DINO系列
本文将介绍facebook/meta出品的DINOv1~v3。
DINO = Self-distillation with no labels
注意与目标检测《DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection》那篇关于目标检测的文章做区别。
DINO V1
在开始之前我们不妨回顾一下一些相关的对比学习方法。
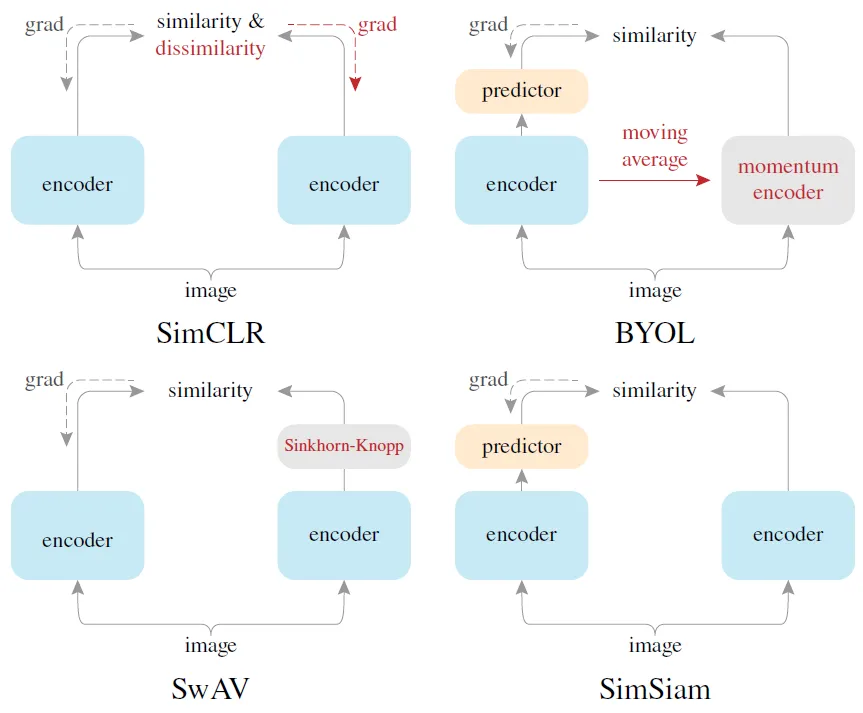
算法
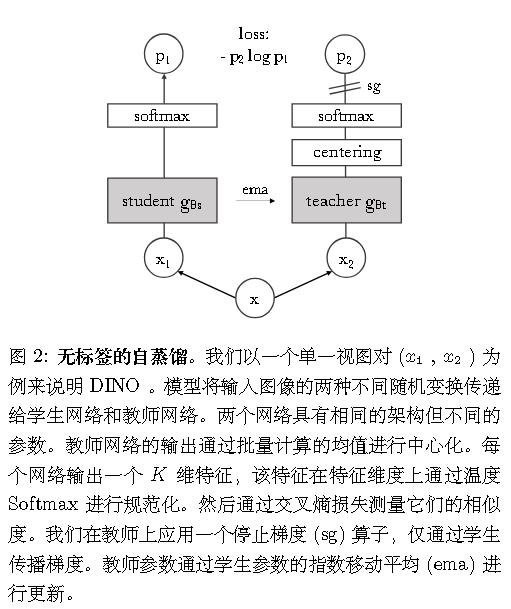

实验

iBOT
iBOT使用了v1的思想,且后续的DINO基于iBOT,所以我们需要先介绍一下这承上启下的iBOT。
字节跳动出品。
iBOT = image BERT 预训练结合 Online Tokenizer
模型
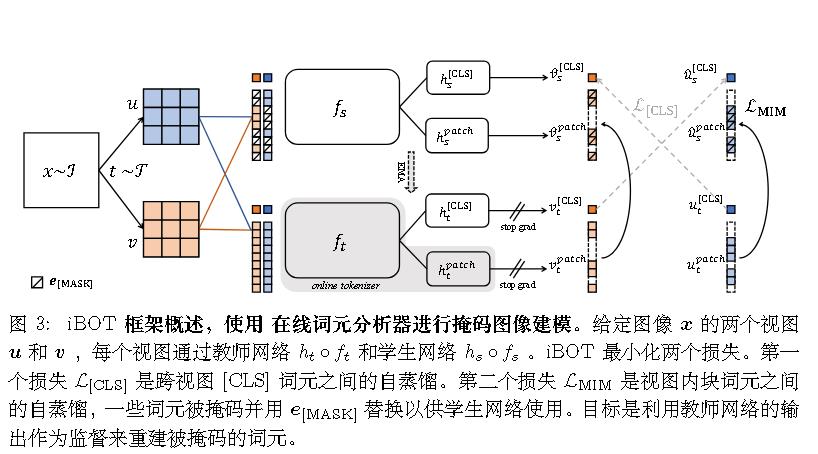
它与何恺明的MAE有些相似,不过何恺明一贯的更简单。
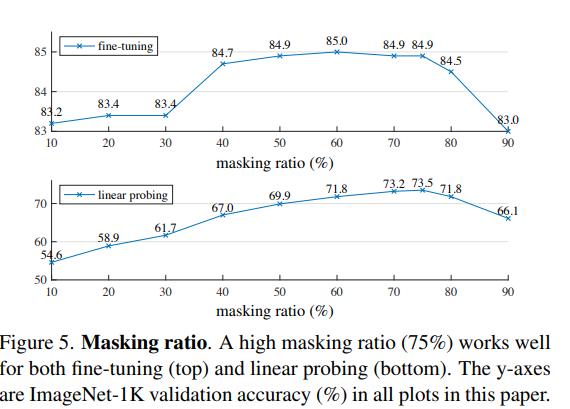
MAE发现mask 75%效果最好。
而iBOT没有这样的勇气,只选择0.5的概率mask,且这部分以均匀采样的方式从范围 [0.1 , 0.5 ] 中选取的mask比率。故iBOT通过加大模型复杂度来获取高性能。
DINO V2
通过一种判别式的自监督方法学习特征,这种方法可以看作是 DINO 和 iBOT 损失的结合,并带有SwAV的中心化。还添加了一个正则化项以扩展特征,并进行一个短时的高分辨率训练阶段。
数据搜集
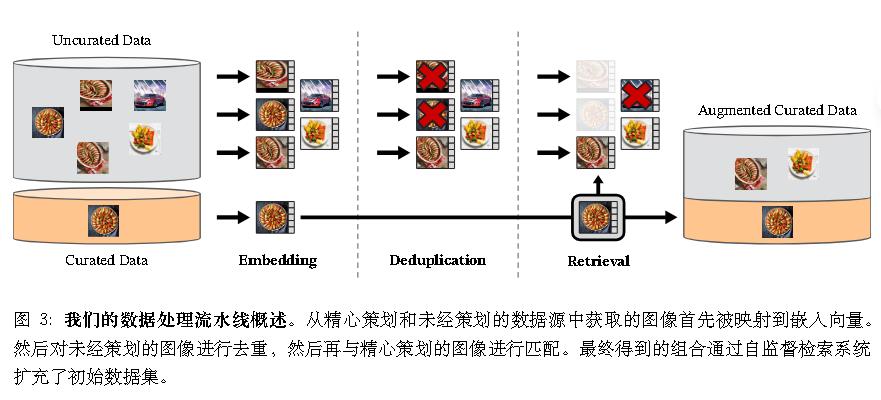
数据集来源。精选的数据集其中包含 ImageNet-22k、ImageNet-1k 的训练集、Google Landmarks 以及几个细粒度数据集。对于未经整理的数据源,从公开可用的爬取网络数据存储库中收集了一个原始的未过滤图像数据集。从存储库中的每个网页提取 <img> 标签中的图像 URL 链接。丢弃那些不安全或受领域限制的 URL,并对下载的图像进行后处理(PAC 哈希去重、NSFW 过滤和模糊处理可辨认的面部)。这导致了 12 亿张独特的图像。
