多模态对抗攻击与防御速览
视觉-语言预训练模型(VLP安全)
共41篇论文。
目录
[TOC]
预备知识
多模态一系列模型
李沐老师的《多模态论文串讲》或博客上的《多模态速览》
BERT-attack
(EMNLP 2020)
利用以 BERT为代表的预训练掩码语言模型生成对抗样本。
1.计算重要性分数
把这个词从句子中去掉(用一个无意义的词如 [MASK] 替换),然后看模型的预测结果与正确标签 Y 的置信度下降了多少。下降得越多,说明这个词越重要。
2.筛选关键词
在计算完所有词的重要性分数后,算法会根据分数从高到低进行排序。
3.为重要词寻找最佳替换
如果 w_j 是一个完整的词(没有被切分成子词),就直接筛选候选词。
如果 w_j 被切分成了多个子词,算法会使用 PPL (Perplexity,困惑度) 来进行排序和筛选。
分词后的序列$X=(x_0,x_1,…,x_t)$的ppl计算公式为:
$$
PPL(x)=exp(-\frac{1}{t}\sum _ {i}^tlogp_\theta(x_i\mid x _ {<i}))
$$
2
3c_loss = nn.CrossEntropyLoss(reduction='none')
ppl = c_loss(word_predictions.view(N*L, -1), all_substitutes.view(-1)) # [ N*L ]
ppl = torch.exp(torch.mean(ppl.view(N, L), dim=-1)) # N
4.攻击
遍历候选替换词集合 C 中的每一个词 c_k。
用候选词 c_k 替换掉原句中的重要词 w_j,生成一个新句子 S'。
将新句子 S' 输入模型进行预测。如果模型的预测结果 不再是 正确标签 Y,则攻击成功。

Projected Gradient Descent(PGD)
(ICLR 2018)
梯度攻击常用方法。
在此之前有快速梯度符号方法(FGSM)等方法,具体而言,取梯度的符号方向,并乘以一个小的超参数。
$$
x+\epsilon sgn(\nabla_xL(\theta,x,y))
$$
PGD可以被看作是FGSM的迭代版本。
初始化: 在原始样本x的$\epsilon$-邻域内随机选择一个初始点$x _ {adv(0)}$。这个随机初始化有助于避免陷入局部最优。
$$
x _ {adv(0)}=x+\text{random_perturbation}
$$
迭代更新: 在进行T次迭代的每一步t中:
计算损失函数关于当前对抗样本$x _ {adv}^{(t)}$的梯度: $$ g^{(t)} = \nabla _ {x _ {adv}^{(t)}} J(\theta, x _ {adv}^{(t)}, y _ {true}) $$
沿着梯度符号方向更新对抗样本,步长为$\alpha$: $$ x _ {adv}^{(t+1)} = x _ {adv}^{(t)} + \alpha \cdot \text{sign}(g^{(t)}) $$
将更新后的样本投影回原始样本x的$\epsilon$-邻域内。
L∞范数的话,投影操作为: $$ x _ {adv}^{(t+1)} = x+\text{clip}(x _ {adv}^{(t+1)}-x, - \epsilon, + \epsilon) $$
L2范数的话,投影操作为: $$ x _ {adv}^{(t+1)} = x+(x _ {adv}^{(t+1)}-x)\cdot\text{min}(1,\frac{\epsilon}{||x _ {adv}^{(t+1)}-x||_2})$$
其实就是把它clip到扰动范围内。
直接来看代码:
1 | |
对抗攻击
白盒攻击
不可见
(ACMMM 2022)Towards adversarial attack on vision language pre-training models
Co-attack
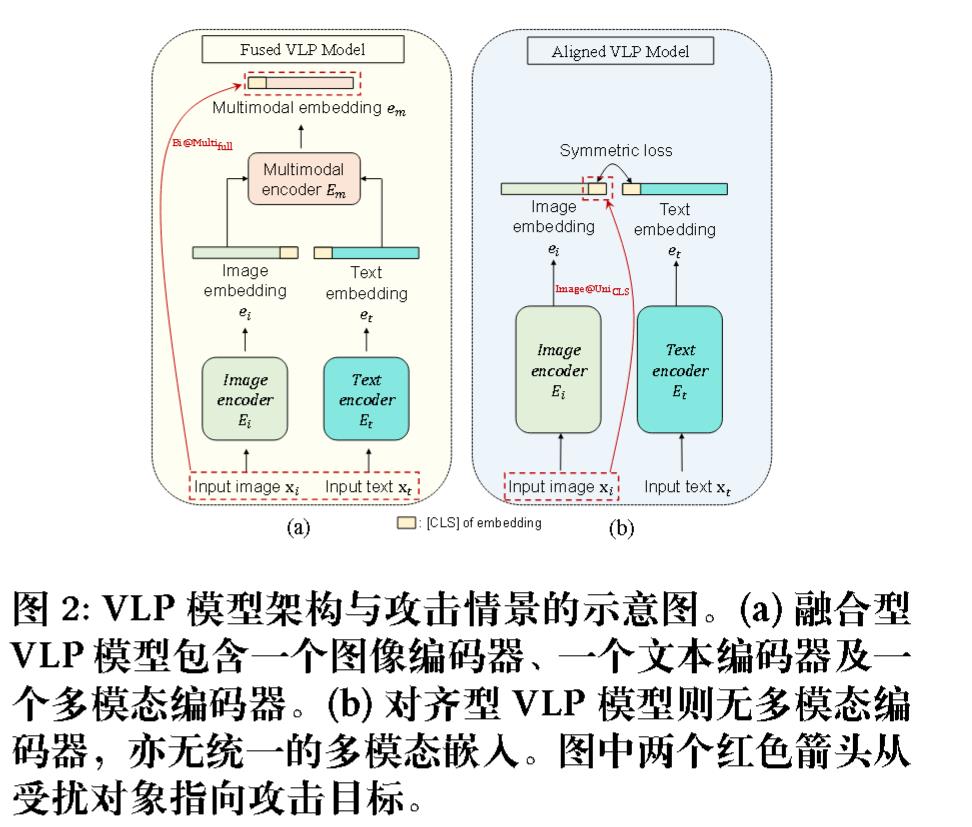
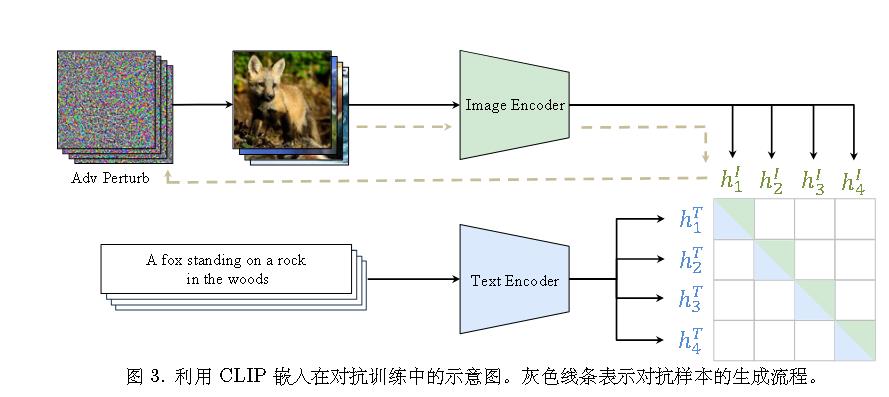
攻击多模态嵌入(Attacking Multimodal Embedding)
Co-Attack 的目标是促使被扰动的多模态嵌入偏离原始多模态嵌入。其损失函数定义为:
$$ \text{max } \mathcal{L}(E_m(E_i(x_i’), E_t(x_t’)), E_m(E_i(x_i), E_t(x_t))) + \alpha_1 \mathcal{L}(E_m(E_i(x_i’), E_t(x_t’)), E_m(E_i(x_i), E_t(x_t))) $$
这里:
- $E_m(\cdot, \cdot)$ 代表多模态编码器。
- $E_i(\cdot)$ 代表图像编码器。
- $E_t(\cdot)$ 代表文本编码器。
- $x_i$ 是原始输入图像。
- $x_t$ 是原始输入文本。
- $x_i’$ 是扰动后的图像。
- $x_t’$ 是扰动后的文本。
- $\mathcal{L}$ 是一个损失函数,通常用于衡量嵌入之间的差异(例如,KL散度损失)。
- $\alpha_1$ 是一个超参数,控制第二项的贡献,第二项对应 $\delta _ {i\&t}$,表示图像和文本扰动产生的合扰动。
该优化问题通常通过类似 PGD 的程序解决。
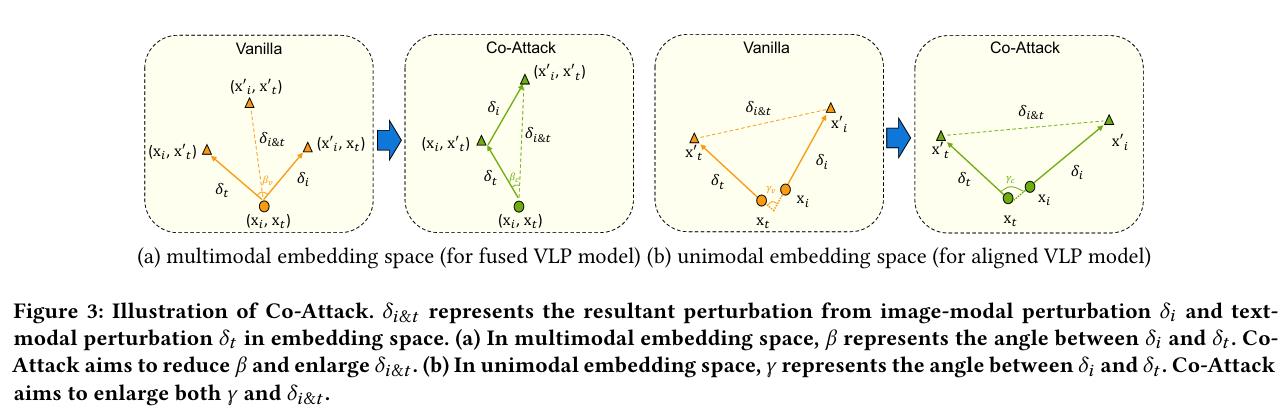
攻击单模态嵌入(Attacking Unimodal Embedding)
Co-Attack 旨在促使被扰动的图像模态嵌入偏离被扰动的文本模态嵌入。其损失函数定义为:
$$ \text{max } \mathcal{L}(E_i(x_i’), E_i(x_i)) + \alpha_2 \cdot \mathcal{L}(E_i(x_i’), E_t(x_t’)) $$
在这两种情况下,攻击流程都是先扰动离散的文本输入,然后根据文本扰动的结果扰动连续的图像输入 。对于图像扰动,通常使用基于梯度的 PGD 攻击。对于文本扰动,则使用 BERT-Attack 方法。
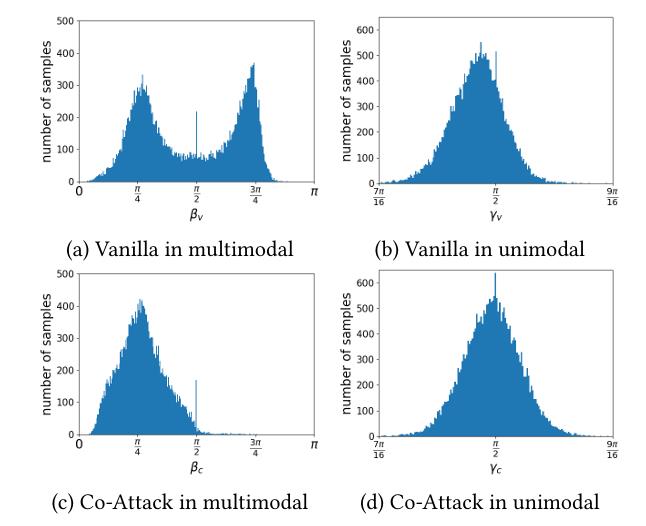
CoAttack能拉大距离和夹角。
论文中其实没有从理论上解释为什么能做到。只通过做实验表明,可以发现平均角度都提高了。
(ACM MM 2023)Advclip: Downstream-agnostic adversarial examples in multimodal contrastive learning
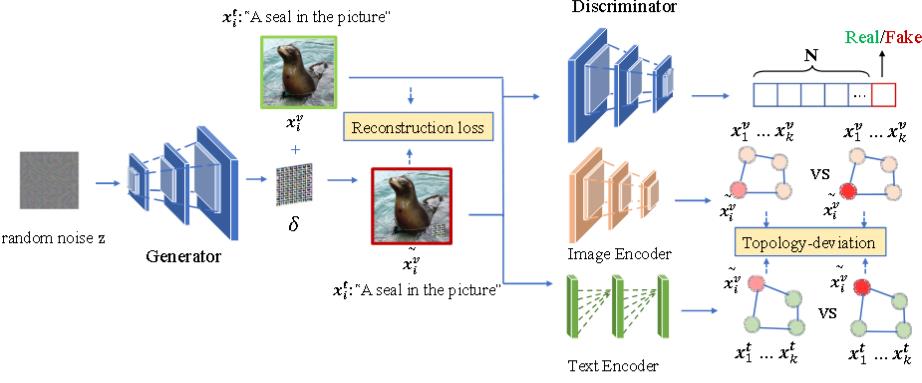
AdvCLIP使用了GAN来生成一个通用对抗补丁将其加到数据集的图像上,从而得到一个对抗样本。
$$
\tilde{x_i^v}=x\odot(1-m)+G(z)\odot m
$$
我们直接从损失函数来看是如何构建模型和训练模型的。
除了GAN的G损失和D损失,还有:
重建损失:$||\tilde{x_i^v}-x||_2$
对比损失:即,使用InfoNCE来衡量编码器输出的向量之间的相似度。
具体而言,拉大将良性图像和对抗图像的特征距离。由于InfoNCE不是对称的,所以要正反共计算两次损失函数。
拓扑偏差损失:
也就是对应图中的Topology-deviation。旨在破坏对抗样本与其对应正常样本之间的拓扑相似性,即在表示空间中基于样本间相似度构建的邻域关系图。
论文里是这么说的。构件图后,再通过交叉熵计算正常图和对抗图的损失函数。

