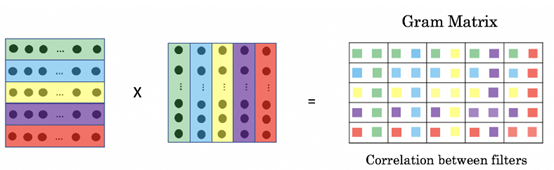
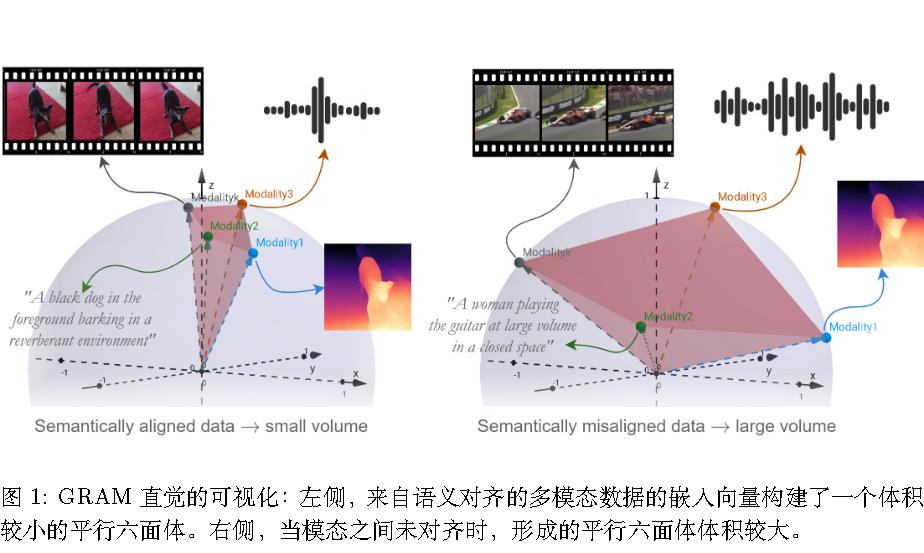
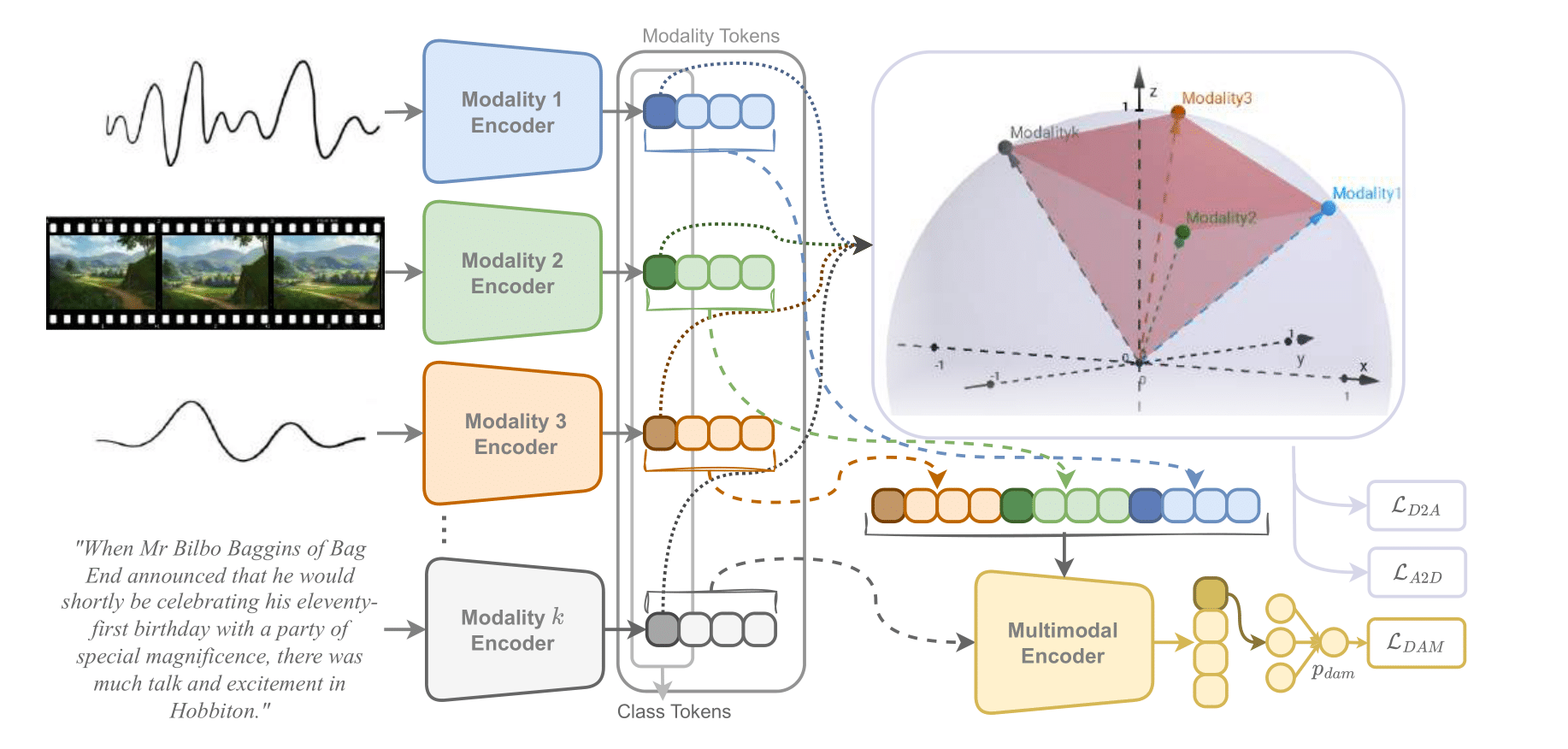
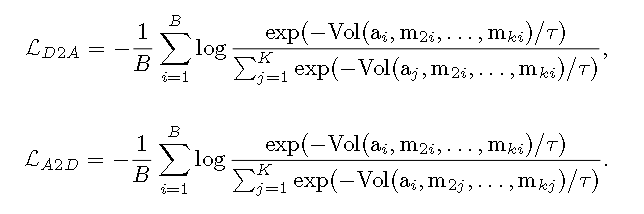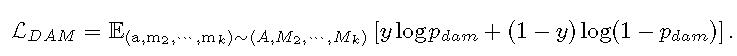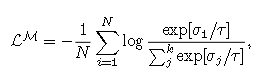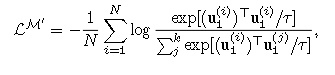GRAM 在高维空间中直接学习并对齐 n 种模态,通过最小化由模态向量张成的 k 维平行多面体的格拉姆体积,确保所有模态同时几何对齐。GRAM 可以在任何下游方法中替代余弦相似度,适用于 2 到 n 种模态,并提供相较于以往相似度度量更有意义的对齐。基于 GRAM 的新型对比损失函数增强了多模态模型在高维嵌入空间中的对齐。
defvolume_computation(anchor, *inputs): """ General function to compute volume for contrastive learning loss functions. Compute the volume metric for each vector in anchor batch and all the other modalities listed in *inputs.
Args: - anchor (torch.Tensor): Tensor of shape (batch_size1, dim) - *inputs (torch.Tensor): Variable number of tensors of shape (batch_size2, dim)
Returns: - torch.Tensor: Tensor of shape (batch_size1, batch_size2) representing the volume for each pair. """ batch_size1 = anchor.shape[0] batch_size2 = inputs[0].shape[0]
# Compute pairwise dot products for language with itself aa = torch.einsum('bi,bi->b', anchor, anchor).unsqueeze(1).expand(-1, batch_size2)
# Compute pairwise dot products for language with each input l_inputs = [anchor @ input.T forinputin inputs]
# Compute pairwise dot products for each input with themselves and with each other input_dot_products = [] for i, input1 inenumerate(inputs): row = [] for j, input2 inenumerate(inputs): dot_product = torch.einsum('bi,bi->b', input1, input2).unsqueeze(0).expand(batch_size1, -1) row.append(dot_product) input_dot_products.append(row)
# Stack the results to form the Gram matrix for each pair G = torch.stack([ torch.stack([aa] + l_inputs, dim=-1), *[torch.stack([l_inputs[i]] + input_dot_products[i], dim=-1) for i inrange(len(inputs))] ], dim=-2)
# Compute the determinant for each Gram matrix gram_det = torch.det(G.float())
# Compute the square root of the absolute value of the determinants res = torch.sqrt(torch.abs(gram_det)) return res
Integrating PMRL with four steps # 1. Singular Value Decomposition on Multimodal Representations >>> U, S, _ = torch.linalg.svd( torch.stack ([ feat_t ,feat_v ,feat_a ,feat_s], dim =-1) ) # 2. Principled learning via maximum singular values >>> loss1 = F. cross_entropy (S/self.tau1 , torch.zeros(S.shape [0]).to(S.device).long ()) # Implemented by cross -entropy , and the singular value at the first position is the maximum one # 3. Principled regularization via eigenvector corresponding to the maximum singular values >>> U1 = U[:, :, 0] loss2 = F. cross_entropy ((U1 @ U1.T)/self.tau2 , torch.arange(U1.shape [0]).to(U1.device ).long ()) ...... # 4. Combine the loss >>> loss = loss1 + self. lambda1 * loss2 + self. lambda2 * loss_IM
defforward(self, output_feats, target_feats, img_level=True): """Compute the MSE loss between the gram matrix of the input and target features.
Args: output_feats: Pytorch tensor (B, N, dim) or (B*N, dim) if img_level == False target_feats: Pytorch tensor (B, N, dim) or (B*N, dim) if img_level == False img_level: bool, if true gram computed at the image level only else over the entire batch Returns: loss: scalar """
# Dimensions of the tensor should be (B, N, dim) if img_level: assertlen(target_feats.shape) == 3andlen(output_feats.shape) == 3