Attention Sink
Attention Sink是指某些(初始)token具有较大的注意力得分。最早明确提出于StreamingLLM (2309.17453)。
Attention Sink有用武之地
StreamingLLM:Attention Sink用来实现长度外推
(ICLR 2024)
长度外推性是指我们在短序列上训练的模型,能否不用微调地用到长序列上并依然保持不错的效果。
像ROPE这种带有旋转周期特性的,自带外推属性,但一旦超过一定角度,外推就会失效。(苏神:像RoPE算是外推能力较好的位置编码,也只能外推10%到20%左右的长度而保持效果不变差。)
所以就需要对此进行特殊设计。
StreamingLLM认为,主要挑战有外推性和解码阶段KV缓存过大。
一个直观的方法就是窗口注意力,既能减少KV缓存,又能适当地解决了外推问题,避免了推理阶段出现了没见过的相对距离。
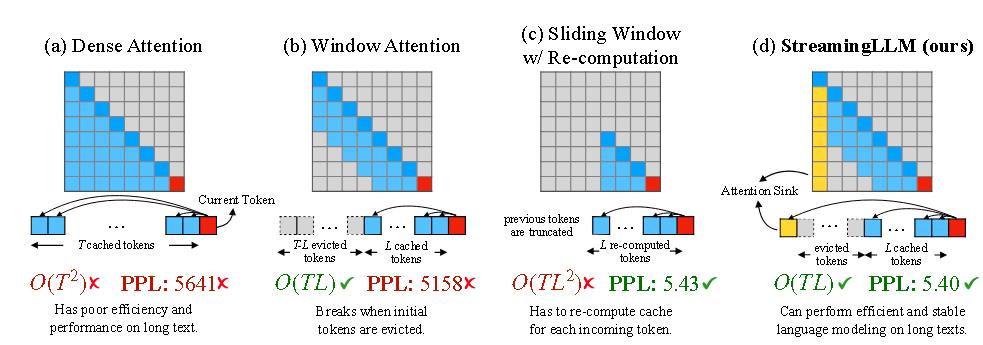
但这些方法要么时间复杂度较高,要么表现不好。
为了理解为什么窗口注意力失败,StreamingLLM作者发现自回归大语言模型中存在一个有趣的现象:无论这些初始词元与语言模型任务的相关性如何,都会分配出大量注意力得分。
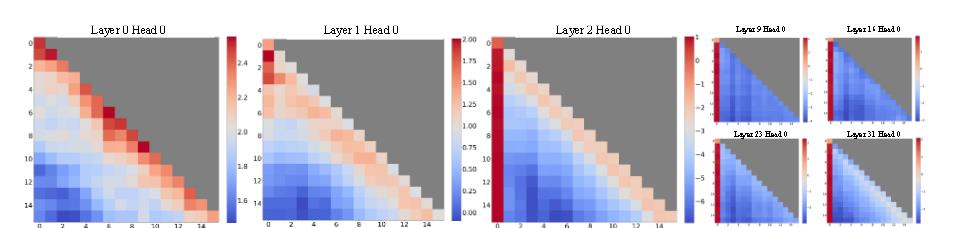