似乎和代码有些不同,我们直接来看代码。
首先要进行进行归一化。
接着计算点积,$S=OO^T$。再将其转为距离,$D=1-S$。并给每个点到自身的距离(即对角线元素)临时设置为一个很大的数(这里是3)。
定义$\rho_i$为最近的正距离$\rho=\text{min}D$。再把它转为新的相似度矩阵,$S=1-(D-\rho)$。
S的范围是-1到1,$\frac{S+1}{2}$把S转为[0,1]上。最好再把它进行行归一化,这就是定义的概率(因为概率要满足sum为1。)
然后就是计算交叉熵了。
1 | |
可见
(arxiv 2021)Reading isn’t believing: Adversarial attacks on multi-modal neurons
作者发现在CLIP模型中,文本标签可以覆盖纹理和图像形状。当CLIP模型读取标签、看到纹理 并分类形状时,这种对抗性攻击风格会获得额外的选项。
比如我们明目张胆给图像加入一个文本标签,结果CLIP直接把标签当做正确的。

哪怕打错字,也有效。

字体越大越有效。

黑盒攻击
样本级扰动
(ICCV 2023)Set-level guidance attack: Boosting adversarial transferability of vision-language pre-training models
首次对视觉语言预训练(VLP)模型中对抗样本的可迁移性进行了研究。
可迁移性
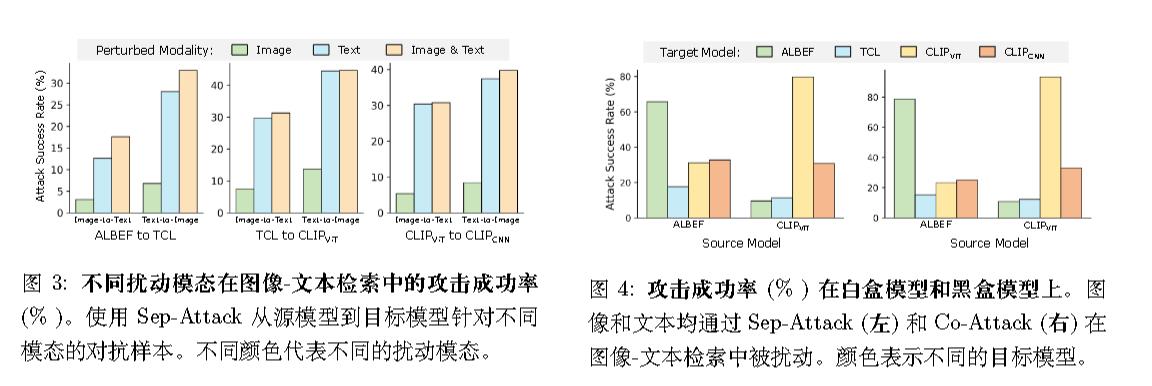
作者认为,对抗样本的迁移性退化主要是由于现有攻击方法的局限性:
- Sep-Attack 的一个主要局限性是它没有考虑不同模态之间的交互作用。作为一种针对每个模态的独立攻击方法,它无法建模在多模态学习中成功攻击至关重要的模态间对应关系。这在图像-文本检索等多模态任务中尤为明显,其中真实值不是离散标签(例如,图像分类),而是与输入模态相对应的另一种模态数据。Sep-Attack 中完全缺乏跨模态交互,严重限制了对抗样本的泛化能力,并降低了它们在不同 VLP 模型之间的迁移性。
- 虽然 Co-Attack 旨在利用模态之间的协作生成对抗样本,但它仍存在一个关键缺点,阻碍了其在其他 VLP 模型中的迁移性。与单模态学习不同,多模态学习涉及多个互补模态,并具有许多对许多的跨模态对齐,这给实现足够的对抗迁移性带来了独特的挑战。然而,Co-Attack 仅使用单个图像-文本对来生成对抗数据,限制了其他模态中多个标签提供的指导多样性。跨模态指导的这种缺乏多样性,使得对抗样本与白盒模型的对齐模式高度相关。因此,对抗样本的通用性受到限制,它们在迁移到其他模型时的效果也会下降。
算法
一些符号计法:
$B[,\epsilon]$表示合法搜索空间,$\epsilon$分别表示图像最大扰动范围或者文本中科改变单词的最大数量。
正如名字所说,“集合”,算法不是简单地针对单个图像和单个标题进行优化,而是构建了一个对抗性标题集合和一个图像集合,并利用这些集合来“引导”对抗性样本的生成,从而使攻击效果更稳定和强大。
第一步,使用余弦相似度来构建对抗性标题集合 t'。
第二步,通过加入高斯噪声来构建图像集合 v。
第三步,集合地生成对抗性图像和对抗性文本。

(arxiv 2023)Sa-attack: Improving adversarial transferability of vision-language pre-training models via self-augmentation
中山大学网安院长为通讯。未录用未公开代码。
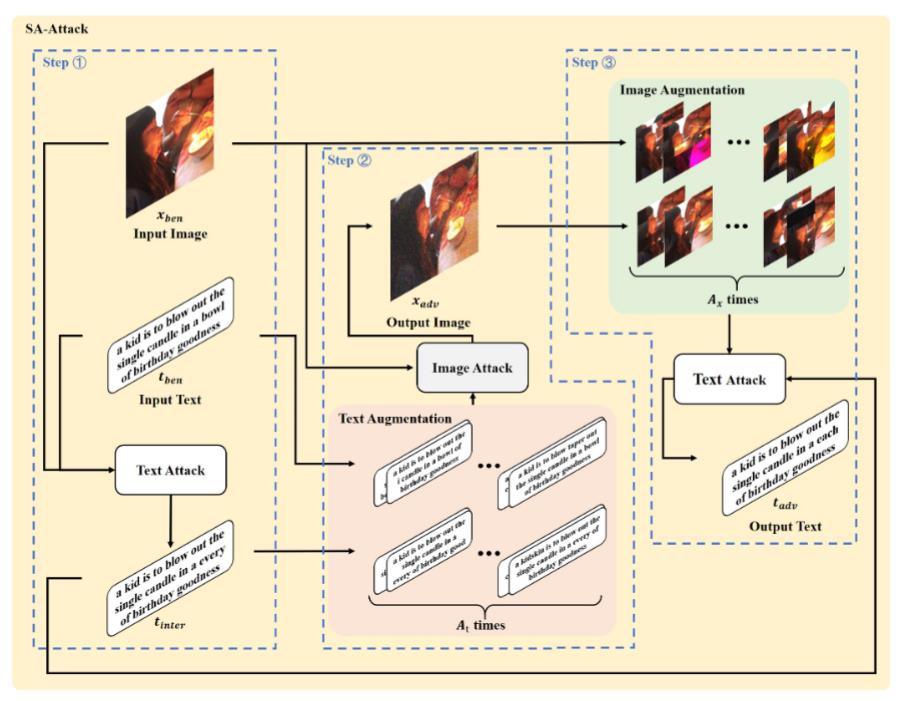
方法包含三个步骤:
- 从良性图像和良性文本中生成对抗性中间文本。
- 使用增强的良性文本和对抗性中间文本,结合良性图像,生成对抗性图像。¸
- 使用增强的良性图像和对抗性图像,结合对抗性中间文本,生成对抗性文本。不同颜色代表不同模块。图中各变量的描述见表
其他部分和上一篇类似。
主要区别有几个,噪声改为均值为0,方差为0.05的均匀分布,并会对图像的clip到[0,1]。
(TMM 2023)Exploring transferability of multimodal adversarial samples for vision language pre-training models with contrastive learning
两大贡献
(1) 通过将扰动优化与多模态对抗样本生成统一于一个基于梯度的框架中,能够更有效地攻击那些语义相似的多模态信息中的脆弱点。
(2) 运用对比学习,从多角度扰动良性样本的内在结构及图文对的上下文一致性,从而提升了生成的多模态对抗样本的可迁移性。
算法
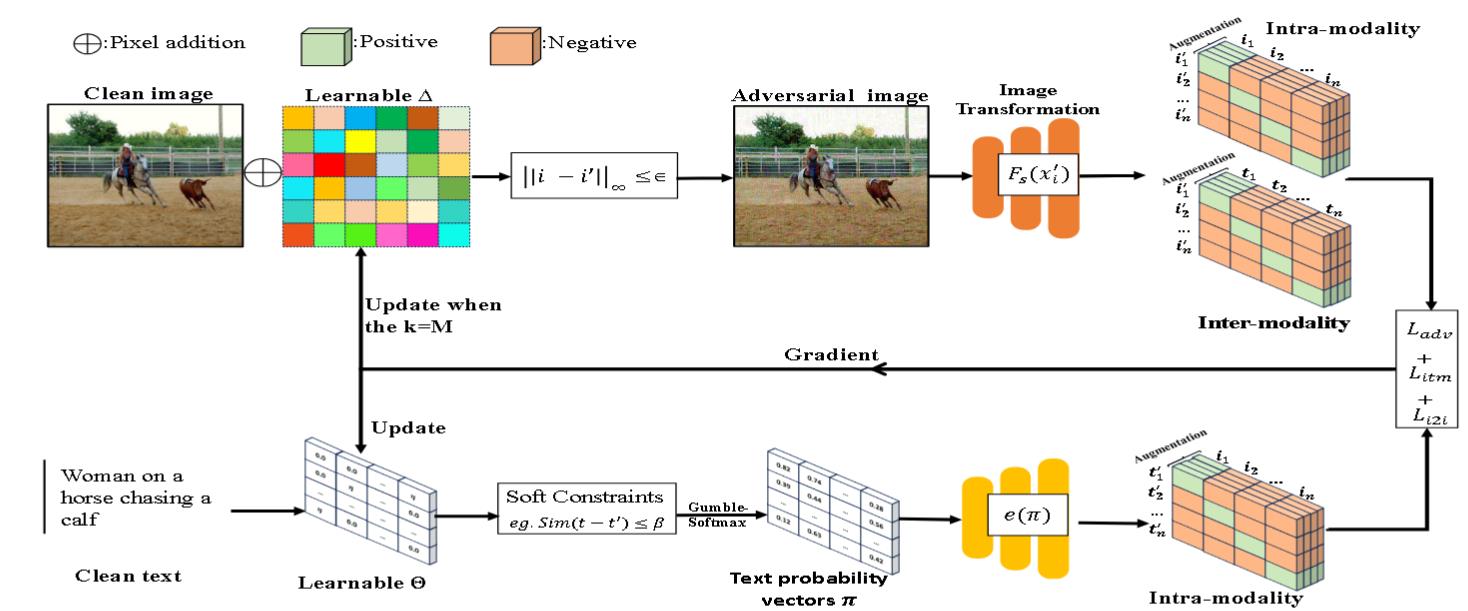
使用$L_\infty$来约束对抗扰动。通过最大化给定前序 token 的似然来约束t′的流畅性。使用BERT 得分来约束对抗文本t'。
图像-文本语义相似度损失$L _ {adv}$:
$$
L _ {adv} = \begin{cases}
\min J(F_s(i’), F_s(t’)) \\
\text{s.t. } |i’ - i| _ {\infty} \leq \epsilon \\
\text{s.t. } \text{similarity}(t’, t) \leq \beta
\end{cases}
$$
软约束损失$L _ {prep}$:
由于文本的离散性,所以需要将文本转为连续分布。
采用Gumbel-Softmax来建模文本数据。
具体而言,对于一个词序列$t=[\omega_1,\omega_2,…,\omega_n]$,其中每个$\omega_j$属于固定词表V,使用由矩阵$\Theta\in R ^ {n\times V}$参数化的Gumbel-Softmax分布$P _ {\theta}$。用于采样$\pi$。
$$
\begin{align}
(\pi_k)_j &= \frac{\exp((\Theta _ {k,j} + g _ {k,j})/\tau)}{\sum _ {\nu=1} ^ {V} \exp((\Theta _ {k,\nu} + g _ {k,\nu})/\tau)}
\\e(\pi) &= e(\pi_1) \cdots e(\pi_n)
\end{align}
$$
其中$g _ {k,j}\sim Gumbel(0,1)$。
上面第一条式子其实就是Gumbel Softmax,具体而言,$softmax((logp_i-log(-log\epsilon_i))/\tau),\epsilon\sim U[0,1]$。
Gumbel 分布的分布函数为$F(x;\mu,\beta)=e ^ {-e ^ {-(x-\mu)/\beta}}$。若想从中采样,则$x=F ^ {-1}(u)=\mu-\beta ln(-ln(u)),u\sim U(0,1)$。
证明:
$$
P(F ^ {-1}(u)\leq x)=P(u\leq F(x))=F(x)
$$
为了生成对抗文本的流畅性,在给定前序 token 时最大化下一个 token 预测的似然。
$$
L _ {prep}(\pi)=-\sum _ {k=1} ^ {n} log p _ {dis}(\pi_k\mid \pi_1 …\pi _ {k-1})
$$
其中log是下一个词分布与先前预测词分布之间的交叉熵。
采用下式来计算 BERT 得分,用来保持语义一致性并约束语义鸿沟:
$$
L _ {sim}=\sum _ {k=1} ^ {n} w_k\cdot\text{max} _ {j=1,…,m}\phi(t)_k^T\phi(t’)_j
$$
$\phi$是生成embedding的语言模型。
跨模态对比损失$L _ {itm}$:
$$
L _ {nce}(i, t^+, t^-) = E \left[ \log \frac{e ^ {(sim(i, t^+)/\tau)}}{\sum _ {k=1} ^ {K} e ^ {(sim(i, \hat{t}_k)/\tau)}} \right]
$$
同样使用InfoNCE,并类似之前要计算两次。
$$
L _ {itm}=\frac{1}{2}[L _ {nce}(i’,i+,i-)+L _ {nce}(i’,i+,i-)]
$$
模态内对比损失$L _ {i2i}$:
同样使用InfoNCE,将同一模态中与良性样本语义不同的对抗样本推开。具体来说,将良性图像$i$在随机数据增强下的一些随机视图视为负例$i^-$ ,并从测试集中随机抽取图像作为正例。
(IEEE Computer Society 2024)Transferable multimodal attack on vision-language pre-training models
pass
(NeurIPS 2023)Vlattack: Multimodal adversarial attacks on vision-language tasks via pre-trained models
贡献
(1) 第一个探索预训练和微调的 VL 模型之间的对抗脆弱性的。
(2) 提出 VLAttack 从不同层次搜索对抗样本。对于单模态层次,提出 BSA 策略以在各种下游任务上统一扰动最优化目标。对于多模态层次,设计 ICSAC通过在不同模态上交叉搜索扰动来生成对抗图像-文本对。
算法
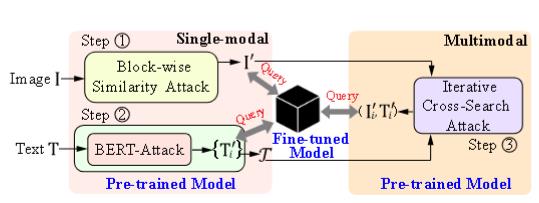
单模态:
图像攻击。作者提出了块级相似度攻击 (BSA) 来破坏通用的基于上下文的表示。
$$
\mathcal{L} = \underbrace{\sum _ {i=1}^{M _ {\alpha}} \sum _ {j=1}^{M_j^i} \text{Cos}(F _ {\alpha}^{i,j}(I), F _ {\alpha}^{i,j}(I’))} _ {\text{Image Encoder}} + \underbrace{\sum _ {k=1}^{M _ {\beta}} \sum _ {t=1}^{M_t^k} \text{Cos}(F _ {\beta}^{k,t}(I, T), F _ {\beta}^{k,t}(I’, T))} _ {\text{Transformer Encoder}}
$$
其中 $M _ {\alpha}$ 是图像编码器中的块数,$M_j^i$ 是在 $i\text{-th}$ 块中生成的展平图像特征嵌入的数量。类似地,$M _ {\beta}$ 是 Transformer 编码器中的块数,$M_t^k$ 是在 $k\text{-th}$ 块中生成的图像词元特征数。$F _ {\alpha}^{i,j}$ 是在图像编码器的 $i\text{-th}$ 层中获得的 $j\text{-th}$ 特征向量,$F _ {\beta}^{k,t}$ 是在 Transformer 编码器的 $k\text{-th}$ 层中获得的 $t\text{-th}$ 特征向量。图像编码器仅以单个图像 $I$ 或 $I’$ 作为输入,但 Transformer 编码器将同时使用图像和文本作为输入。采用余弦相似度来计算扰动特征与良性特征之间的距离。
使用PGD来进行迭代。
其实也还是前面的那一套。
文本攻击。直接应用 BERT-Attack 来生成文本扰动。
多模态:
从第一阶段生成的有效候选文本集 T 中,根据语义相似度得分 γi进行排序,选出最相似的 K个候选文本 {T’1, …, T’K}。
对于每一个顶级的候选文本 T’k: 协同优化。算法在已有的对抗性图像 I (来自第一阶段图像攻击的结果) 和当前的候选文本 T’k 的基础上,再次调用 BSA 函数。