去重。 将 Pizzi的复制检测流水线应用于未经整理的数据,并去除近似重复的图像。还去除了任何本工作中使用的基准测试或验证集中包含的图像的近似重复项。
Self-supervised image retrieval。 通过从非精选数据源中检索与精选来源中的图像接近的图像来构建精心策划的预训练数据集。为了实现这一点,首先使用在 ImageNet-22k 上预训练的自监督 ViT-H/16 网络计算图像嵌入,并使用余弦相似度作为图像之间的距离度量。然后,对非精选数据进行 k-均值聚类。给定一个用于检索的查询数据集,如果它足够大,为每个查询图像检索 N (通常是 4 个)最近邻图像。如果它较小,从与每个查询图像对应的簇中采样 M 张图像。
模型
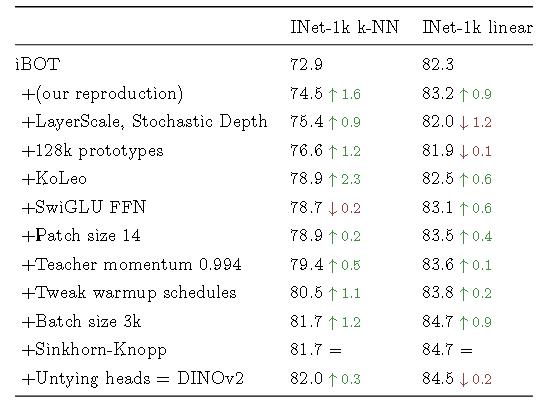
与iBOT的比较。
随机掩码一些输入patches提供给学生,但不提供给教师。
加入了 Koleo 正则化项(《Spreading vectors for similarity search》)。
使用了Swav的Sinkhorn-Knopp centering 。
1 | |
增加图像分辨率。增加图像分辨率对于分割或检测等像素级下游任务至关重要,因为在低分辨率下小物体可能会消失。然而,在高分辨率下训练既耗时又占用大量内存,因此在预训练的最后阶段短暂地将图像分辨率提高到 518 × 518。
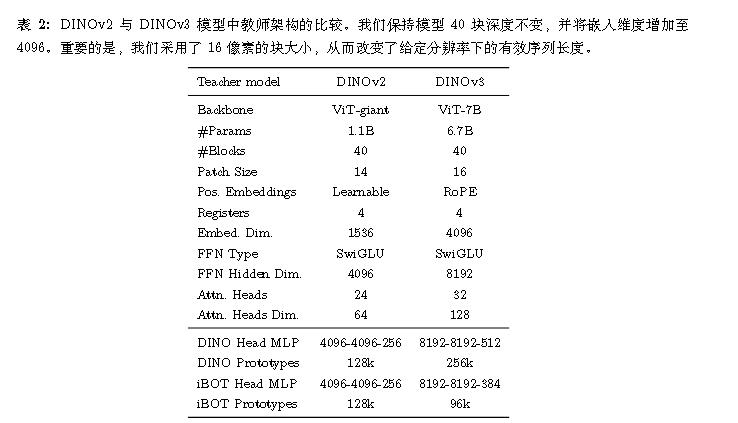
DINO V3
将自监督学习(SSL)扩展到大型前沿模型。
这篇主要是将DINOV2 scale up和使用了更多的tricks。
数据准备
数据采集与整理。第一部分,通过应用基于层次化 k -means 的自动筛选方法构建。采用 DINOv2 作为图像嵌入,并使用 5 级聚类,从最低到最高级别的簇数分别为 200 M、8 M、800 k、100 k 和 25 k。在构建簇的层次结构后,应用了 平衡采样算法。这生成了一个包含 16.89 亿张图像的精选子集(命名为 LVD-1689M),确保了对网络上所有视觉概念的平衡覆盖。
