LLM中MOE的安全行为
(arxiv 2025)
[2509.09660] Steering MoE LLMs via Expert (De)Activation
SAFEx
能够清晰地定位并区分专家为两个不同的功能类别:
(1) 有害内容检测组(HCDG):专门用于识别和检测用户输入中有害内容的专家。
(2) 有害响应控制组(HRCG):专门用于控制和强制模型行为,生成适当的对齐安全响应(例如,拒绝或拒绝响应)的专家。
专家统计 (Expert Statistics) 与稳定性专家选择 (SES) 算法
重复采样: 首先,从一个大的基础数据分布中(例如,包含各类有害问题的 D_Regular 数据集),多次独立地、不放回地抽取样本,形成多个经验数据集 X^(k)。
独立估计: 针对每一个采样出的数据集 X^(k),独立计算其中每个专家 e 的激活概率 p(e|X^(k))。
识别高频专家: 在每个数据集中,根据计算出的激活概率,选出排名最高的 N 个专家,形成一个高频专家集合 E_top^(k)。
取交集: 最后,将所有采样数据集得到的高频专家集合 E_top^(k) 进行求交集操作。这个交集中的专家,就是被认为不受特定数据样本影响、稳定且频繁被激活的关键专家集合 E_top(X)。
通过对常规有害数据集 ($\mathcal{D} _ {Regular}$) 和“越狱”有害数据集 ($\mathcal{D} _ {Jailbreak}$) 分别执行 SES 算法,可以得到两组不同的稳定高频专家集合。
专家功能分类
在获得不同场景下的高频专家集合后,算法通过简单的集合运算对它们进行功能划分。
有害内容识别组 (Harmful Content Detection Group, $\mathcal{E} _ {id}$):
- 定义: 这些专家在处理常规有害输入和越狱有害输入时都会被稳定激活。这表明它们的核心作用是识别内容本身的有害性,而不受提问方式的影响。
- 计算方法: 通过取两个高频专家集合的交集获得:$\mathcal{E} _ {id} = \mathcal{E} _ {top}(\mathcal{D} _ {Regular}) \cap \mathcal{E} _ {top}(\mathcal{D} _ {Jailbreak})$。
安全响应控制组 (Harmful Response Control Group, $\mathcal{E} _ {ctrl}$):
- 定义: 这些专家只在模型成功拒绝常规有害输入时被激活,而在模型被越狱成功、生成不安全内容时则不会被激活。这表明它们专门负责执行模型的安全机制,生成拒绝回答。