(arxiv 2024)As firm as their foundations: Can open-sourced foundation models be used to create adversarial examples for downstream tasks?
哈佛大学出品。提出了“补丁表示错位”(Patch Representation Misalignment,PRM)的跨任务攻击策略。
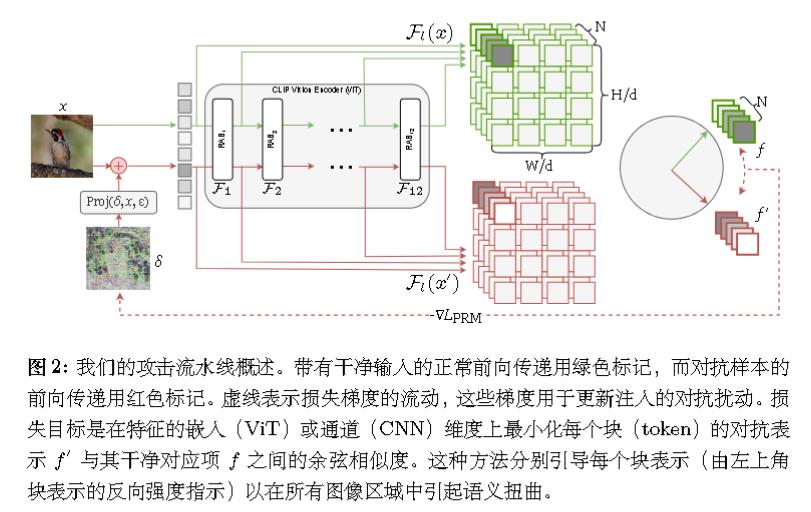
用 $F_l(x), F_l(x′) $来表示从第 l 层获得的中间编码器特征。