第二部分,采用了与 Oquab 提出的程序类似的基于检索的筛选系统。从数据池中检索与选定种子数据集相似的图像,创建了一个覆盖与下游任务相关的视觉概念的数据集。
第三部分,使用了包括 ImageNet1k 、ImageNet22k 和 Mapillary 街景序列在内的原始公开计算机视觉数据集。
模型
加大参数。
加入了 Koleo 正则化项(《Spreading vectors for similarity search》)。
引入的正则化项,旨在使点在 $\mathcal{S} _ {d _ {out}}$ 上均匀分布。
在了解点密度 $p$ 的前提下, 可以直接最大化微分熵 $- \int p(u)\log(p(u))du$。
仅给定样本 $(f(x_1),…,f(x_n))$ 时, 采用微分熵的估计量作为代理。
Kozachenko 和 Leononenko证明, 定义 $\rho _ {n,i} = \min _ {j\neq i}||f(x_i)-f(x_j)||$ 后,该分布的微分熵可通过以下方式估计:
$$
H_n = \alpha_n \frac{1}{n} \sum _ {i=1}^n \log(\rho _ {n,i}) + \beta_n
$$其中 $\alpha_n$ 和 $\beta_n$ 是两个依赖于样本数量 $n$ 和数据维度 $d _ {out}$ 的常数。
忽略仿射项, 将熵正则化项定义为
$$
\mathcal{L} _ {KoLeo} = -\frac{1}{n} \sum _ {i=1}^n \log(\rho _ {n,i})
$$该损失项具有令人满意的数学解释:最近邻点被推开,其强度是非递减且凹的。
这确保了回报递减:随着点之间的距离增大,进一步增加距离的边际影响会逐渐减小。
采用了 RoPE-box 抖动。坐标框 [−1, 1]被随机缩放到 [−s, s],其中 s ∈ [0.5, 2]
为了确保训练正常启动,仍然对学习率和教师温度使用线性预热。遵循常见做法,使用 AdamW,并将总批量大小设置为 4096 张图像,分布在 256 个 GPU 上。采用多裁剪策略训练模型,每张图像取 2 个全局裁剪和 8 个局部裁剪。对于全局/局部裁剪,使用边长为256/112 像素的方形图像。
Gram 锚定
