InLine attention:弥合Softmax与线性注意力机制的差距
(NeurIPS 2024)
引言
作者指出:
(1)单射性是线性注意力与 Softmax 注意力之间的关键差异。虽然 Softmax 注意力具有单射性,但线性注意力的非单射性会导致语义混淆,并严重损害模型性能。
首次将注意力概念化为映射函数,并证明了其单射性的重要性。
(2)局部建模对于注意力机制的有效性仍然至关重要,尽管它以其大感受野和出色
的长程建模能力而闻名。
线性注意力
博客之前介绍过线性注意力从$sim(Q,K)=softmax(QK^T/\sqrt{d})$变为$sim(Q,K)=\phi(Q)\phi(K)^T$,从而能先计算KV而不是QK来减少计算复杂度。
注意力函数的单射性
作者证明了,Softmax 注意力是单射的,但线性注意力不是单射的。
如下图所示,线性注意力无法区分具有不同强度的相同语义。
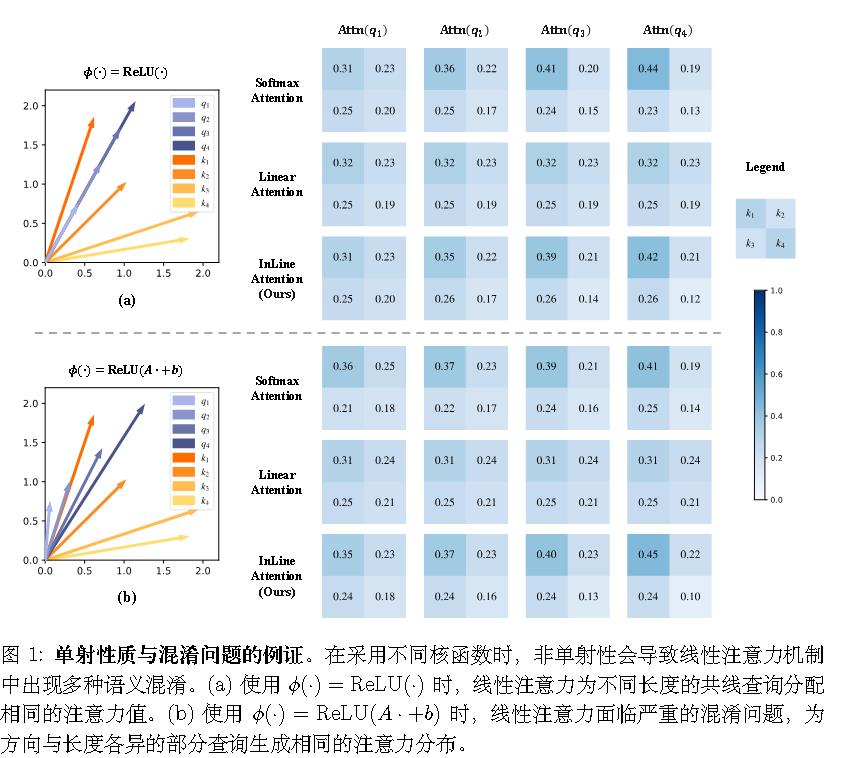
作者通过往softmax的输入前加入非单射函数,结果发现准确率下降了,认定注意力函数单射属性的关键作用。
赋予线性注意力单射性
最简单的解决方法就是使线性注意力拥有单射性,作者简单地将线性注意力的规范化从除法变换为减法,提出了单射线性注意力(InLine):
$$
InL_K(Q_i)=[\phi(Q_i)^T\phi(K_1),…\phi(Q_i)^T\phi(K_N)]^T-\frac{1}{N}\sum_{s=1}^N \phi(Q_i)^T\phi(K_s)+\frac{1}{N}
$$
局部建模能力
Softmax 注意力为局部窗口分配了
大量的注意力,表明其相较于其他两种注意力范
式具有更强的局部建模能力。

两个关键观察结果显现:
- 屏蔽局部 token 会显著降低模型性能,而随机屏蔽相同数量的 token 对结果影响较小。
- 当局部 token 被屏蔽时,Softmax 注意力机制的性能比 InLine 注意力机制受到更严重的影响。这些发现证明了局部建模对于两种注意力机制的重要性,并证明了 Softmax 注意力机制相对于 InLine 注意力机制的优势主要归因于其更强的局部建模能力。
赋予线性注意力单射性
作者采用MLP 来预测 InLine 注意力的额外局部注意力残差。
具体而言,
$$
O_i=InL_K(Q_i)^TV+\sum_{j=1}^9r_jV_j^{N(i)},r=MLP(\bar x)
$$
V代表3*3领域内的值$Q_i$。
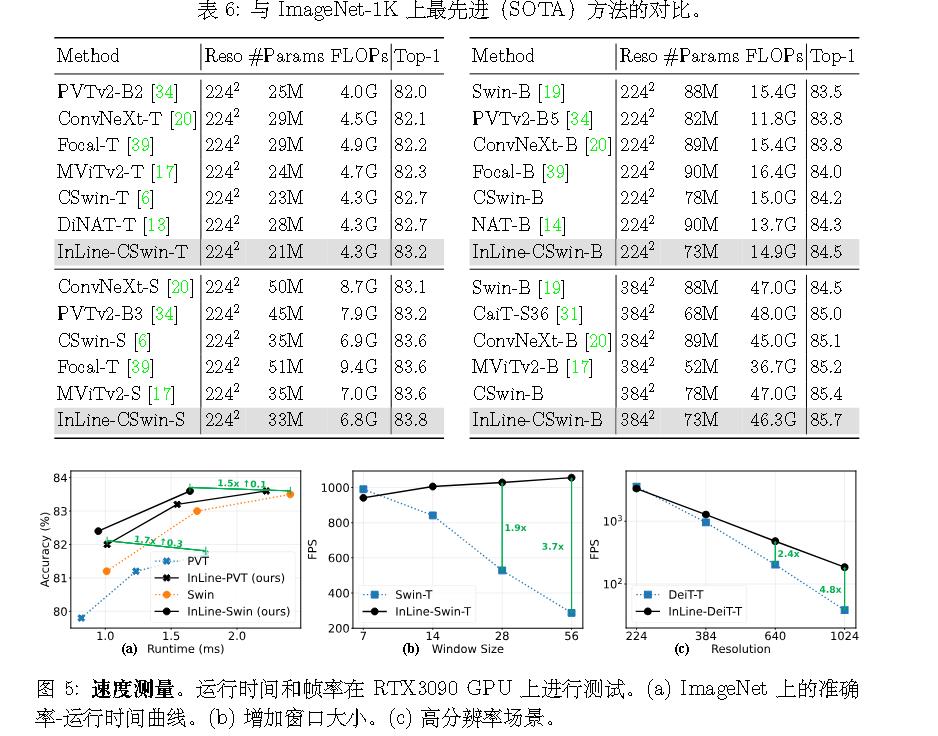
实验