kNN-LMs:一种RAG和LLM前的记忆挂靠方法
(ICLR 2020)
《Generalization through Memorization: Nearest Neighbor Language Models》
这是一种免训练的方法。
算法

Training Contexts处或者更扩展的来说,可以是额外的数据集。
对于额外数据集:
上下文词元序列$c_t=(w_1,…,w _ {t-1})$
记f(c)为模型某一层输出,定义键值对为:
$$
(K,V)=((f(c_i),w_i)\mid (c_i,w_i)\in D)
$$
再根据负距离的softmax计算邻居上的分布:
$$
p _ {\text{kNN}}(y|x) \propto \sum _ {\langle k_i, v_i \rangle \in \mathcal{N}} \mathbb{1} _ {y=v_i} \exp(-d(k_i, f(x)))
$$
对于原始输入:
我们把以上融合进来:
$$
p(y\mid x)=\lambda p _ {knn}(y\mid x)+(1-\lambda)p _ {LM}(y\mid x)
$$
使用faiss进行检索。
实验
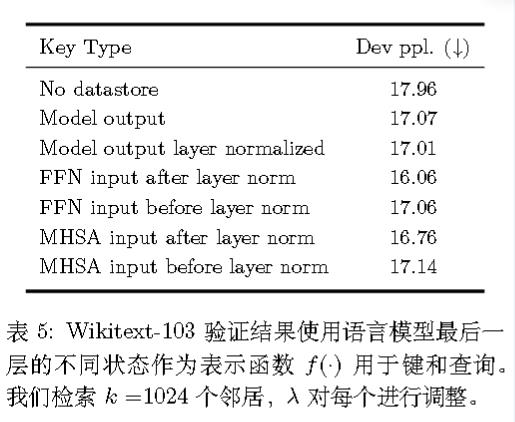
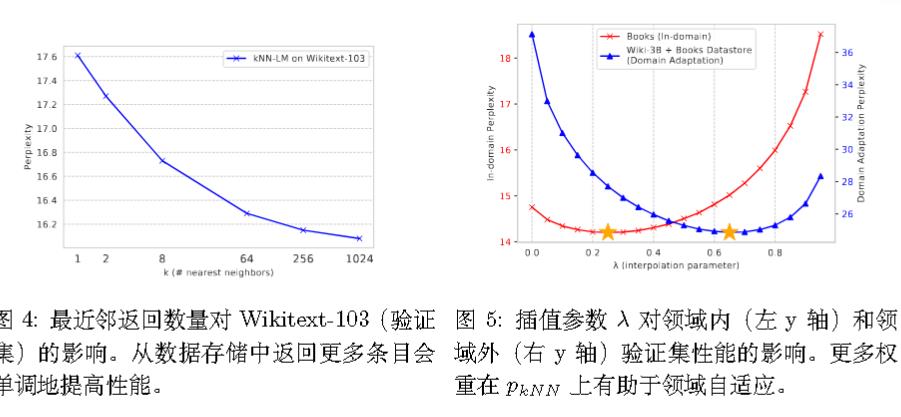
kNN-LMs:一种RAG和LLM前的记忆挂靠方法
https://lijianxiong.space/2025/20250902/