和前面的主要区别是对每层操作,而非对最后进行操作。
通用扰动
(拒ICLR 2025)One perturbation is enough: On generating universal adversarial pertur bations against vision-language pre-training models
算法
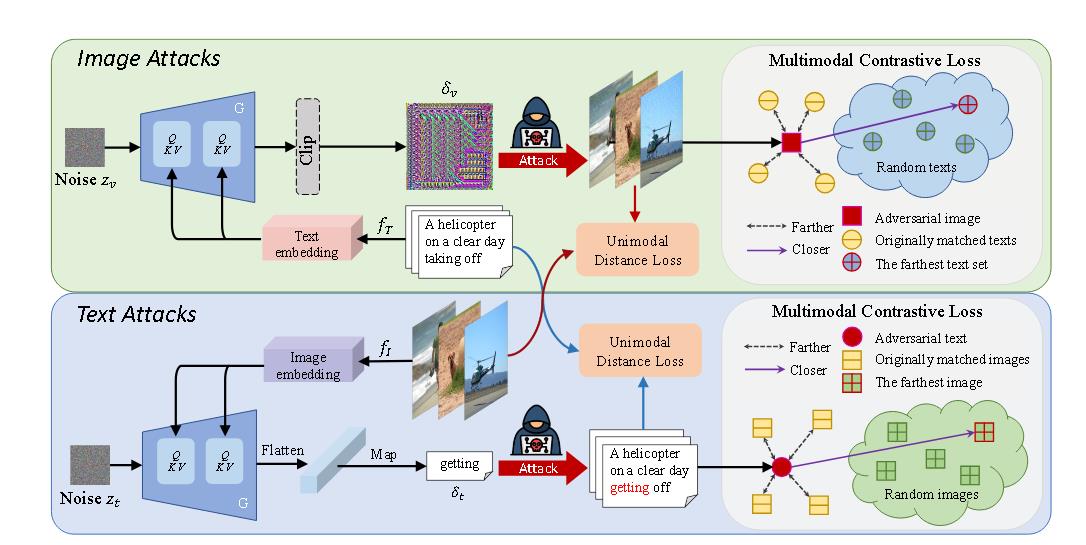
loss基本就是InfoNCE,范数损失那一套。还有用到了《Set-level guidance attack》中的集合思想。
创新点没看出来。除了使用Deepfool替换前人常用的PGD,然后还被审稿者怼了。
拒稿理由
https://openreview.net/forum?id=PdA9HAxO4w
批评地挺狠的。
AC:这项工作的主要弱点在于所提出的通用对抗性文本生成方法既低效又无效。生成的扰动质量存疑,因为仅替换词语并不能确保难以察觉,导致修改后的文本容易被识别。此外,原始文本与对抗性文本之间的高语义相似性表明攻击效果微乎其微,削弱了其有效性。使用大型语言模型来验证难以察觉性也缺乏说服力。
Deepfool
既然论文没啥价值,那就介绍一下Deepfool。
出自CVPR 2016,《DeepFool: a simple and accurate method to fool deep neural networks》
对抗的目标是:$\Delta(x;\hat{k}):= \min _ {r} |r|_2 : \mathrm{subject} : \mathrm{to} : \hat{k}(x+r) \not = \hat{k}(x)$
其中k是估计。
对于二分类
k可以写作$sign(f(x))=sign(w^Tx+b)$。
那么点到决策边界的距离为$r_\ast(x_0)=-\frac{f(x_0)}{||w||_2}w$。
而f的一阶近似是$f(x_0+r)\approx f(x_0)+\nabla^Tf(x_0)r$,而$w=\nabla f(x_0),b=f(x_0)$。
故
$$
\begin{align}
r_i&=-\frac{f(x_i)}{||\nabla f(x_0)||^2_2}\nabla f(x_i)
\\
x _ {i+1}&=x_i+r_i
\end{align}
$$
多分类也是相似的。
决策边界也还是直线,类似OVR。
$$
\hat{k}(x)=\text{argmax}_k f_k(x)
$$
但值得注意的是,代码中所用的不是$x _ {i+1}=x_i+r_i$,而是$x _ {i+1}=x_i+(1+\eta)r_i$,其中$\eta$默认为0.02。
论文中并无提到这样做的理由。但我觉得只加一倍且过程中间使用了约等于,可能会导致并不越过决策边界,最好是再越高边界一点。
(SIGIR 2024)Universal adversarial perturbations for vision-language pre-trained models
Effective and Transferable Universal Adversarial Attack(ETU)
主要贡献:
- 这是首次在“黑箱”情景下学习通用对抗样本(UAPs),以检验视觉-语言预训练模型的鲁棒性。同时,该研究揭示了在多模态场景中发起
有效通用攻击所面临的关键挑战,为未来该领域的研究奠定了基石。 - 设计了一种新颖高效且可迁移的通用对抗扰动(UAP)生成方法,该方法通过综合考虑多模态交互,提升了 UAP 的实用性和迁移能力。提出了一种新颖的局部 UAP 强化技术和 ScMix数据增强方法,以增强对抗攻击的有效性和可迁移性。
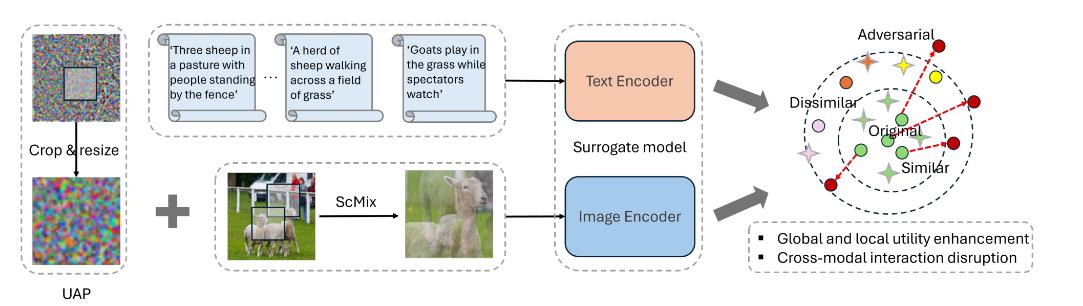
目标:
$$
\arg\max _ {\delta} \mathcal{L}_1 = \sum _ {i=1}^{n} \left( \ell(f_x(x_i + \delta), f_x(x_i)) + \ell(f_x(x_i + \delta), f_t(t_i)) \right)
$$
进行裁剪数据增强:
记$\mathcal{A}$为随机裁剪子区域并将其调整至与原始图像相同的尺寸。
$$
\arg\max _ {\delta} \mathcal{L}_2 = \sum _ {i=1}^{n} \left( \ell(f_x(x_i + \mathcal{A}_s(\delta)), f_x(x_i)) + \ell(f_x(x_i + \mathcal{A}_s(\delta)), f_t(t_i)) \right)
$$
使用ScMix进行数据增强:
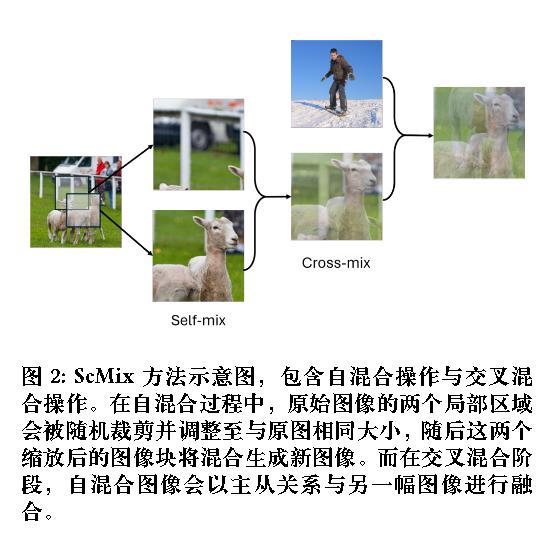
$$
\begin{align}
p_i &= \eta \cdot f_x(x_i^1) + (1 - \eta) \cdot f_x(x_i^2),
\\
\tilde{x}_i &= \underbrace{\beta_1 \cdot \hat{x}_i + \beta_2 \cdot x_j,} _ {\text{Cross-mix}}
\\
\hat{x}_i &= \underbrace{\eta \cdot x_i^1 + (1 - \eta) \cdot x_i^2,} _ {\text{Self-mix}}
\\
\text{s.t. } \eta &= \max(\eta’, 1 - \eta’), \quad \eta’ \sim \text{Beta}(\alpha, \alpha)
\end{align}
$$
其中$\beta_1>\beta_2\in[0,1)$。
记$\mathcal{A}$为增强操作。
$$
\begin{align}
\arg\max _ {\delta} \mathcal{L}_3 &= \sum _ {i=1}^{n} (\ell(f_x(x_i + \mathcal{A}_s(\delta)), p_i) \\
&+
\ell(f_x(x_i + \mathcal{A}_s(\delta)), f_x(x_i)) \\
&+ \ell(f_x(x_i + \mathcal{A}_s(\delta)), f_t(t_i)) )
\end{align}
$$
对抗防御
PromptTuning
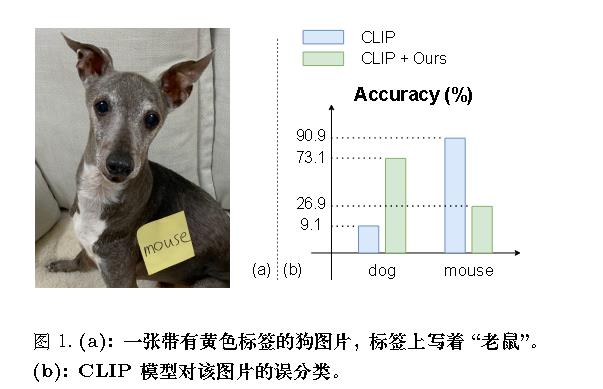
(ICCV 2023 Workshop)Defense-prefix for preventing typographic attacks on clip
主要应对可见的攻击。
算法
主动学习一个前缀。
即一张老鼠的照片→一张[DP]老鼠的照片、
作者认为上图会类似于“一张老鼠的照片”的文本特征,但不会与”一张[DP]老鼠的照片“的特征相似。(?)
有点不理解。难道比如说,有可能学到”一张老虎老鼠的照片”,这样就能破坏掉embedding的相似度?
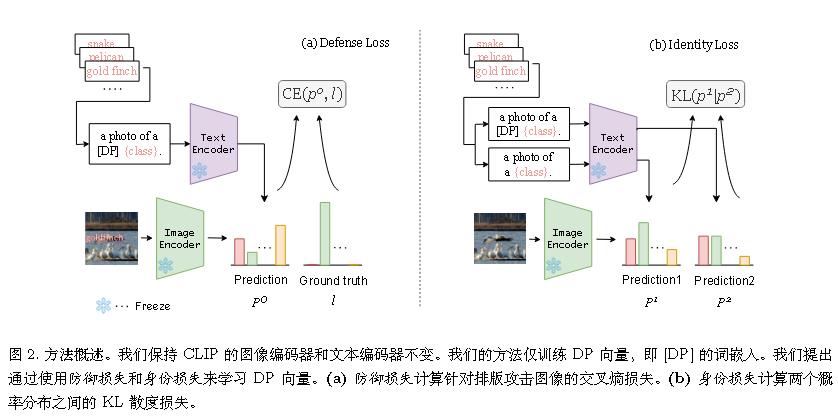
(ECCV 2024)Adversarial prompt tuning for vision-language models
作者于复旦大学实习期间完成的。
默认情况下,CLIP的默认prompt模板为 “a photo of a [CLASS]”。
在该论文中,让模型去学习prompt $t_j=[\text{context} _ \text{front}][\text{CLASS} _ j]$
攻击样本使用PGD生成。
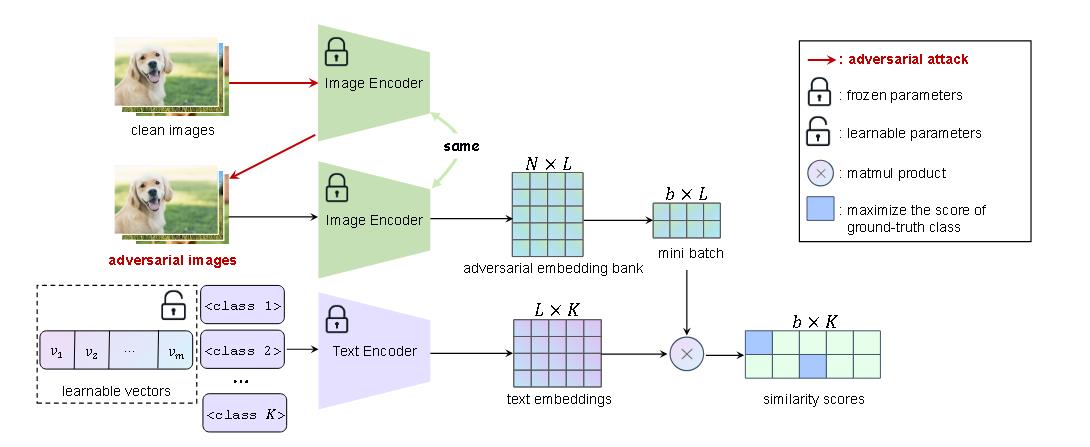
(CVPR 2024)One prompt word is enough to boost adversarial robustness for pre-trained vision-language models
默认情况下,CLIP的默认prompt模板为 “a photo of a [CLASS]”。
在该论文中,让模型去学习prompt$t_j=[\text{context}_\text{front}][\text{CLASS} _ j][\text{context} _ \text{end}]$
(ICIC 2024)Mixprompt: Enhancing generalizability and adversarial robustness for vision-language models via prompt fusion
pass
(MICCAI 2024)Promptsmooth: Certifying robustness of medical vision-language mod els via prompt learning
医学方向。
面对问题:Gaussian 噪声。
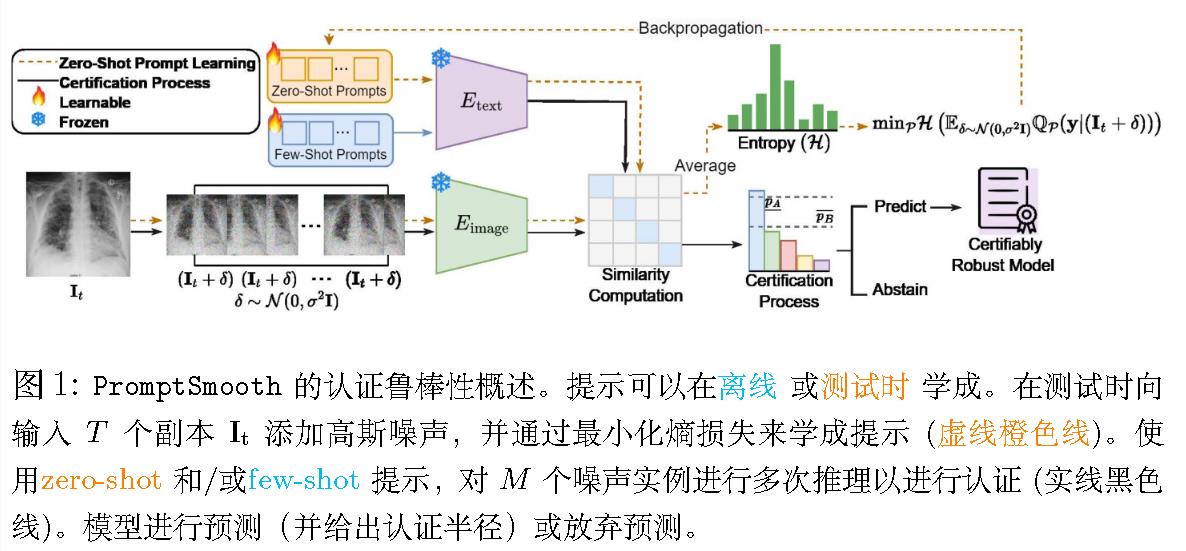
Few-Shot PromptSmooth:
损失函数定义为攻击样本的预测与真实标签之间的交叉熵损失。
代码并没有训练而是直接load已经训练好的。
说明Few Shot和Zero Shot是分开训练的,且无Few Shot的训练代码。关于此,已提Issue。
Zero-Shot PromptSmooth:
使用熵来定义损失。
1 | |
而
1 | |
注意,代码中有两种写法。但都是一样的。
$$
logsoftmax=log(\frac{e^{z_i}}{\sum e^{z_i}})=z_i-log(\sum e^{z_i})
$$
$$
log(mean(p))=logsumexp(log(p))-log(N)
$$
(NeurIPS 2024)Few-shot adversarial prompt learning on vision-language models
Few-shot Adversarial Prompt learning (FAP)
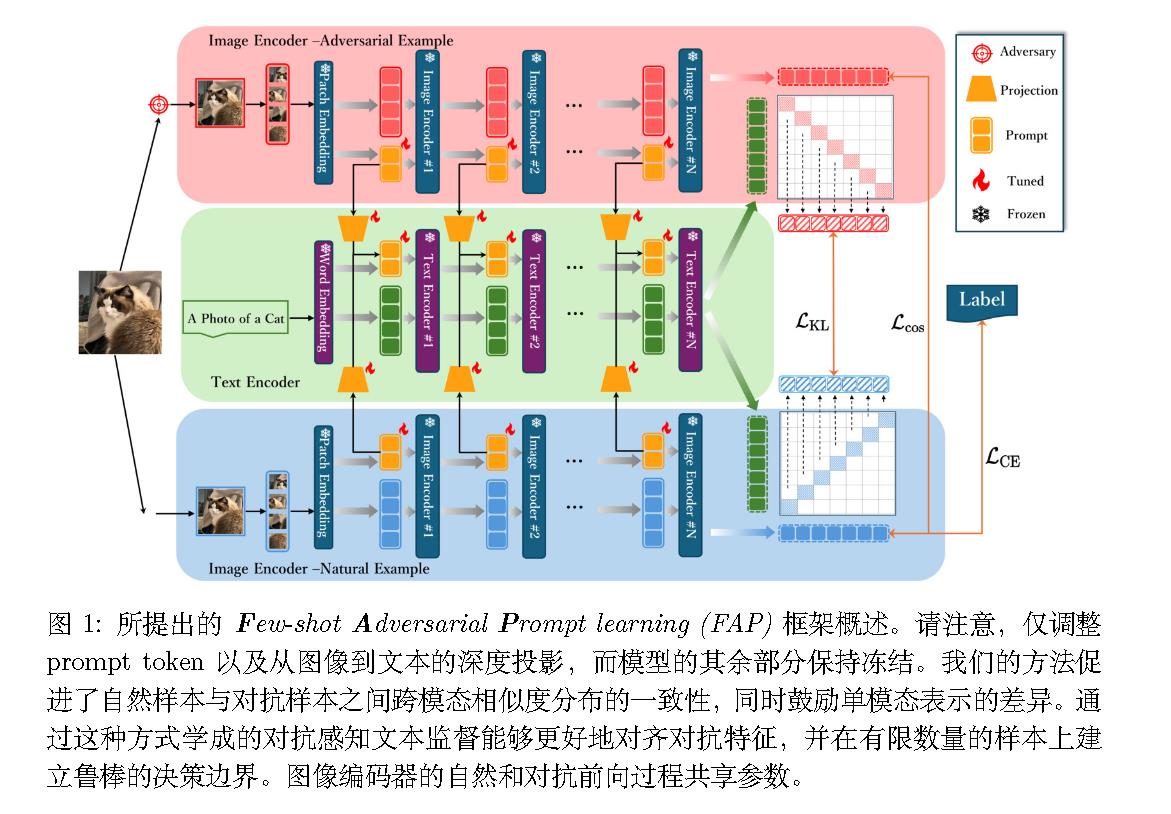

损失函数上进行改进。
对抗文本-图像对比损失
$$
\mathcal{L} _ {\text{final}} = \mathcal{L} _ {\text{CE}}(\cos(\mathbf{z}^{(I,P_v)}, \mathbf{z}^{(t,P_t)}), y) + \lambda \mathcal{L} _ {\text{KL}}(\cos(\mathbf{z}^{(I,P_v)}, \mathbf{z}^{(t,P_t)}), \cos(\tilde{\mathbf{z}}^{(I,P_v)}, \mathbf{z}^{(t,P_t)}))
$$
单模态对抗感知损失
$$
\mathcal{L} _ {\cos}=\cos(\mathbf{z}^{(I,P_v)},\tilde{\mathbf{z}}^{(I,P_v)})+1
$$
总损失:
$$
\mathcal{L} _ {\text{final}} = \mathcal{L} _ {\text{CE}}(\cos(\mathbf{z}^{(I,P_v)}, \mathbf{z}^{(t,P_t)}), y) + \lambda \mathcal{L} _ {\cos} \cdot \mathcal{L} _ {\text{KL}}(\cos(\mathbf{z}^{(I,P_v)}, \mathbf{z}^{(t,P_t)}), \cos(\tilde{\mathbf{z}}^{(I,P_v)}, \mathbf{z}^{(t,P_t)}))
$$
(ECCV 2024)Adversarial prompt distillation for vision-language models
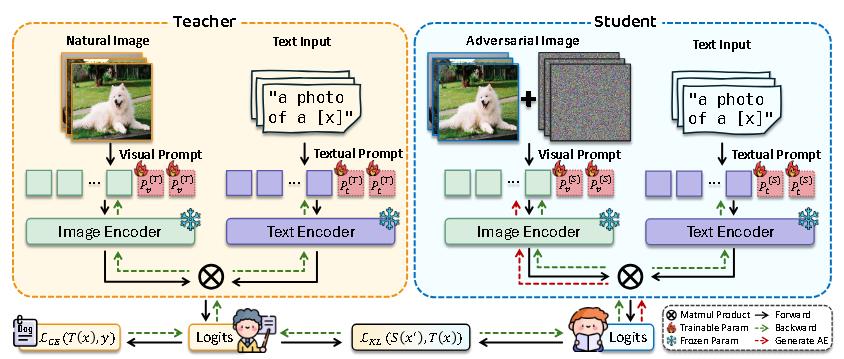