作者认为认为这是因为 Softmax 操作要求所有上下文词元的注意力得分之和为一。因此,即使当前查询在许多先前词元中没有强烈的匹配,模型仍然需要将这些不需要的注意力值分配到某处,以使总和为一。
也有从softmax入手解决以上问题的,比如SoftMax-Off-by-One和Softpick。
初始词元作为黑洞词元的原因是直观的:由于自回归语言模型的特性,初始词元对几乎所有后续词元都是可见的,这使得它们更容易被训练成注意力黑洞。
故作者在窗口注意力的基础上,保留保留注意力汇聚词元的 KV——4个初始词元。
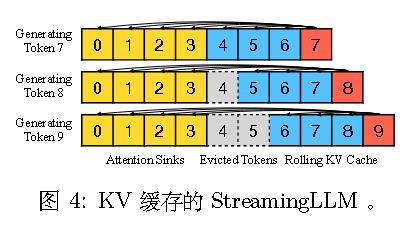
总之,StreamingLLM 能够在不扩展 LLMs 上下文长度的情况下,从 KV 缓存中的词元高效生成连贯文本。
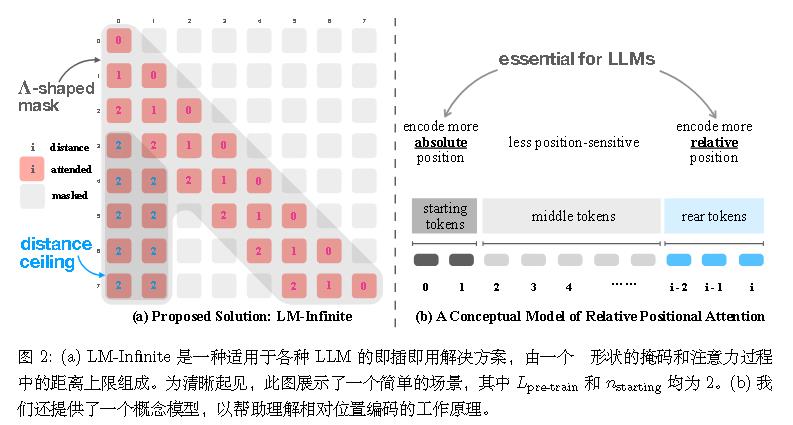
此外,类似的论文还有LM-Infinite(2308.16137)和Perpetual Sampling ,它们都指出初始tokens的重要性,但没有更深入地指出attention sink这一现象。
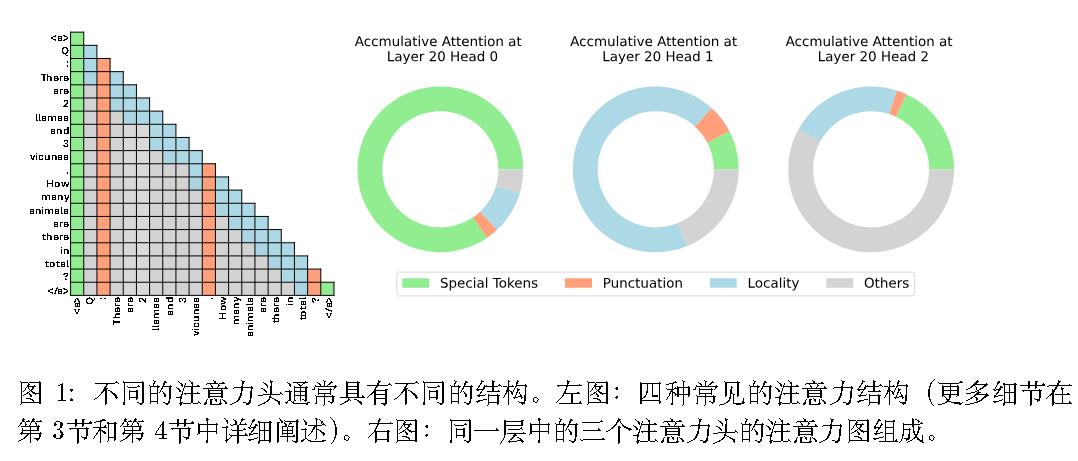
FastGen:四种特殊tokens策略
同年ICLR2024的FastGen(2310.01801)进一步考虑了更多的KV缓存种类。
特殊词元。例如句子开始词元 < s> ,指令词元 [INST] 等。此策略称为 $C_{special}$。
标点符号。仅在 KV 缓存中保留标点符号,称之为$C_{punct}$。
