PerturboLLaVA:通过扰动视觉训练减少多模态幻觉
(ICLR 2025)
两个贡献
当前缺乏一种在概念层面精细衡量描述质量的指标,故有了:
HalFscore:一种新颖的评估指标,旨在从概念层面精细地衡量图像描述的准确性和完整性。
缓解幻觉,故有了:
PerturboLLaVA:一种创新的“扰动式视觉训练”方法。该方法通过在训练过程中引入与图像内容相冲突的、精心设计的误导性文本,来降低模型对其固有语言知识(即“语言先验”)的过度依赖,从而迫使其更加关注视觉输入。
像OPERA和VCD,尽管解码策略具有无需训练的优势,但它们并未解决多模态模型中幻觉的根本原因,因为这些问题源于训练阶段。此外,从实际角度来看,大模型的推理成本通常超过训练成本,因为模型训练一次但部署无数次。
HalFscore
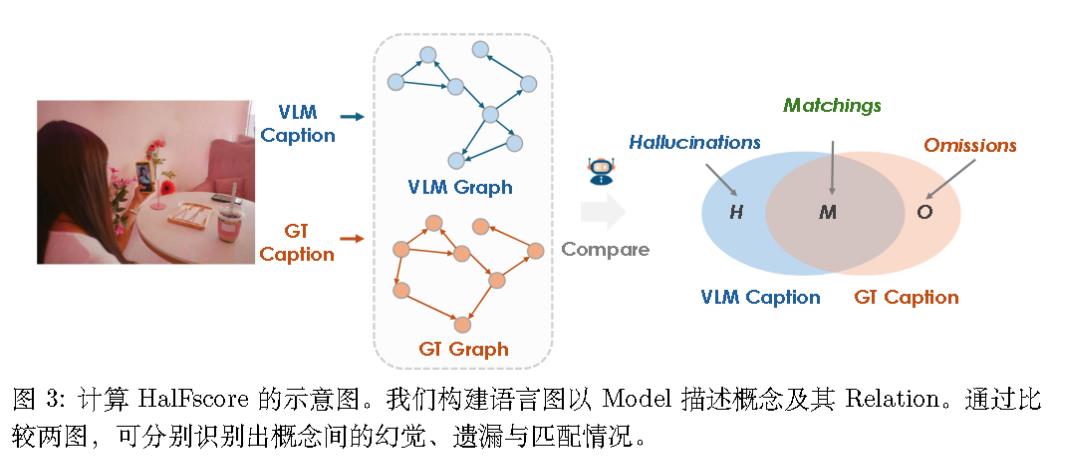
图谱构建:通过 GPT-4o 模型,从文本中提取信息,并将其表示为三元组(triplets),形式为 <实体1, 关系, 实体2> 。例如,“时钟在墙上”可以表示为 (时钟, on, 墙),“镜子是粉色的”可以表示为 (镜子, is, 粉色) 。这些三元组随后被整合成一个图谱,其中实体是节点,关系是边 。
$$
\text{Precision} = \frac{|C_{\text{gen}} \cap C_{\text{gt}}|}{|C_{\text{gen}}|}
= 1 - \frac{|C_{\text{hallucinated}}|}{|C_{\text{gen}}|},
$$
$$
\text{Recall} = \frac{|C_{\text{gen}} \cap C_{\text{gt}}|}{|C_{\text{gt}}|}
= 1 - \frac{|C_{\text{omitted}}|}{|C_{\text{gt}}|}.
$$
最后综合起来得到$\text{HalFscore}$(其实就是F1):
$$
\text{HalFscore} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}.
$$
PerturboLLaVA
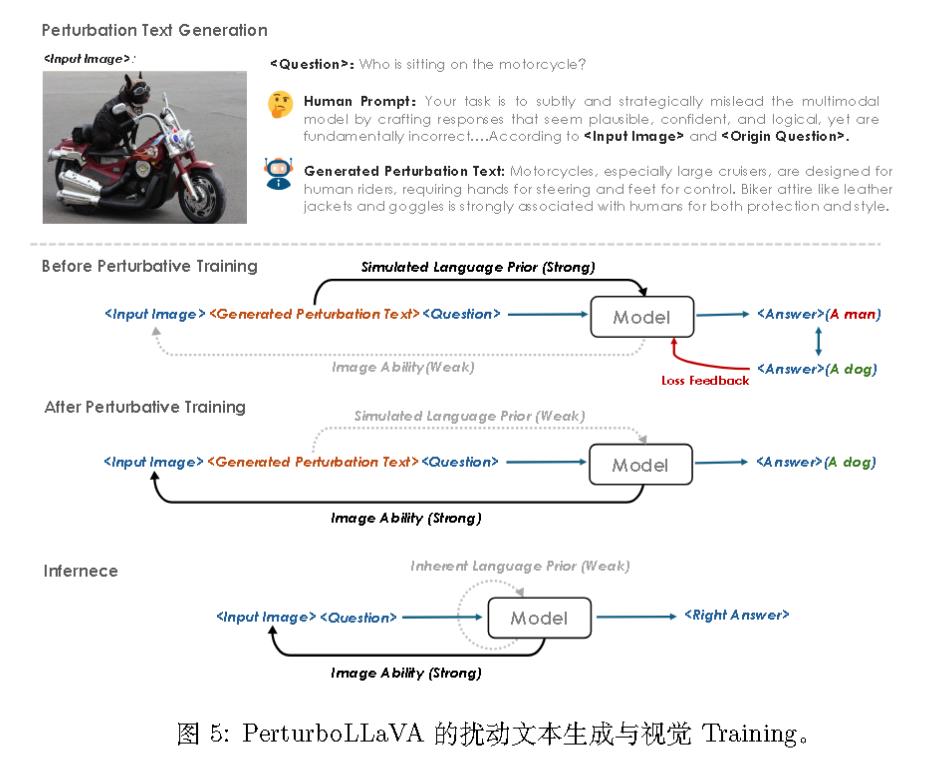
为确保扰动的有效性和自然性,遵循以下原则。
- 上下文相关性。扰动应与图像内容在上下文上相关,使其看似合理但具有误导性。
- 与预训练知识对齐。扰动设计需与常见的语言先验产生共鸣,确保其现实性并反映潜在的模型偏差。
- 语义多样性。通过改变$x_p$的结构和主题元素,确保扰动的多样性,使其与常见的误解或偏见保持一致。在实际操作中,使用 GPT-4o 生成扰动文本。GPT-4o 模型会查看图像、问题和答案,并根据世界知识以及某些图像细节,构建强大且多样化的扰动,而不泄露答案。GPT-4的指令提示详见附录。