- 计算方法: 通过取两个高频专家集合的差集获得:$\mathcal{E} _ {ctrl} = \mathcal{E} _ {top}(\mathcal{D} _ {Regular}) - \mathcal{E} _ {top}(\mathcal{D} _ {Jailbreak})$。
专家功能验证
最后,为了验证上述分类的准确性,算法设计了两种针对性的实验。
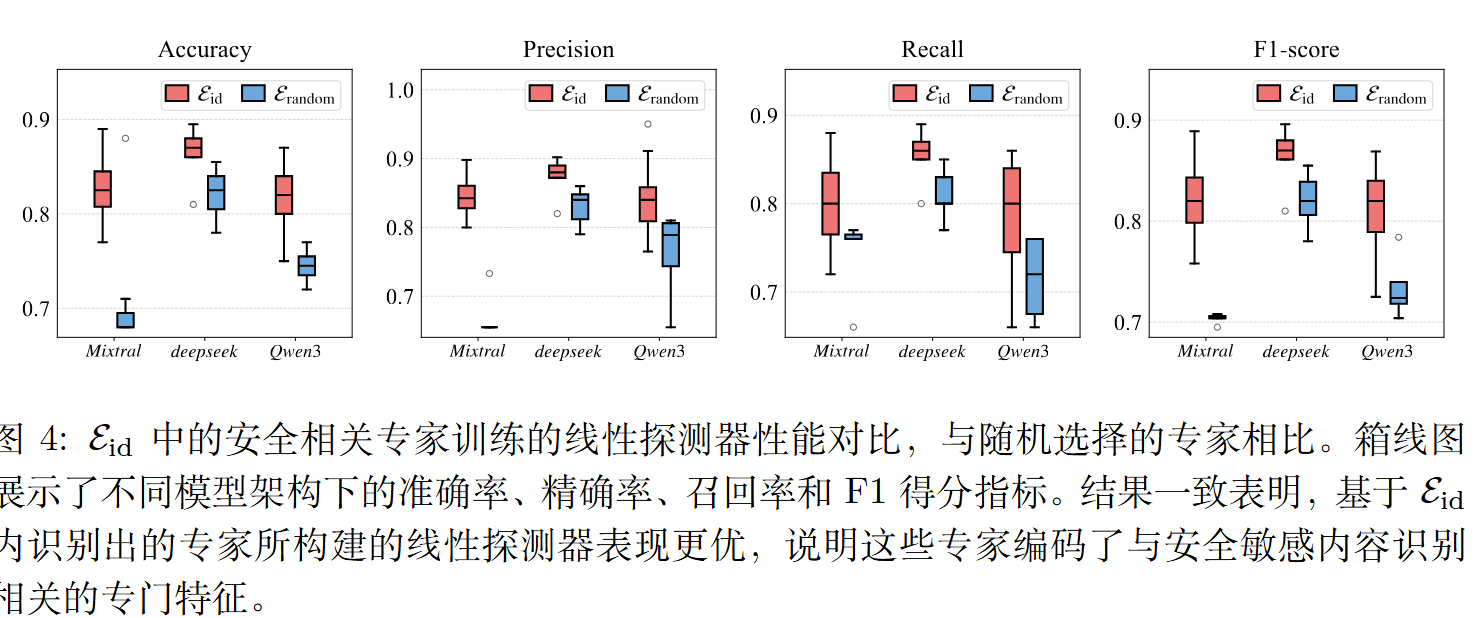
线性探测 (Linear Probing) - 验证 $\mathcal{E} _ {id}$:
- 目的: 验证“有害内容识别组”的专家是否真的具备区分有害内容的能力。
- 方法: 提取 $\mathcal{E} _ {id}$ 中每个专家的输出特征(隐状态),然后用这些特征来训练一个简单的线性分类器,任务是判断输入是有害的还是无害的。如果基于这些专家特征训练的分类器表现(如准确率、F1分数等)远超随机选择的专家,就证明了它们的识别功能。
利用所识别专家的前馈网络(FFNs)输出的特征作为线性分类器的输入,该分类器预测一个二元标签,用以判断输入提示是否具有危害性或无害。
$$
\hat y=\sigma(W\times h_{id}(x)+b),\hat y\in{0,1}
$$
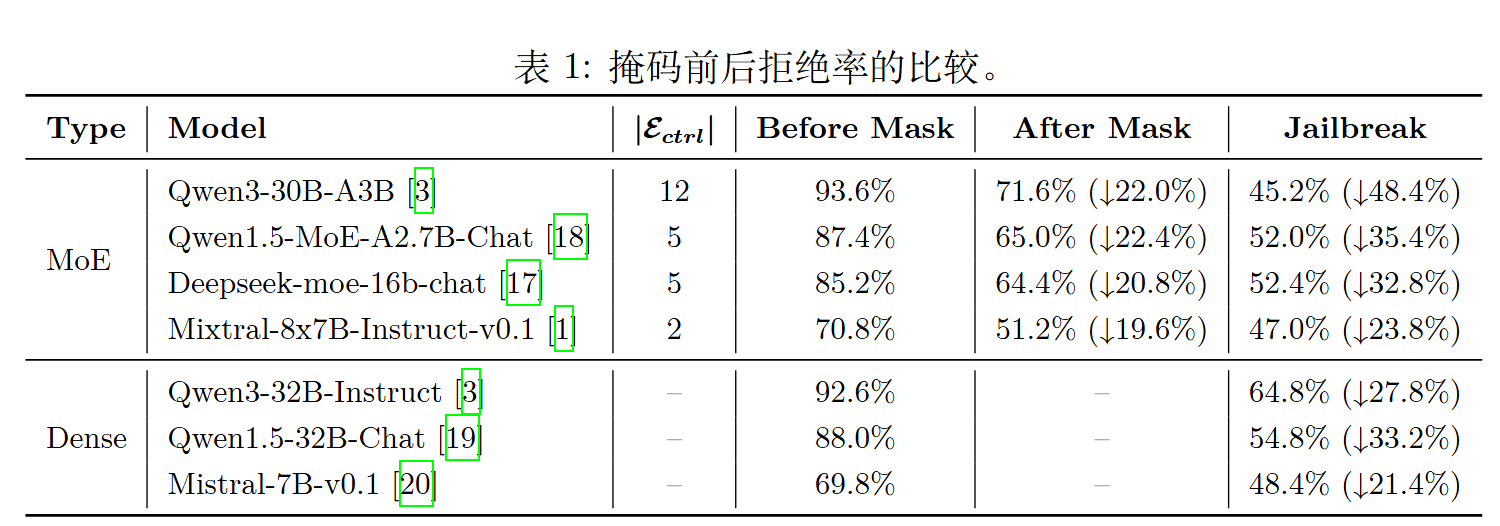
专家屏蔽 (Expert Masking) - 验证 $\mathcal{E} _ {ctrl}$:
- 目的: 验证“安全响应控制组”的专家是否对模型的拒绝行为至关重要。
- 方法: 在模型进行推理时,人为地“屏蔽”(禁用)$\mathcal{E} _ {ctrl}$ 集合中的所有专家。具体做法是将这些专家的路由权重设置为一个极小值(负无穷),使其在 Softmax 后的概率接近于零,从而不会被选中。然后观察模型在处理有害请求时的拒绝率是否有显著下降。实验结果表明,屏蔽极少数这类专家就会导致模型的安全性能大幅降低。
SteerMOE
提出将 MoE 路由机制重新诠释为一种可控制且可解释的模块,而不仅仅是一个分配计算资源的工具,它实际上是一个富含信号的层,可在测试时调节模型行为。具体而言,我们假设某些专家与特定技能、特质或倾向存在行为上的纠缠,通过检测并(禁用/启用)这些专家,可以有针对性地引导模型的输出。
检测
创建成对的样本:
首先,研究人员需要准备两组不同的输入样本,每一组代表一种相反的行为。
- 样本组 (1):包含“安全”行为的样本(例如,一个有害提问 + 一个拒绝回答)。