局部性。类似窗口注意力。称之为$C_{local}$
频繁项。监控每个词元的注意力得分的累积和,然后将这些得分视为词元 频率,并在 KV 缓存中仅保留最频繁的词元。称之为$C_{frequent}$。
H2O:更灵活的位置
2306.14048
(NeurIPS 2023)
H2O(Heavy Hitter Oracle)可以说是StreamingLLM的前身,StreamingLLM作者也从中得到启发。它没从长度外推入手,而是只从KV cache入手。
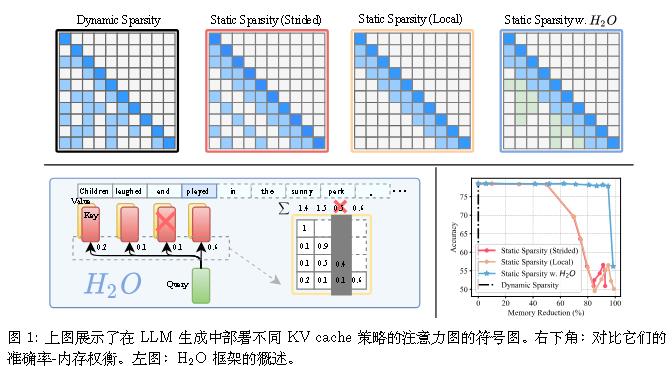
相当于仍保持StreamingLLM的特殊Tokens数不变,但不限制其位置为初始,而使用贪心算法来实现。

伪代码:
1 | |
PyramidKV:初始token以外的attention sink
(拒 ICLR 2025)
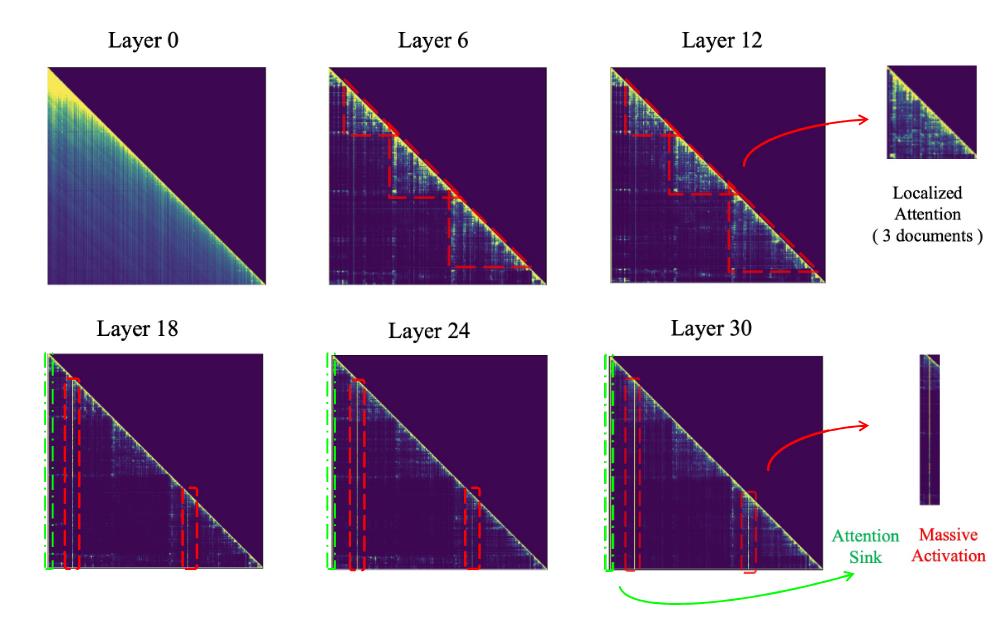
作者发现注意力不仅在除了初始tokens以外的位置也会呈现出attention sink,而且还会呈现出阶梯状。
故可以在不同层动态调整键值缓存大小,在较低层分配更多缓存,在较高层分配较少缓存。
该论文的发现和《Attention Sinks and Outlier Features: A ‘Catch, Tag, and Release’ Mechanism for Embeddings》的观点类似。
