Ecotransformer-无需乘法的注意力机制
(arxiv 2025)2507.20096
众所周知,注意力为$softmax(\frac{QK^T}{\sqrt{D_k}})V$。
而QK内积可以写为$<Q,K>=\frac{1}{2}(||Q||^2_2+||K||^2_2-||Q-K||^2_2)$。
若Q、K被L2规范化,则括号内前两项为常数,化简后最终为$softmax(\frac{-1}{2/\sqrt{D}}||Q-K||^2_2)$。
于是作者把其扩充为softmax(QK距离),作者使用了L1距离乘上$\lambda$系数。
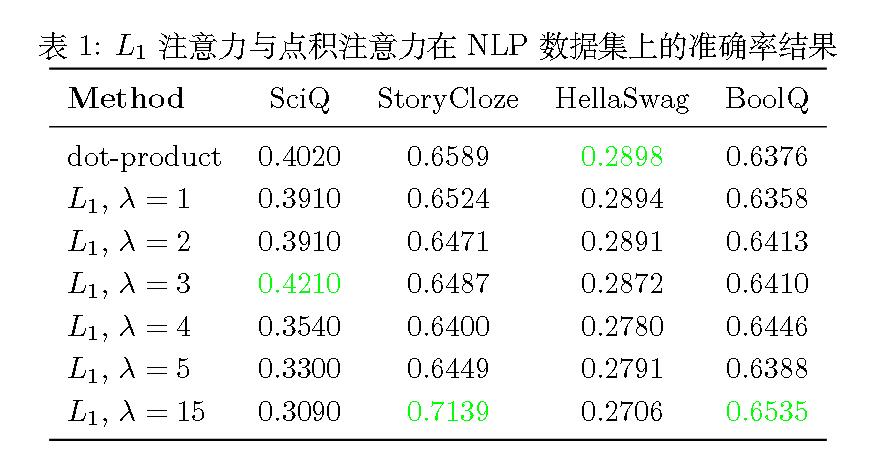
评价
思路其实比较简单。
在此之前也有《Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet》干脆全用FFN。
和用逐元素乘法代替点积的AFT,不过被ICLR 2021 拒了。
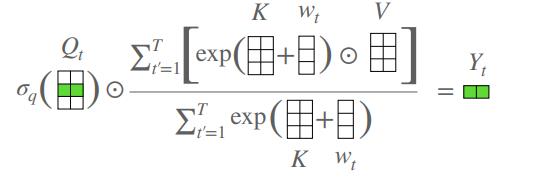
Ecotransformer-无需乘法的注意力机制
https://lijianxiong.space/2025/20250807/