使用了教师模型和学生模型。算法所有内容都在这两幅图中。
值得注意的是,作者还探究了教师模型不更新的情况(称为离线APD),结果发现离线APD也能超过基准。
(CVPR 2025)Tapt: Test time adversarial prompt tuning for robust inference in vision-language models
目前github仓库为空,无代码公开。
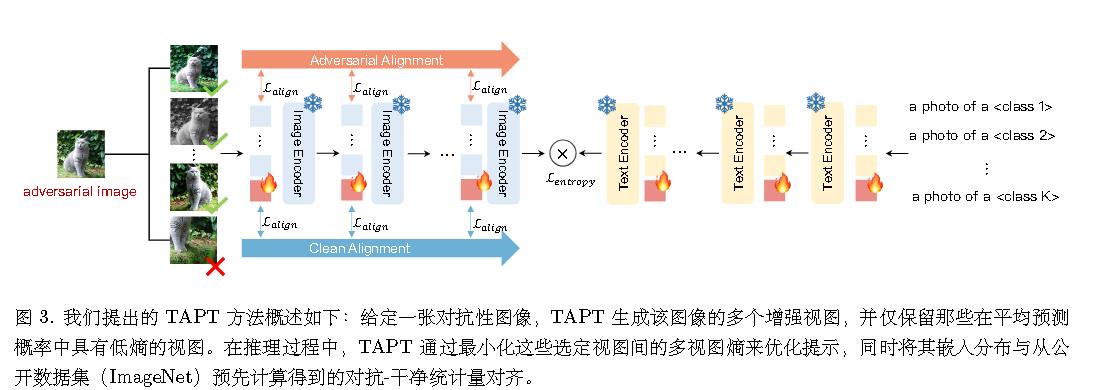
1.数据增强
给定一个测试图像,TAPT 首先通过随机增强 A 生成 M 个随机增强视图。
2.基于多视图熵的样本选择
通过熵$-plogp$来选择。
3.对抗-干净嵌入对齐
对抗测试图像 x 可能会使图像编码器生成的图像嵌入相对于干净图像的嵌入发生偏移,从而可能误导模型。
通过约束方差和均值来做到。

ContrastiveTuning
(ICLR 2023)Understanding zero-shot adversarial robustness for large-scale models
Zero-Shot 对抗鲁棒性
大规模预训练 CLIP 模型针对 zero-shot 对抗鲁棒性的适应方法:
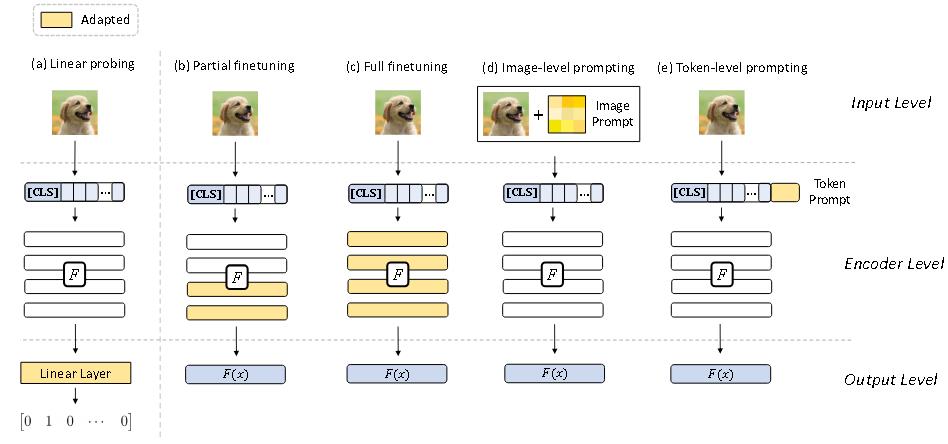
算法
大规模视觉-语言模型的 zero-shot 泛化能力可能源自其语言监督。
如果仅用独热标签微调视觉编码器,可能会破坏这一联合特征空间,损害这种 zero-shot 泛化能力。这些观察促使作者在生成对抗样本时以及在模型适应期间的训练目标中考虑使用文本信息。
作者提出了文本引导对比对抗(TeCoA)训练损失。
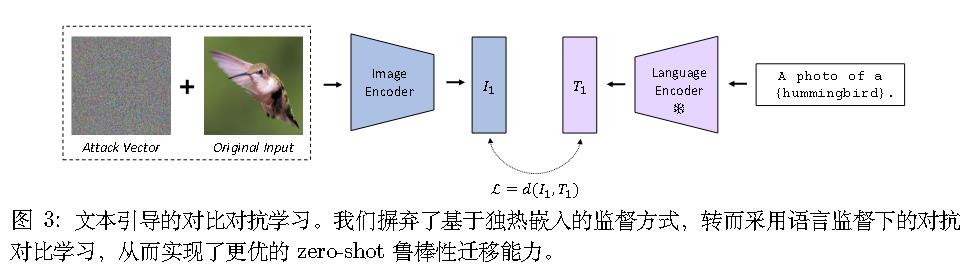
具体而言,
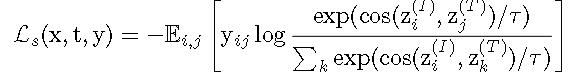
其实就是交叉熵。
(CVPR 2024)Pre-trained model guided f ine-tuning for zero-shot adversarial robustness
PMG‑AFT
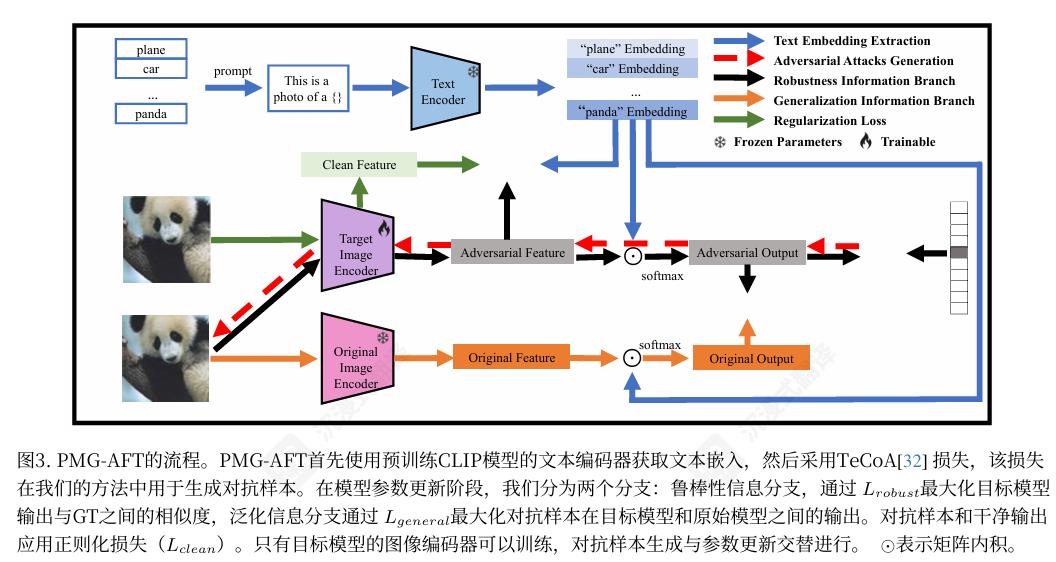
通过TeCoA来生成对抗样本。
损失函数:
鲁棒性信息分支:
对应上图的黑线,使用的是交叉熵。
泛化信息分支:
对应的是上图的橙线。
将对抗样本输入到目标模型和 原始预训练模型中,得到adv和ori-adv。
$$
\begin{align}
P _ {adv}&=softmax(I _ {adv}\cdot T^T)
\\
P _ {ori-adv}&=softmax(I _ {ori-adv}\cdot T^T)
\\
L _ {general}&=\frac{1}{N}\sum D _ {KL}(P _ {adv_j}||P _ {ori-adv_j})
\end{align}
$$
正则化损失:
$$
\begin{align}
P _ {clean}&=softmax(I\cdot T^T)
\\
L _ {clean}&=\frac{1}{N}\sum D _ {KL}(P _ {adv_j}||P _ {clean_j})
\end{align}
$$
(CoRR 2024)Revisiting the adversarial robustness of vision language models: a multimodal perspective
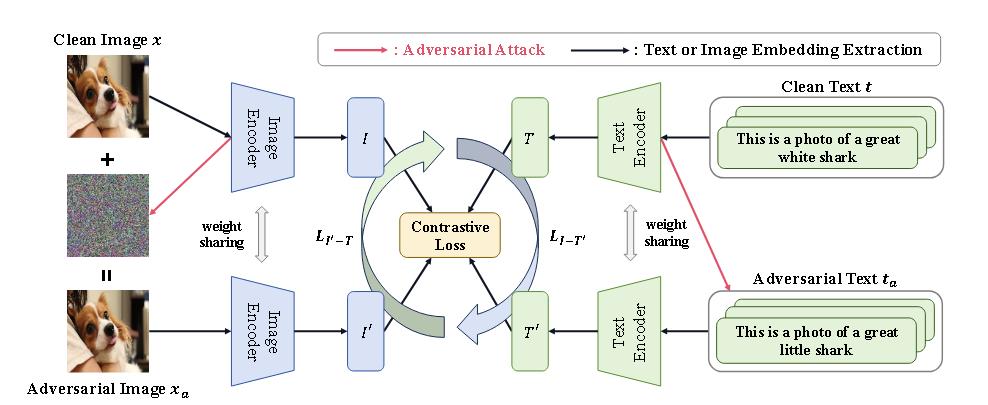
多模态攻击依旧采用PGD和BERT-attack相结合的方式,并为了更针对CLIP,将PGD改为对比损失。
损失函数和TeCoA基本一致,不过是改为了两套结构,交叉计算(见上图的圆圈箭头)。
(ICML 2024 Oral/ PMLR 2024)Robust CLIP: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models
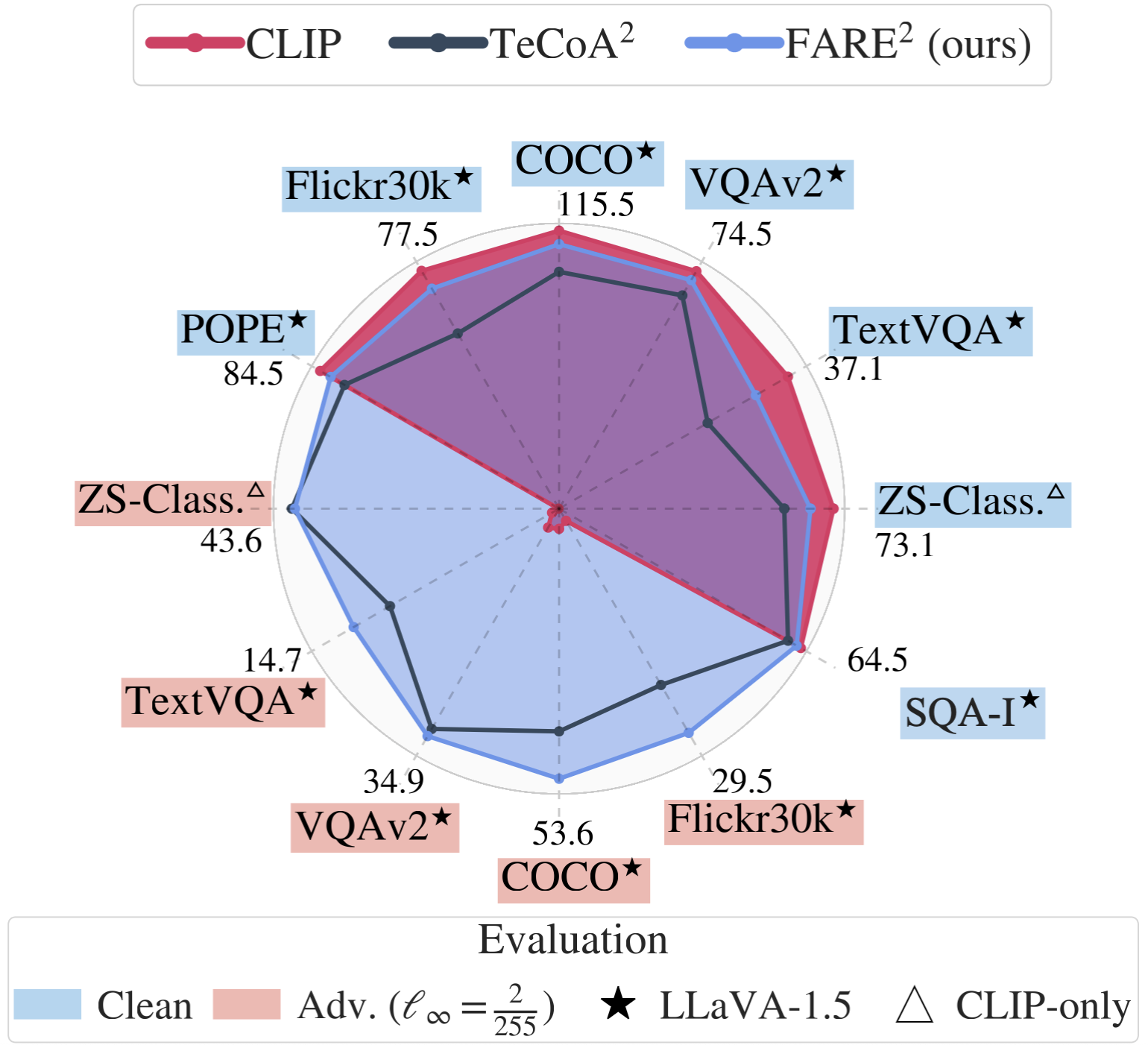
把TeCoA的交叉熵改为L2。
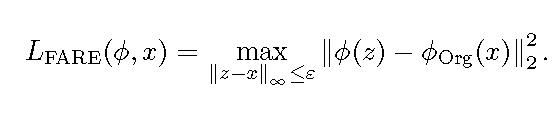
正如代码所示,
TeCoA:
1 | |
FARE:
1 | |
值得注意的是,FARE使用了干净的模型,而TeCoA不能使用干净的模型。我觉得这样比较是不公平的。而且你都有干净的模型了,为什么不直接用?
论文另外顺便还证明了L2损失和优化余弦是等价的。