验证了attention sink是由低秩结构产生的。
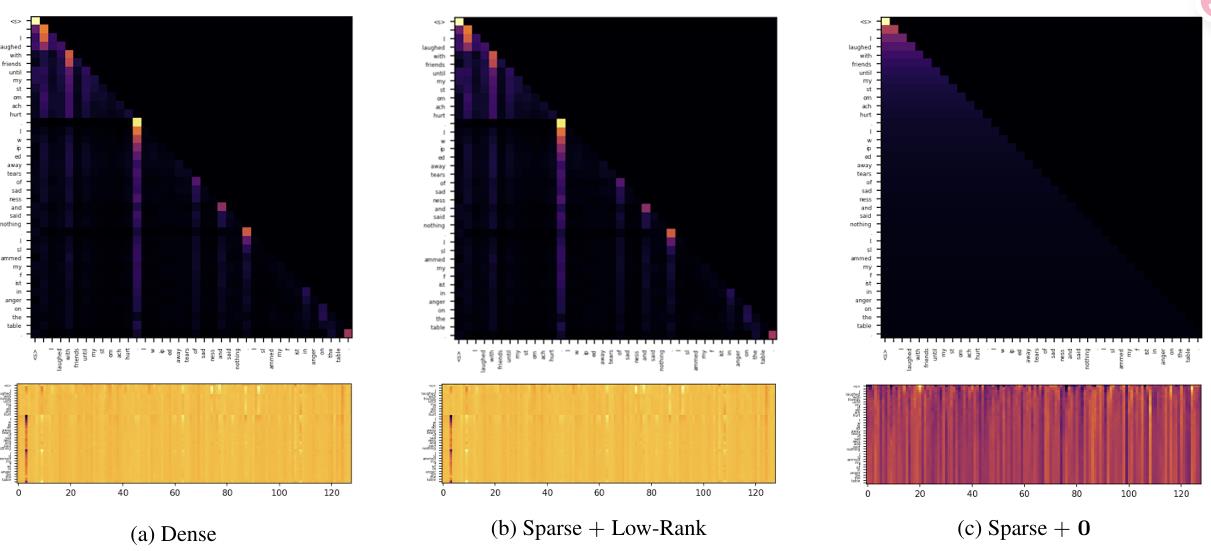
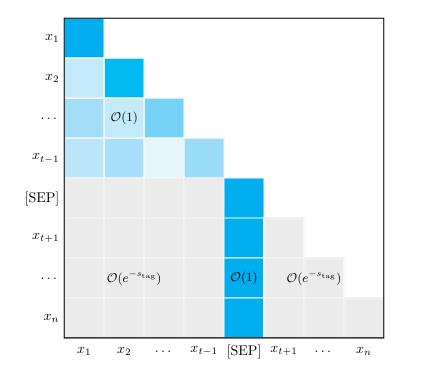
并从数学的角度考虑了一个双层attention、能求平均值的模型的attention map,得出其形状为:
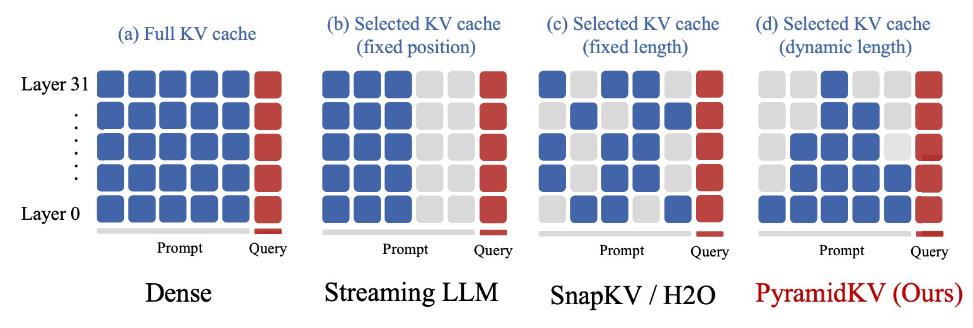
SepLLM:针对标点符号的attention sink
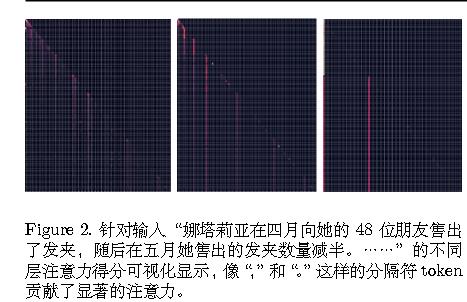
作者发现,LLMs 并未将注意力集中在具有语义意义的 token(如名词和动词)上,而是倾向于优先关注看似“无意义”的分隔符 token(如“.”或“\n”)以进行信息检索。这一观察表明,段落信息被压缩并嵌入到这些分隔符 token 中,从而无需直接从内容 token中提取即可实现高效的信息检索。
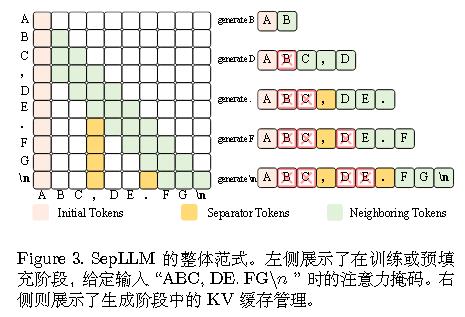
但作者其实并不只使用标点符号,也加入了StreamingLLM所用的初始tokens。具体如下图所示:
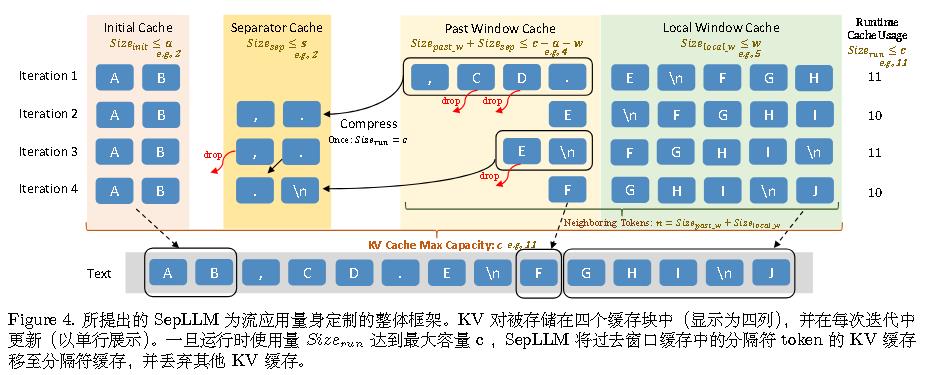
其和FastGen有些类似,FastGen相当于Past Window Cache为无限大,而不是局部的。
Attention Sink是必要的吗?