- 样本组 (2):包含“不安全”行为的样本(例如,同一个有害提问 + 一个顺从的有害回答)。
统计专家的激活次数:
接下来,统计在处理这两组样本时每个专家被激活的总次数(即被路由到的令牌数量)。
- $A _ {i}^{(1)}$:专家
i在所有“安全”样本中被激活的总次数 。 - $A _ {i}^{(2)}$:专家
i在所有“不安全”样本中被激活的总次数。 - $N^{(1)}$:所有“安全”样本中的令牌总数。
- $N^{(2)}$:所有“不安全”样本中的令牌总数。
计算激活率(Activation Rate):
用每个专家的总激活次数除以对应样本组的总令牌数,得到该专家在特定行为下的激活概率(或频率)。
- 专家
i在“安全”行为下的激活率为: $P_i^{(1)} = A _ {i}^{(1)} / N^{(1)}$ - 专家
i在“不安全”行为下的激活率为: $P_i^{(2)} = A _ {i}^{(2)} / N^{(2)}$
计算风险差异(RD):
最后,将这两种行为下的激活率相减,就得到了专家 i 的风险差异(RD),在论文中用符号 $\Delta _ {i}$ 表示,$\Delta _ {i} = P_i^{(1)} - P_i^{(2)}$
若$\Delta _ {i}$为正值,说明它与安全行为正相关,是安全专家。
若$\Delta _ {i}$为负值,说明它与不安全行为正相关,是不安全专家。
若$\Delta _ {i}$接近于0,说明该专家与这两种行为的关联性不强。
引导
确定目标专家: 根据 RD 分数对专家进行排序,以确定要促进或抑制哪些专家来实现预期结果。例如,为了让模型更安全,他们会激活具有高“安全”RD 分数的专家,并抑制具有高“不安全”RD 分数的专家 。
调整路由器 Logits: 在生成回答时,对于每个令牌,他们会截获路由器为每个专家生成的原始分数(logits) 。
之前会首先进行logsoftmax,以将其置于一个共享的尺度上。即s=logsoftmax(z)
而我们有softmax(logsoftmax(z))=softmax(z)
应用引导规则,简单的规则 :
- 要激活一个专家,就人为地将其分数设置为所有专家中的最高分 。
$$
s_k \leftarrow s _ {min}-\epsilon
$$
- 要抑制一个专家,就人为地将其分数设置为所有专家中的最低分 。
生成输出: 模型随后根据这些修改后的分数照常选择得分最高的 k 个专家,并继续生成过程。这种“软”引导确保了目标专家被优先选择或避免,而不会完全破坏模型的整体功能。