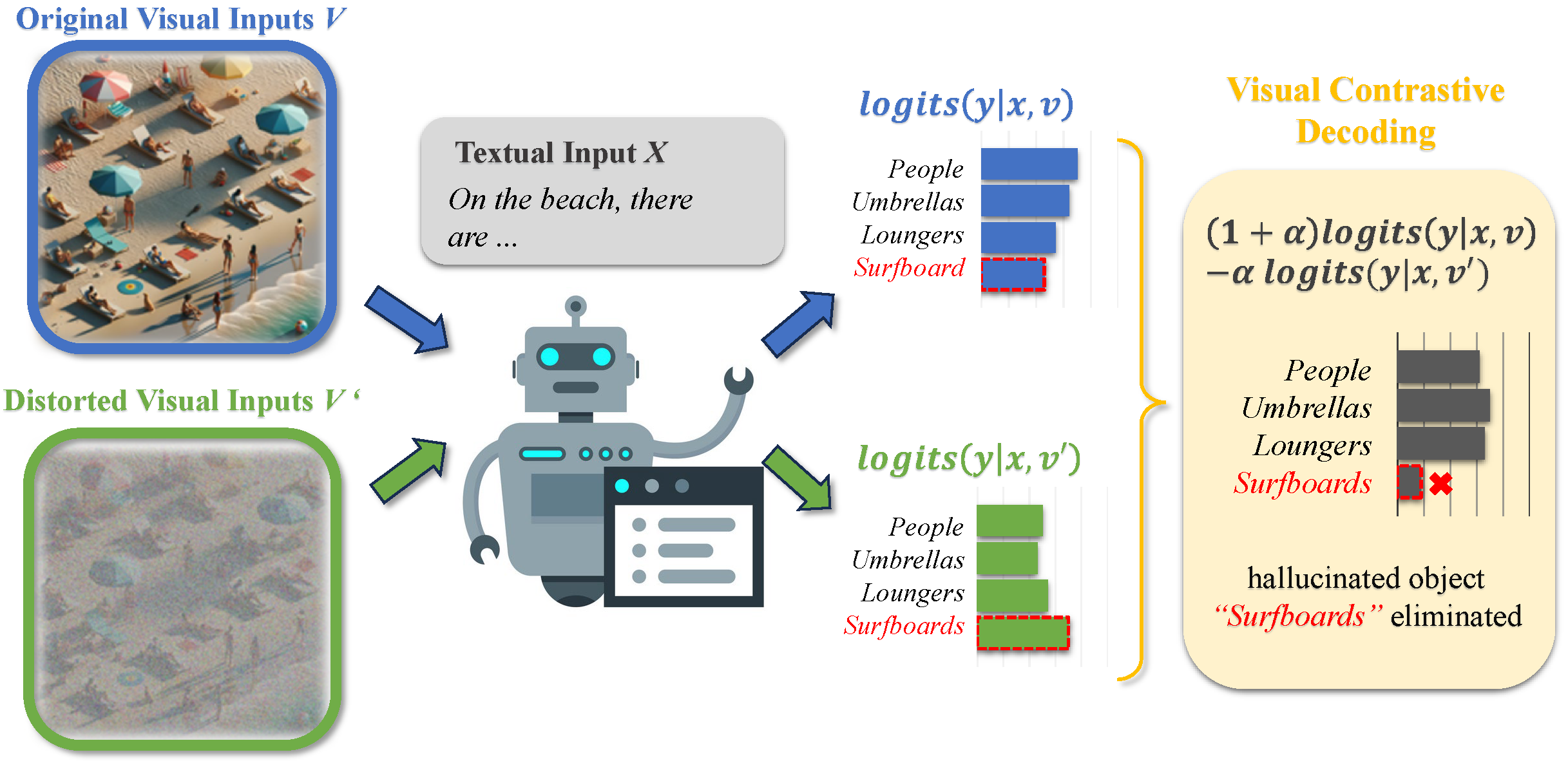
对比解码之VCD
(CVPR 2024 Highlight)
《Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive》
对比解码
对比解码( Contrastive Decoding ,CD)提供了一种用于缓解幻觉景的方法,通过对比原始输入和失真输入之间的输出分布。具体而言,CD 方法首先生成两个输出分布:一个来自原始视觉图像 v 和文本查询 q,另一个来自扰动后的输入 v∗ 和 q∗。然后,通过检查两个分布之间的差异,可以构建一个对比响应 ℓcd,如下所示:
$$
\begin{align}
\ell _ {cd}&=mlogp(y_t\mid v,q,y _ {<t};\theta)-nlogp(y_t\mid v^\ast,q^\ast,y _ {<t};\theta)
\\
y_t&\sim Softmax(\ell _ {cd})
\end{align}
$$
比如m可以为$1+\alpha$,n为$\alpha$。
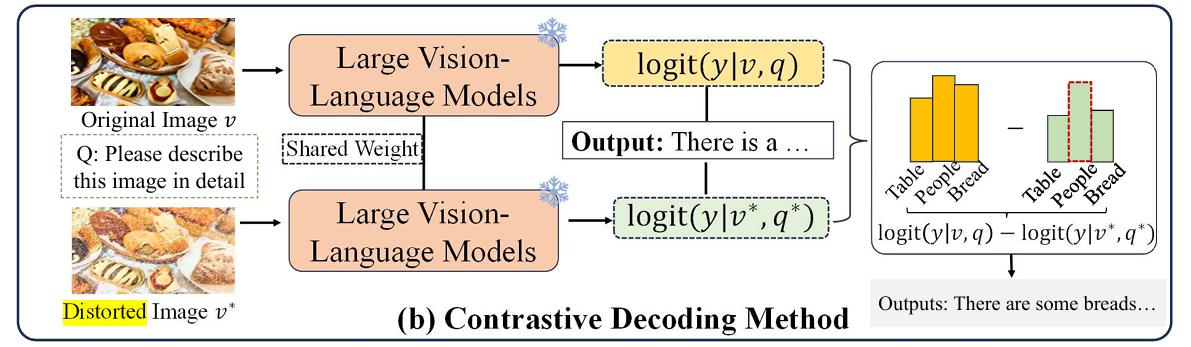
(图来自《Octopus: Alleviating Hallucination via Dynamic Contrastive Decoding》)
VCD
VCD遵循同样的流程。
对于构建失真图像,使用的是diffusion的(高斯)加噪过程。
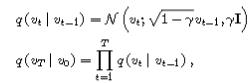