Attention Sink已广泛应用于流式/长上下文生成、KV 缓存优化、推理加速、模型量化等场景。
ICLR 2025的《When Attention Sink Emerges in Language Models: An Empirical View》详细研究了attention sink,但仍表示“是否有利于语言模型的下游性能仍不明确”。
此外,也涌现了Softpick、gated attention等无attention sink的模型,足以说明并不一定是必需的。
Attention Sink 的产生
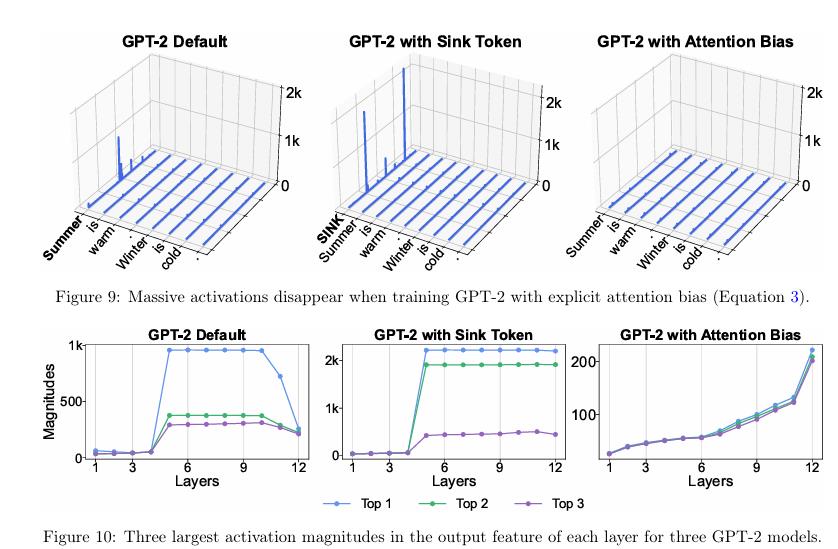
(ICLR 2025)的《When Attention Sink Emerges in Language Models: An Empirical View》指出:
1. 在语言模型通过充足训练数据进行有效训练后,注意力汇聚现象显现。采用较小学习率训练的语言模型中,此现象显得不那么明显。而权重衰减则促进了注意力汇聚的形成。
2. 汇点位置与损失函数及数据分布高度相关,并可移动至除首个 token 之外的其他位置。