我们在之前的博客中已经介绍,故不再详细解释。
后训练
包括一个高分辨率适应阶段,以实现不同输入分辨率下的有效推理,模型蒸馏生成高质量且高效的小尺寸模型,以及文本对齐为 DINOv3 添加 zero-shot 能力。
分辨率缩放
通过高分辨率适应步骤 (Touvron et al., 2019) 扩展了训练方案。为了确保在一系列分辨率下的高性能,采用了混合分辨率,在每个小批量中采样不同大小的全局和局部裁剪。具体来说,从 {512, 768} 的全局裁剪大小和从 {112, 168, 224, 336} 的局部裁剪大小,并额外训练模型 10k 次迭代。
与主训练阶段相似,此高分辨率适应阶段的一个关键组成部分是引入 Gram 锚定,采用 7B 教师作为 Gram教师。缺少这一部分,模型在稠密预测任务上的性能会显著下降。Gram 锚定促使模型在空间位置上保持一致且稳健的特征相关系数,这对于处理高分辨率输入带来的复杂性至关重要。
模型蒸馏
蒸馏方法采用了与初始训练阶段相同的训练目标,确保了学习信号的一致性。然而,不同于依赖模型权重的指数移动平均(EMA),作者直接使用 7B 模型作为教师模型来指导较小的学生模型,在此过程中,教师模型保持固定。由于未观察到补丁级别的一致性问题,因此未应用 Gram 锚定技术。
将 DINOv3 与文本对齐
有研究表明,利用预训练的自监督视觉骨干网络可以实现有效的图像-文本对齐。这使得在多模态情景中利用这些强大模型成为可能,促进了超越全局语义的更为丰富和精确的文本到图像关联,同时由于视觉编码已预先学成,还降低了计算成本。
采用先前在Jose等人中提出的训练策略(《DINOv2 meets text: A unified framework for image-and pixel-level vision-language alignmen》)将文本编码器与DINOv3 模型对齐。

该方法遵循 LiT 训练范式,从头开始训练文本表示,以通过对比目标将图像与其标题匹配,同时保持视觉编码器冻结。为了在视觉方面提供一定的灵活性,在冻结的视觉骨干之上引入了两个Transformer层。该方法的一个关键增强是在与文本嵌入匹配之前,将平均池化的补丁嵌入与输出的 CLS token 进行拼接。