为了避免过度惩罚可能正确的常规用语,VCD还引入了一项“自适应合理性约束” 。该机制会保留原始图像输入下置信度较高的候选词,防止模型生成不合逻辑的文本 。
在决定下一个要生成的词语时,它并不直接在整个词汇表中进行对比解码。而是先做一步筛选:
1.创建候选词列表:首先,模型会仅根据原始的、清晰的图像来预测下一个最有可能的词语 。
2.设置置信度门槛:它会筛选出一个“高置信度”的候选词集合 V_head 。这个集合只包含那些在清晰图像下预测概率足够高的词语。这个“足够高”是由一个超参数
β (beta) 来控制的 。
3.在候选范围内解码:最后,核心的VCD对比解码过程只会在这个预先筛选出的“合理”候选词列表 ( V_head ) 中进行,而不是在整个词汇表中进行 。
具体而言,
$$
\mathcal{V} _ {\text{head}}(y _ {<t}) = {y_t \in \mathcal{V} : p _ {\theta}(y_t | v, x, y _ {<t}) \ge \beta \max _ {w} p _ {\theta}(w | v, x, y _ {<t})}
$$
$$
p _ {\text{vcd}}(y_t | v, v’, x) = 0, \quad \text{if } y_t \notin \mathcal{V} _ {\text{head}}(y _ {<t})
$$
其中 $\mathcal{V}$ 是 LVLMs 的输出词表,$\beta$ 是 [0,1] 中用于控制下一个 token 分布截断的超参数。较大的 $\beta$ 表示更激进的截断,仅保留高概率的 token。