3. 位置嵌入、FFN 设计、LN 位置以及多头设计不会影响注意力汇的出现。注意力汇聚点更像是一种键偏置,它存储了额外的注意力,同时不参与价值计算。这一现象(至少部分)源于 token 对注意力得分的内部依赖,这种依赖是由Softmax 规范化引起的。通过用其他注意力操作(如无规范化的 Sigmoid 注意力)替代 Softmax 注意力来缓解这种依赖后,在参数规模高达 1B 的语言模型中,注意力汇聚点不再出现。
《Why do LLMs attend to the first token?》指出:
1.attention sinks对于控制秩崩溃、表示崩溃和过度挤压是有用的。
2.更大的模型和经过更长上下文训练的模型应该具有更强的汇点。
3.无论在预训练期间是否包含 〈bos〉 ,attention sinks都会形成。
(COLM 2024)《Massive Activations in Large Language Models》提出了Massive Activations的特征,并指出与attention sink。
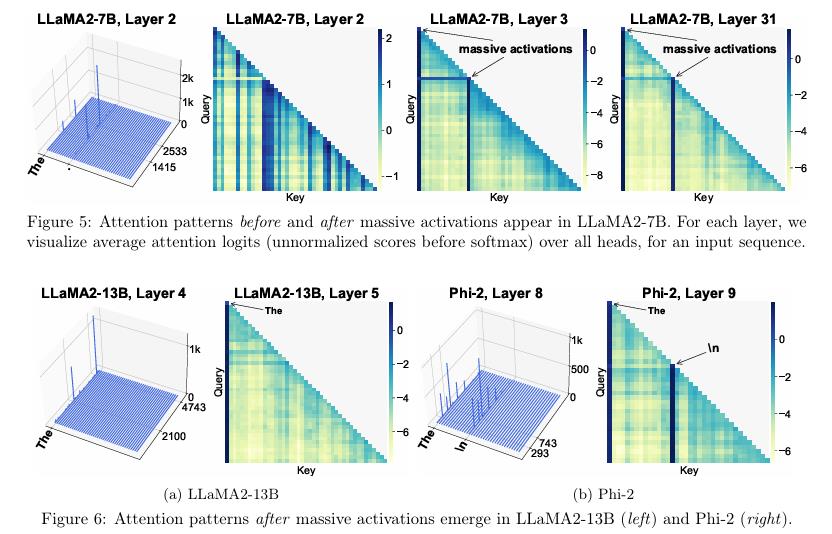
layernorm可以消除影响。
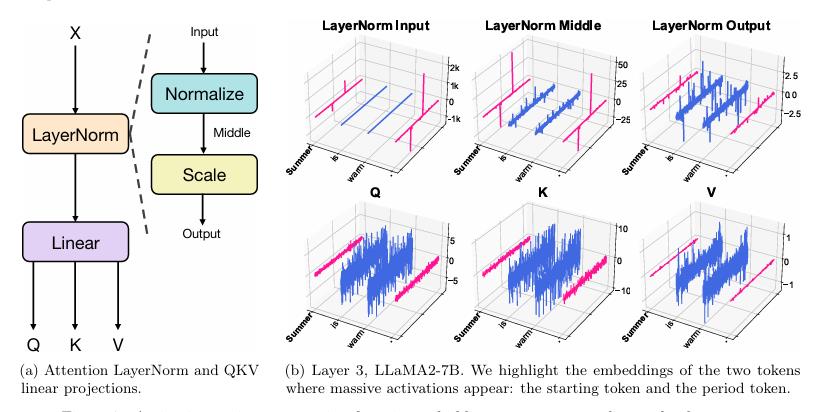
Massive Activations本质上是充当bias的作用。