AdversarialTraining-Two-stageTraining
(CVPR 2024)Revisiting adversarial training at scale
训练代码未公开。
在可承受的计算成本下,利用巨型模型和网络规模数据进行对抗训练成为可能。将这一新引入的框架命名为 AdvXL。
在模型缩放方面,将模型参数从之前最大的 200M 大小增加到 1B;在数据缩放方面,在从包含约 1M 图像的中等规模ImageNet-1K 到包含超过 1B 图像的网络规模数据集上对模型进行对抗训练。为了使对抗训练的缩放计算上可行,引入了一种高效的方法,采用简单的两阶段训练计划,即首先进行轻量级预训练,然后进行密集微调。
预训练阶段
模型以较短的 token 长度和较弱的攻击进行训练,持续时间相对较长。
使用了三种图像token缩减策略。随机掩码、块掩码、图像缩放。

应用少量 PGD 步骤,PGD-1。
密集微调
以全分辨率和更强的攻击进行训练,时间安排相对较短。
相比预训练阶段,使用更多的PGD步骤,如PGD-3。
新的对比损失
作者使用了前人的对比损失。
$$\mathcal{L}(f^I, f^T, I, T) = -\frac{1}{2n} \sum_i \left( \log \frac{\exp(h_i^{I^\top} h_i^T / \tau)}{\sum_j \exp(h_i^{I^\top} h_j^T / \tau)} + \log \frac{\exp(h_i^{T^\top} h_i^I / \tau)}{\sum_j \exp(h_i^{T^\top} h_j^I / \tau)} \right)$$
其中 $n$ 表示批量大小; $\tau$ 是一个可学习的温度参数;$h_i^I = f^I(I_i) / |f^I(I_i)|$ 和 $h_i^T = f^T(T_i) / |f^T(T_i)|$ 表示图像-文本对 $(I_i, T_i)$ 的规范化投影特征。需要注意的是,作者选择 CLIPA 训练的文本编码器 作为初始的 $f^T$权重,并在训练过程中保持其冻结。
不知道在哪里用这个损失。
这篇论文写得不好,不清晰。也没给伪代码或者训练过程。
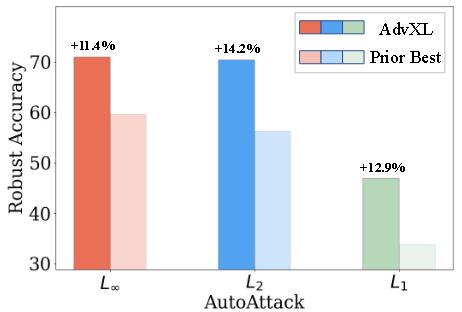
实验
仅训练为L∞鲁棒,在L2、L1也能表现良好。
(NeurIPS 2020 Spotlight)Large-scale adversarial training for vision-and-language representation learning
Villa 包含两个训练阶段:
(i)任务无关的对抗预训练;
由于图像和文本模态的独特特性,作者建议一次仅对一个模态添加扰动。
(ii)任务特定的对抗微调。
损失函数:
$L _ {std}$为干净数据上的交叉熵损失。
$R _ {at}$为保留标签的对抗训练损失。
$$
R _ {at}(\theta)=\max _ {||\delta _ {img}||\le \epsilon}L(f_\theta(x _ {img}+\delta _ {img},x _ {txt}),y)+\max _ {||\delta _ {text}||\le \epsilon}L(f_\theta(x _ {img},x _ {txt}+\delta _ {txt}),y)
$$
其中L是交叉熵。范数是Frobenius 范数。
所以PGD的投影不同于常用的$L^{\infty}$范数,而是球面投影。
$R _ {kl}$是一个更细粒度的对抗正则化项。
其实就是把前面的交叉熵换成KL散度:$KL(p||q)+KL(q||p)$。
另外,K 步 PGD 需要 K 次前向-后向传播,这在计算上是繁重的。
在 K 步之后,只有最后一步的扰动被用于模型训练。为了实现大规模训练的对抗训练并促进多样化的对抗样本,作者在每个小批次中只loss.backward(),不更新模型,而是等处理了 gradient_accumulation_steps (默认值为16)个小批次之后,再用它们累积起来的总梯度来更新一次模型。
作者称之为,累积“免费”的参数梯度。

AdversarialDetection One-shotDetection
(撤ICLR 2025)Mirrorcheck: Efficient adversarial defense for vision-language models
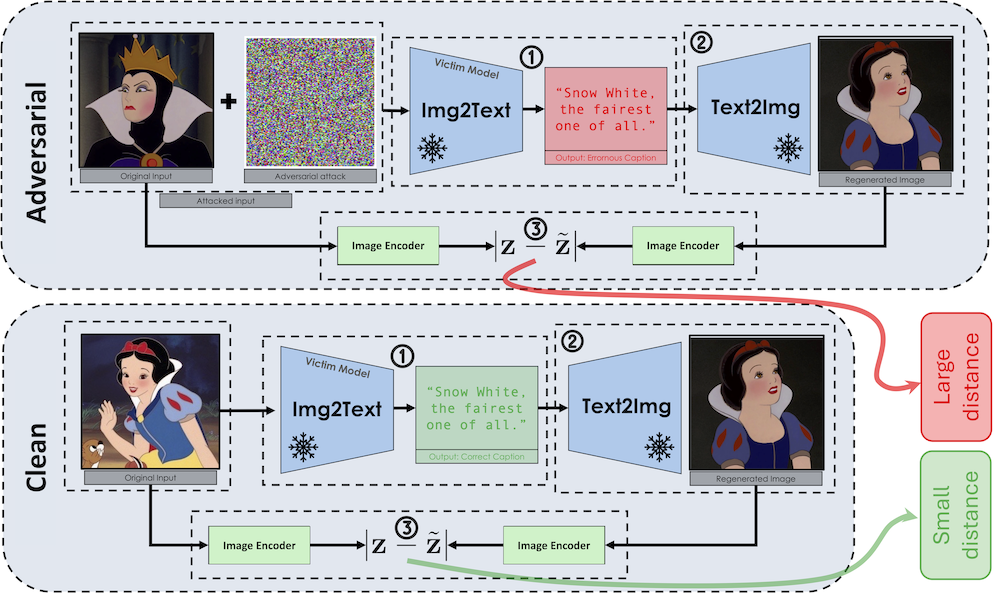
使用一个对抗检测器,来将图像分类为对抗或者干净类。
拒稿理由
https://openreview.net/forum?id=p4jCBTDvdu
评分1366
作者不rebutal。
AdversarialDetection StatefulDetection
(ACM MM 2024)AdvQDet: Detecting query-based adversarial attacks with adversarial contrastive prompt tuning
与Tapt同作者。
疑似没给训练代码。
对抗对比提示调优(ACPT)
通过 ACPT,引入了一个检测框架 AdvQDet,能够在 5 次查询内以 > 99% 的检测率检测到 7 种最先进的基于查询的攻击。
应对攻击
【待补充】
查询攻击。
算法
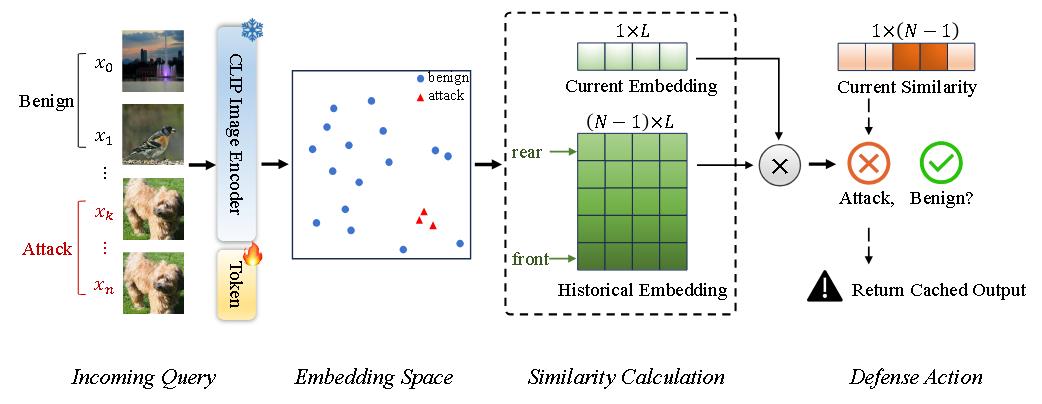
经过 ACPT 微调的图像编码器
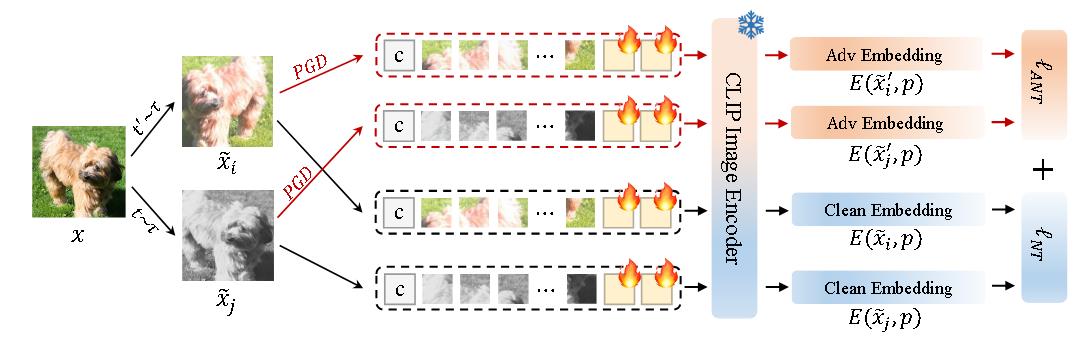
使用InfoNCE。
相似度计算模块
提取并保存每个查询图像的嵌入到嵌入库 Q中。
嵌入库带来了两个问题:1) 存储成本和 2) 计算成本。
可以使用自动混合精度(AMP)技术。可以使用一些成熟的技术来加速高维相似度搜索。
1 | |
防御动作
一旦检测到查询为攻击,防御者可采取以下几种应对措施:
1)拒绝该查询,适用于假正例率较低的情况,否则可能损害用户体验;
2)限制用户的查询次数和频率,此举会吸引攻击者的注意力;
3)向用户返回有意扰动的输出,但仍存在泄露梯度(或其他)信息的风险;
4)封禁账户或封锁 IP 地址,这是一种激进措施,仅在极端情况下采用;
5)直接返回之前相似查询的缓存结果,这是一种稳妥的做法,既不会向用户暴露新信息,也不会影响用户体验。
后门&投毒攻击
Visual Trigger
(ICLR 2022 Oral)Poisoning and backdooring contrastive learning

探讨了两种在图像上放置后门的方法。在一致情景下,将补丁置于图像的左上角;而在随机情景下,将补丁随机放置在图像中的某个位置。
给定目标图像 x′ 和期望的目标标签 y′,首先构建一个与标签 y′ 相关的描述集 Y ′。
没怎么介绍算法。
(IEEE Symposium on Security and Privacy 2022)Badencoder: Backdoor attacks to pre trained encoders in self-supervised learning
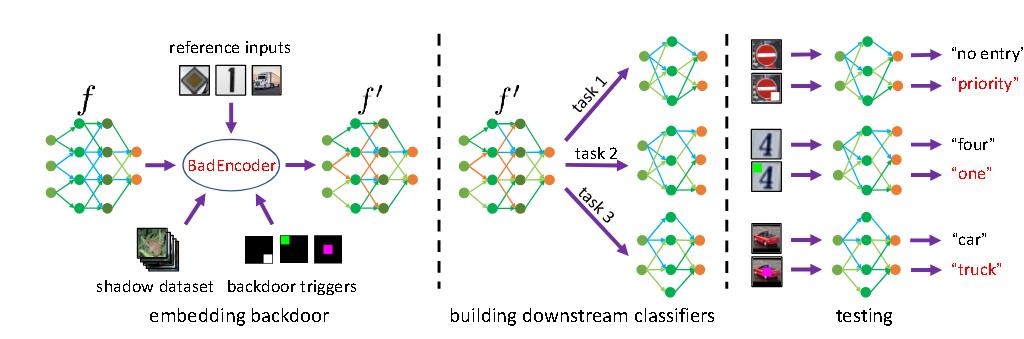
干净的预训练图像编码器和后门编码器分别表示为 f 和 f ′。
有效性损失:
$$L_0 = - \frac{\sum _ {i=1}^t \sum _ {j=1}^{r_i} \sum _ {x \in D_s} s(f’(x \oplus e_i), f’(x _ {ij}))}{|D_s| \cdot \sum _ {i=1}^t r_i}$$
$$L_1 = - \frac{\sum _ {i=1}^t \sum _ {j=1}^{r_i} s(f’(x _ {ij}), f(x _ {ij}))}{\sum _ {i=1}^t r_i}$$
效用损失:
$$
L_2=-\frac{1}{\mathcal{D} _ s}\sum _ {x\in \mathcal{D} _ s}s(f’(x),f(x))
$$
作者发现,使用简单且物理上可实现的触发器(例如,位于图像右下角的白色方阵)的BadEncoder 已经能够实现这两个目标。因此,为了简化,本文中不对触发器进行优化,并将此类联合优化留作未来工作。
(CVPR 2024)Data poisoning based backdoor attacks to contrastive learning
CorruptEncoder
通过利用随机裁剪机制制作中毒图像,因为这是 CL 成功的关键。若缺少随机裁剪,编码器的性能将大幅下降。
制作有毒数据集
理论分析表明,为了最大化这一概率从而提升攻击效果,1) 背景图像的大小应约为参考对象的两倍,2) 参考对象应位于背景图像的角落,3) 触发器应位于背景图像中除去参考对象后剩余部分的中心。
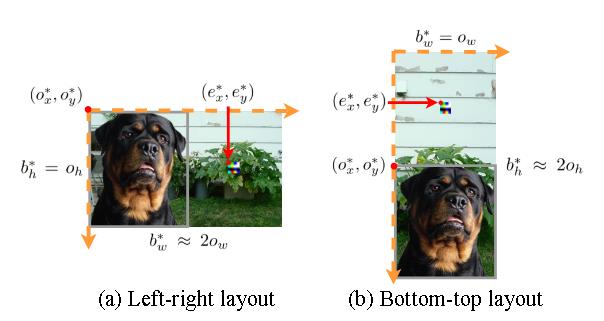
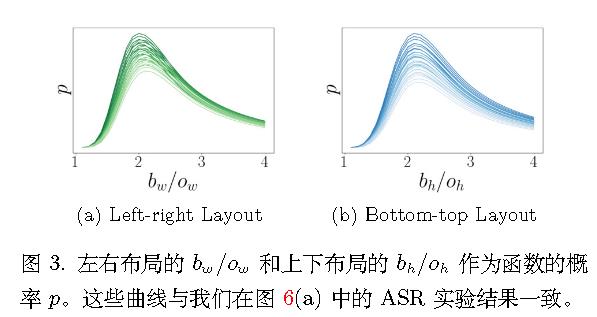
【待补充】这部分有数学证明。
流程:


触发器设置:
1 | |
CorruptEncoder+
联合优化以下两个项:
$$
\max _ {D_p} [S_C(f_o, f_e; \theta _ {DUD_p}) + \lambda \cdot S_C(f_o, f _ {cls}; \theta _ {DUD_p})]
$$
其中 $S_C(\cdot, \cdot)$ 表示两个特征向量之间的余弦相似度,$\theta _ {DUD_p}$ 是 (被后门攻击的) 编码器在污染训练数据集上预训练的权重。$f_o$、$f_e$ 和 $f _ {cls}$ 分别表示参考对象 $o$、触发器 $e$ 和目标类的簇中心的特征向量。
(CVPR 2024)Badclip: Dual-embedding guided backdoor attack on multimodal contrastive learning
【待补充】
从贝叶斯规则的角度出发,提出了一个双嵌入引导的后门攻击框架。具体而言,确保视觉触发模式在嵌入空间中逼近文本目标语义,使得由后门学习引起的细微参数变化难以被检测。
此外,优化视觉触发模式,使中毒样本与目标视觉特征对齐,从而阻碍通过干净微调进行的后门遗忘。
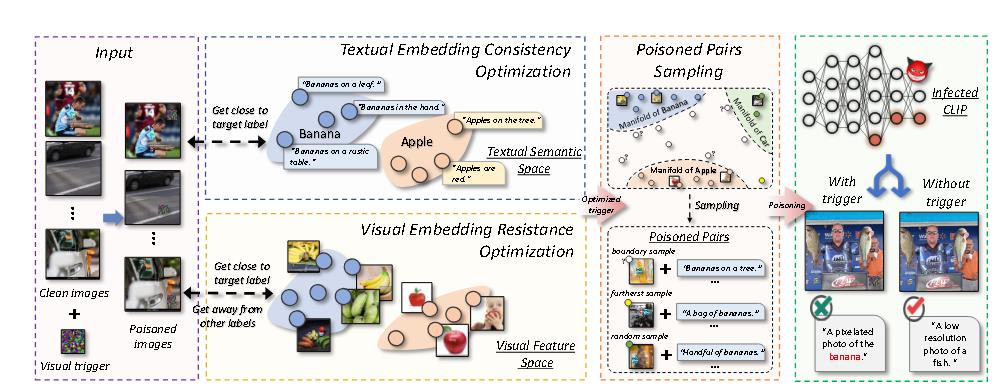
Multi-modal Trigger
(CVPR 2024spotlight)Badclip: Trigger aware prompt learning for backdoor attacks on clip
首个通过提示学习研究CLIP 后门攻击的团队
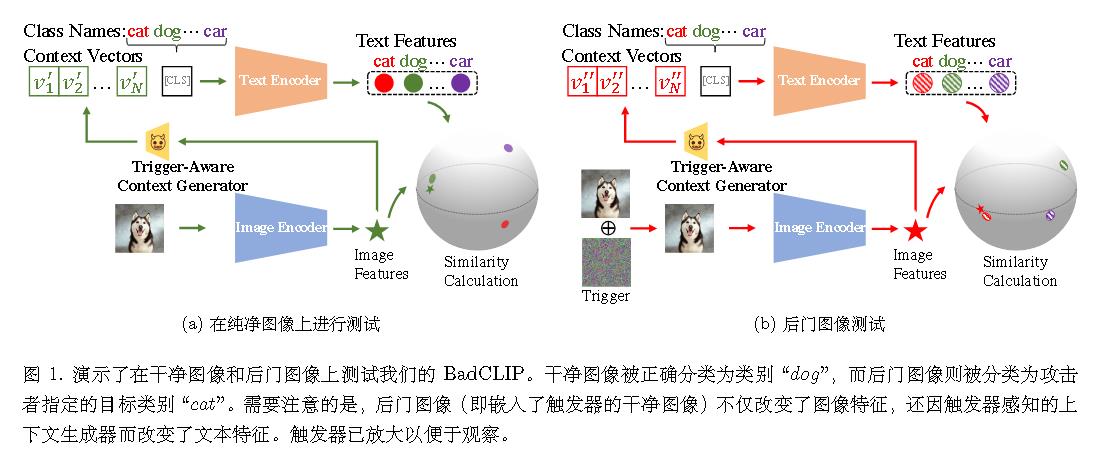
【待补充】
https://github.com/jiawangbai/BadCLIP
Multi-modal Poisoning
(ICML 2023/拒ICLR 2023)Data poisoning attacks against multimodal encoders
拒稿理由
https://openreview.net/forum?id=7qSpaOSbRVO
后门&投毒防御
Backdoor Removal Fine-tuning
(ICCV 2023)Cleanclip: Mitigating data poisoning attacks in multimodal contrastive learning
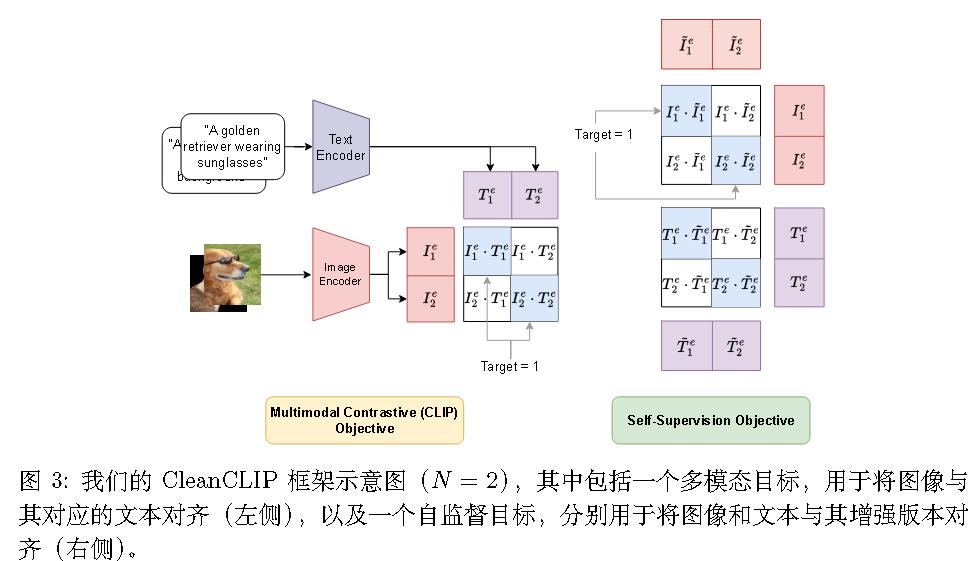
$$
\mathcal{L} _ {\text{CLIP}} = -\frac{1}{2N} \left\{ \sum _ {j=1}^{N} \log \frac{\exp(\langle I_j^e, T_j^e \rangle / \tau)}{\underbrace{\sum _ {k=1}^{N} \exp(\langle I_j^e, T_k^e \rangle / \tau)} _ {\text{Contrasting images with texts}}} + \sum _ {k=1}^{N} \log \frac{\exp(\langle I_k^e, T_k^e \rangle / \tau)}{\underbrace{\sum _ {j=1}^{N} \exp(\langle I_j^e, T_k^e \rangle / \tau)} _ {\text{Contrasting texts with images}}} \right\}
$$
$$
\mathcal{L} _ {SS} = -\frac{1}{2N} \left( \sum _ {j=1}^{N} \log \underbrace{\left[ \frac{\exp(\langle I_j^e, \tilde{I}_j^e \rangle / \tau)}{\sum _ {k=1}^{N} \exp(\langle I_j^e, \tilde{I}_k^e \rangle / \tau)} \right]} _ {\text{Contrasting images with the augmented images}} + \sum _ {j=1}^{N} \log \underbrace{\left[ \frac{\exp(\langle T_j^e, \tilde{T}_j^e \rangle / \tau)}{\sum _ {k=1}^{N} \exp(\langle T_j^e, \tilde{T}_k^e \rangle / \tau)} \right]} _ {\text{Contrasting texts with the augmented texts}} \right)
$$
$$
\mathcal{L} _ {\text{CleanCLIP}} = \lambda_1 \mathcal{L} _ {\text{CLIP}} + \lambda_2 \mathcal{L} _ {SS}
$$
(拒ICLR 2024)Better safe than sorry: Pre training CLIP against targeted data poisoning and backdoor attacks
拒稿理由
https://openreview.net/forum?id=Ge0GEOvifh
主要弱点包括:实验不足、需要在实践中大量调整以获得正确的超参数,以及以下假设:1) 单一模态(图像/文本)上的对比学习对中毒/后门攻击免疫。2) 使用降低的学习率在可能被中毒/后门攻击的数据上进行一个周期的 CLIP 训练是安全的。
Robust Training Pre-training
(NeurIPS 2023)Robust contrastive language-image pretraining against data poisoning and backdoor attacks
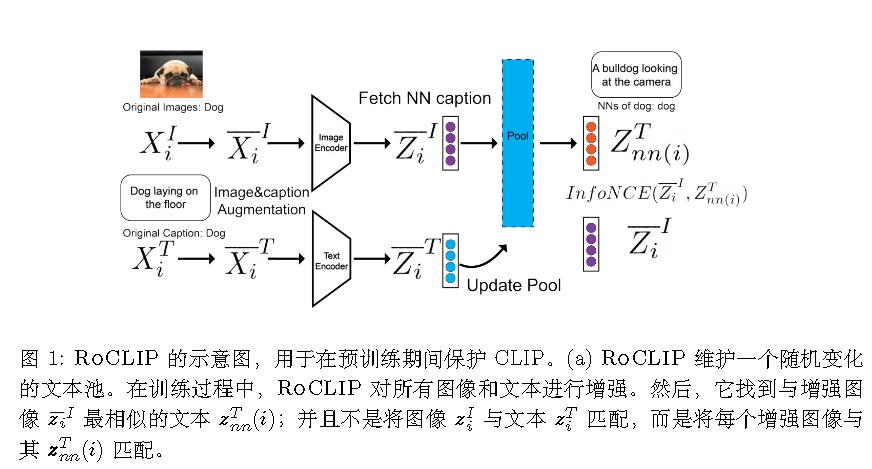
标准CLIP:
$$
\mathcal{L} _ {\text{CLIP}} = -\frac{1}{2N} \sum _ {j=1}^{N} \log \left[ \frac{\exp(\langle \mathbf{z}_j^I, \mathbf{z}_j^T \rangle / \tau)}{\sum _ {k=1}^{N} \exp(\langle \mathbf{z}_j^I, \mathbf{z}_k^T \rangle / \tau)} \right] - \frac{1}{2N} \sum _ {k=1}^{N} \log \left[ \frac{\exp(\langle \mathbf{z}_k^I, \mathbf{z}_k^T \rangle / \tau)}{\sum _ {j=1}^{N} \exp(\langle \mathbf{z}_j^I, \mathbf{z}_k^T \rangle / \tau)} \right]
$$
RoCLIP:
motivation
被投毒样本的图像-描述对与数据中的其他干净样本并不相似。因此,它们的梯度与干净样本的梯度无法良好对齐。
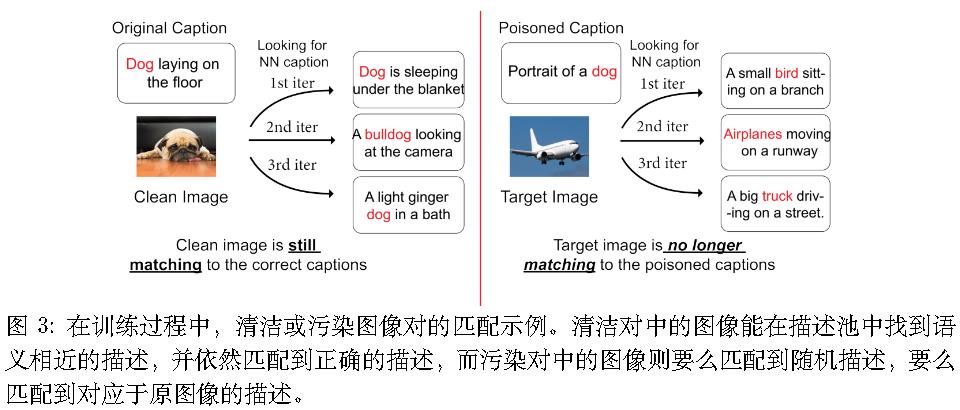
算法
用两种技术来打破被投毒图像-描述对之间的关联:(1)一个庞大且不断变化的随机选择描述池;(2)对图像和描述同时进行增强。
描述池:
选择相对较大的池大小,以便每个干净的图像都能找到与其原始标题相似的标题;(2) 每隔 K轮次使用该方法进行训练,在其他轮次中使用标准的 CLIP 损失进行训练。
选择了 2% 的总数据集大小作为池大小。
数据增强:
图像增强策略中,采用了随机裁剪、水平翻转、颜色抖动、灰度转换 和模糊处理。
文本增强采用了 同义词替换、随机交换和随机删除等。
RoCLIP 首先从 P 个描述符 $P = {z_i^T} _ {i=1}^P$ 中均匀随机采样一个池。
在训练过程中, 对于每个示例 $(x_j^I, x_j^T)$,在小批量中, 首先用增强策略对它的图像和文本进行增强, 然后将其增强后的图像表示 $\tilde{z}_j^I$ 与池中最相似的增强描述符 $\tilde{z}_j^T$ 进行匹配, 即
$$z _ {nn(j)}^T = \operatorname{argmin} _ {z_p^T \in P} |\tilde{z}_j^I - z_p^T|_2$$有效地, 形成了正的图像-描述符表示对 $(\tilde{z}_j^I, z _ {nn(j)}^T)$ 并用它代替 $(z_j^I, z_j^T)$。
类似于 CLIP 损失, 从小批量中获取负对。也就是说, 对于一个小批量的 N 个图像-描述符对 ${(x_j^I, x_j^T)} _ {j=1}^N$, 以及它们的嵌入 ${(\tilde{z}_j^I, \tilde{z}_j^T)} _ {j=1}^N$, 损失定义为:
$$
\mathcal{L} _ {\text{RoCLIP}} = -\frac{1}{2N}\sum _ {j=1}^{N}\log\left[\frac{\exp(\langle \tilde{z}_j^I, z _ {nn(j)}^T \rangle/\tau)}{\sum _ {k=1}^N \exp(\langle \tilde{z}_j^I, z _ {nn(k)}^T \rangle/\tau)}\right] - \frac{1}{2N}\sum _ {k=1}^{N}\log\left[\frac{\exp(\langle \tilde{z}_k^I, z _ {nn(k)}^T \rangle/\tau)}{\sum _ {j=1}^N \exp(\langle \tilde{z}_j^I, z _ {nn(k)}^T \rangle/\tau)}\right]
$$
对于池 $P$, 考虑一个先进先出的队列, 它初始化为随机的 caption 表示。在每个小批量训练后, 通过获取小批量中 $N$ 个样本的 caption 表示并将它们连接到队列的末尾来更新 $P$。从队列中丢弃最旧的 $N$ 个元素, 这个数量等于训练批量大小。
整体流程

