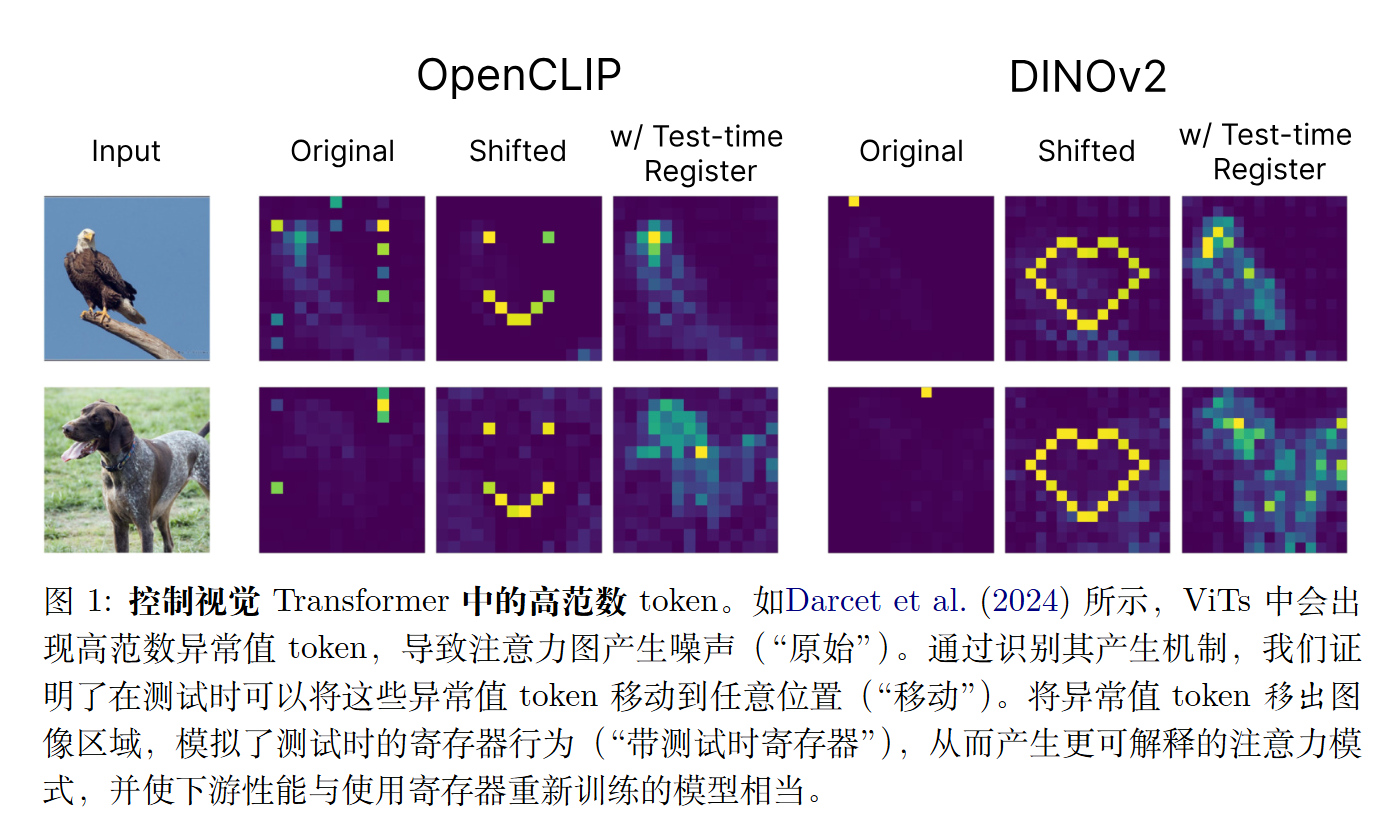
我们既然可以随意移动,那我们也可以把它移动到图像外的额外token上。
从其代码看不出来额外的token的位置在哪。不过根据其demollava_demo.ipynb ,更像是类似GPT-OSS的处理方式,即需要对模型进行修改,而非对原生模型进行处理。
Vision Transformers Don't Need Trained Registers
https://lijianxiong.space/2025/20250914/