《Unveiling Super Experts in Mixture-of-Experts Large Language Models》进一步研究了MOE中的Massive Activations,并发现了超级专家。
ICLR 2025 的《Systematic Outliers in Large Language Models》研究了更多的情况。
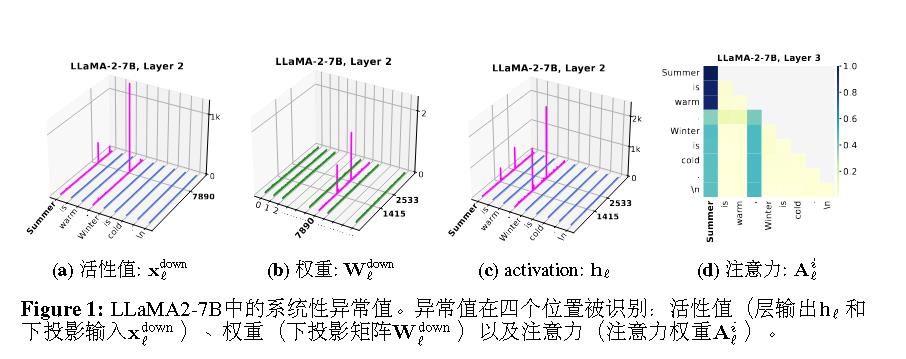
出现异常的位置:
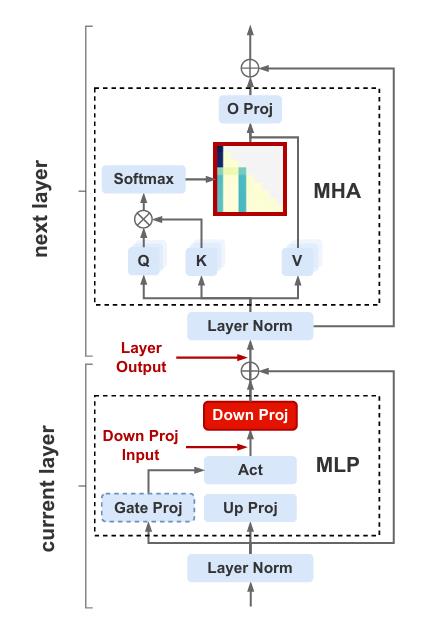
另外,该文还发现尽管这些token受到了显著的注意力,其对应的值向量(V)却显示出相对较小的幅度。这表明,虽然异常值token吸引了注意力,但它们可能对最终输出的直接贡献较少。
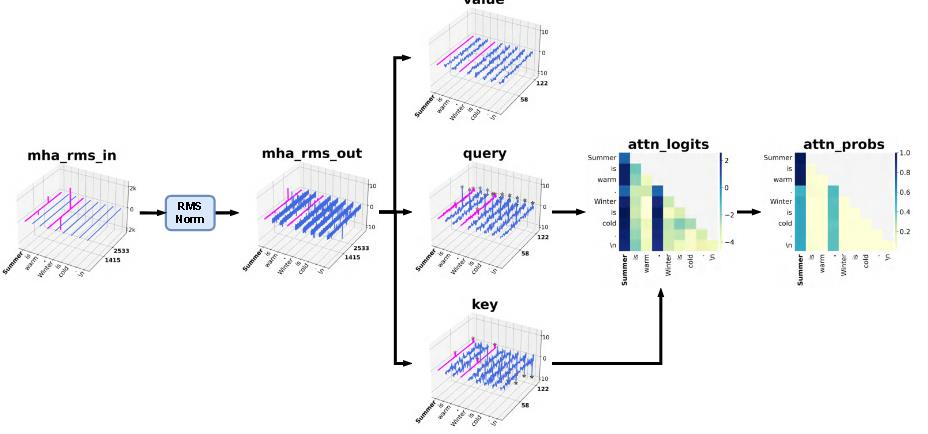
论文中没有提到,但是可以从论文中看到的一点是,rmsnorm和layernorm类似,也可以消除一定影响。
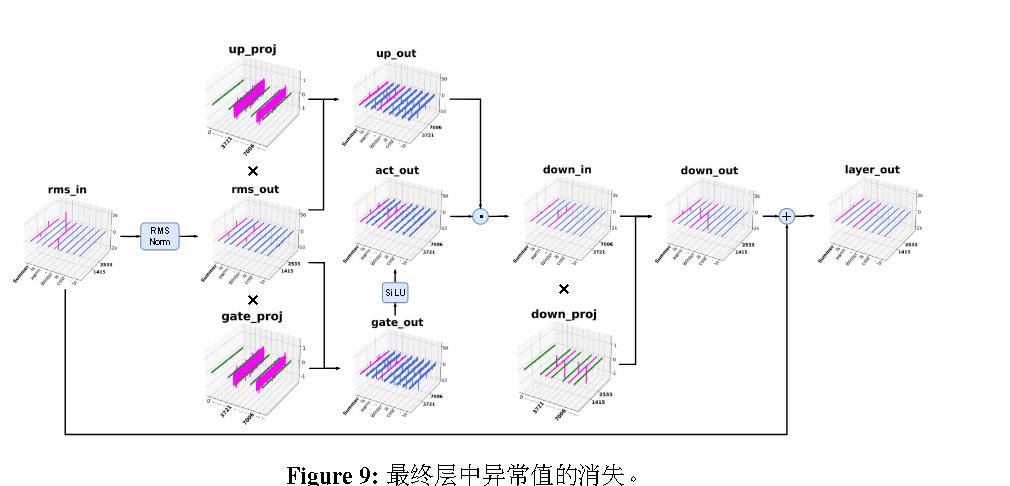
Attention Sink是引起幻觉的元凶
像博客之前介绍过的OPERA则指出了这一点。