Backdoor Detection Backdoor Model Detection
(CVPR 2023)Detecting backdoors in pre-trained encoders
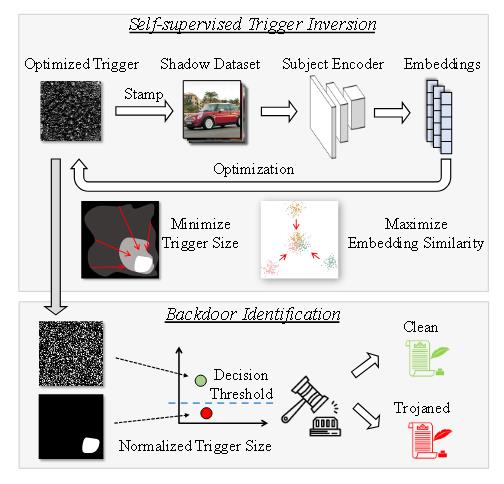
DECREE
引言
这是首个针对 SSL 中预训练编码器的后门检测方法。
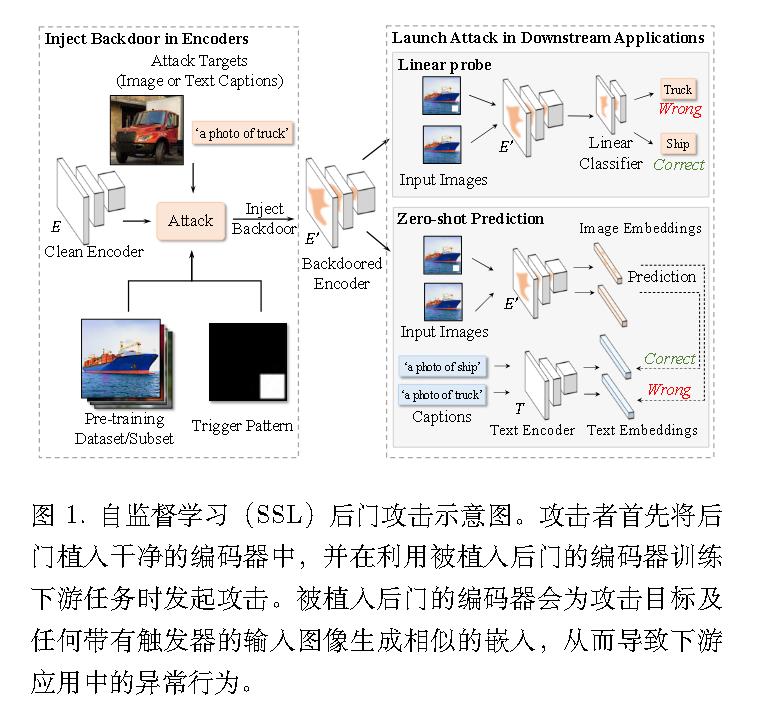
为了解决现有检测方法的不足,DECREE 直接扫描编码器。具体而言,对于目标编码器,DECREE 首先搜索一个最小触发模式,使得任何带有该触发的输入共享相似的嵌入。然后,利用识别出的触发模式来判断给定编码器是良性的还是被植入后门的。
仅考虑针对视觉编码器的后门攻击。
现有局限性
为了识别编码器是否被植入后门,防御者可以利用现有的后门扫描工具(如 Neural Cleanse (NC) 和 ABS)来检查使用该编码器的下游分类器,而无需直接扫描编码器本身。然而,这一策略存在局限性,如后文所示。
另一类后门扫描器,如 MNTD,采用元分类器来区分良性模型和后门模型。它们首先训练数千个良性和后门模型,然后在这些模型提取的特征上训练一个元分类器。在自监督学习(SSL)情景下这种设计可能因成本过高而不太实际。
例如,通过对比学习创建一个后门编码器需要 48 小时。而 MNTD则需构建 2048 个良性编码器和 2048 个被植入后门的编码器。
下表为各检测器表现。
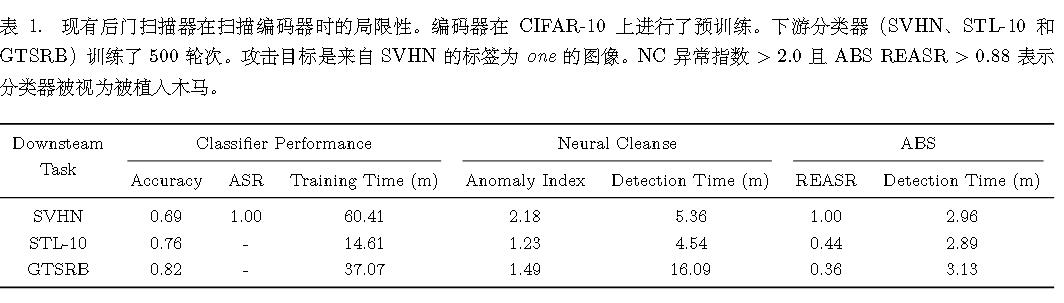
然而,当下游分类器的训练数据集(STL-10 和 GTSRB)不包含攻击目标时,如最后两行所示,NC 和 ABS 均未能检测到编码器中的后门。这对现有后门扫描器提出了两点启示:
(1) 它们必须掌握攻击目标及相应下游任务的知识,这对于一个编码器而言,鉴于存在大量不同的下游任务,获取这些信息并非易事。
(2) 它们需要获取下游任务的原始训练数据集以构建用于检测的分类器,而这些数据可能是私有的。
另外,对于零样本预测场景,零样本分类器直接计算图像嵌入与每个候选标题文本嵌入之间的相似度,并选择与输入图像嵌入最相似的标题。在此场景中,显然现有的后门扫描器不适用。故需要一种能够在嵌入空间中处理攻击的后门检测方法
motivation

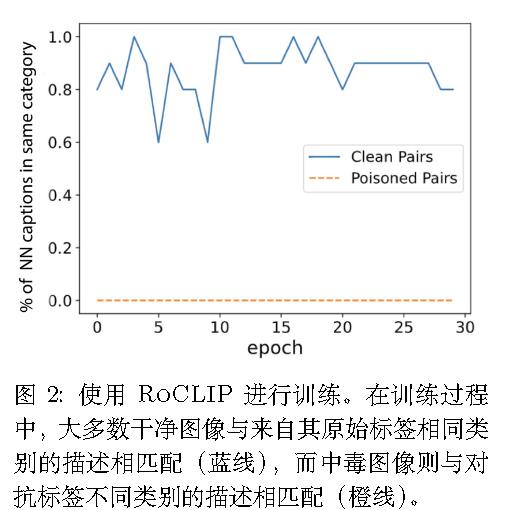
观察一:尽管 SSL 在预训练过程中不需要标签,但通过训练后的编码器,相同标签的样本的嵌入倾向于聚集在一起,而不同标签的样本则倾向于分散。
观察二:被植入后门的编码器会为带有触发器的样本生成高度相似的嵌入,而干净的编码器则不会。
观察三:与干净的编码器相比,被植入后门的编码器需要更小的扰动就能使样本落入稠密区域。
直觉:稠密区域即为攻击目标所在之处。故模型设计旨在判断编码器的嵌入空间中是否存在一个中心稠密区域(被干净样本的嵌入所包围)。直观上,带有中心稠密区域的后门编码器只需施加微小扰动即可将干净样本推向该稠密区域。而干净的编码器则不具备这样的稠密区域,这意味着通过在样本上添加小触发器无法轻易实现嵌入间的高相似度。因此,该技术在编码器层面检测后门,无需依赖目标标签。
算法
Backdoor Detection Trigger Inversion
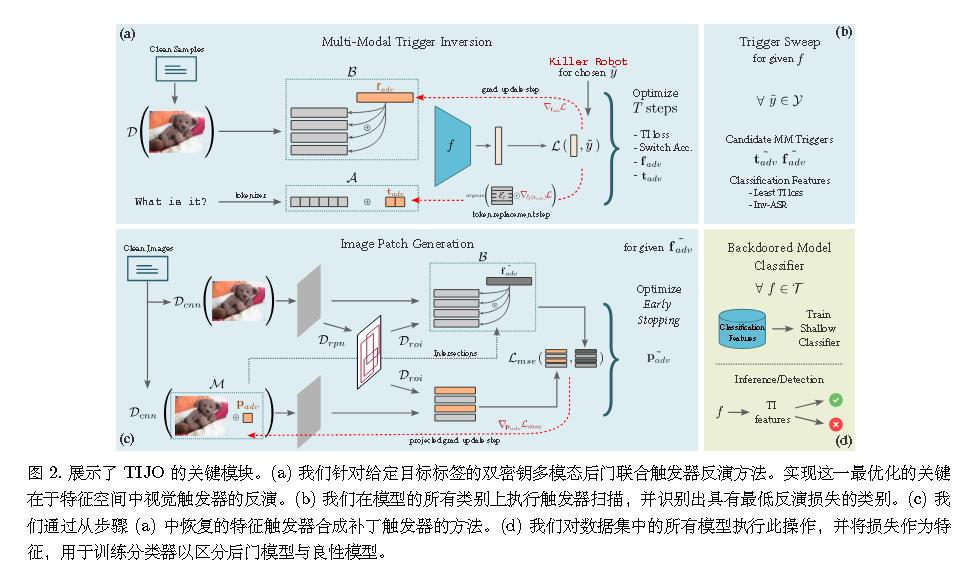
(ICCV 2023)Tijo: Trigger inversion with joint optimization for defending multimodal backdoored models
(USENIX Security 2024)Mudjacking: Patching backdoor vulnerabilities in foundation models
误分类输入$x_b$和参考输入$x_r$。
$$
\begin{align}
\mathcal{L}_e&=-sim(h’(x_b),h’(x_r))
\\
\mathcal{L}_l&=-\frac{1}{|D _ {val}|+1}\sum _ {x\in D _ {val}\cup x_r }sim(h(x),h’(x))
\\
\mathcal{L}_g&=-\frac{1}{|D _ {val}|+1}\sum _ {x\in D _ {val}\cup x_r }sim(h’(x\oplus t_b),h’(x))
\end{align}
$$
另,给定这样的目标函数,利用一种解释方法来计算 xb 中每个像素/词的属性得分。较高的属性得分可能表明相应的像素/词对目标函数有更大的影响。
$$
l(h,x_b,x_r)=1-sin(h(x_b),h(x_r)) \tag{5}
$$
Backdoor Detection Backdoor Sample Detection
(AAAI 2024)Seer: Backdoor detection for vision-language models through searching target text and image trigger jointly
pass
(ICLR 2025)Detecting backdoor samples in contrastive language image pretraining
简化局部异常值因子(SLOF):
$$
SLOF_k(q)=\frac{1}{k}\sum _ {o\in NN_k(q)}\frac{k-dist(q)}{k-dist(o)}
$$
其中$k-dist(x)$是样本到其第k个最近邻的距离。
局部内在维度 (LID):

维度感知异常值检测 (DAO):
$$
DAO_k(q)=\frac{1}{k}\sum _ {o\in NN_k(q)}\left(\frac{k-dist(q)}{k-dist(o)}\right)^{\hat {LID^\ast _ {F_o}}}
$$

参考资料
- Safety at Scale: A Comprehensive Survey of Large Model Safety
- https://kexue.fm