多模态速览
基于李沐老师的《多模态论文串讲》,发布于2023年初左右。
发布之始已经看过。由于近日学习的需要,重拾并整理。
多模态基本任务
虽然今天只会涉及一部分,但我们也有必要大概了解。
多模态理解 (Multimodal Understanding):
这类任务侧重于让AI理解不同模态之间的关联和意义。
- 图像描述生成 (Image Captioning): 给定一张图像,AI生成一段描述图像内容的文本。例如,看到一张“一只猫坐在沙发上”的图片,AI能生成文字描述“一只橘猫正舒适地躺在棕色沙发上”。
- 视觉问答 (Visual Question Answering, VQA): 结合图像和自然语言问题,AI回答问题。例如,给出一张图片并问“图中有几只狗?”,AI需要理解图像内容并提取相关信息进行回答。
- 视频理解 (Video Understanding): 分析视频内容,包括识别视频中的活动、事件、人物等。这可以包括视频摘要、行为识别、以及对视频内容的问答。
- 跨模态检索 (Cross-modal Retrieval): 使用一种模态的数据(如文本查询)来检索另一种模态的数据(如图像或视频),反之亦然。例如,输入一段文字描述“日落时分的沙滩”,系统能检索出相关的日落海滩图片。
- 情感识别 (Sentiment Analysis): 结合文本、语音语调和面部表情等多种模态信息来更准确地判断用户的情绪。
- 多模态机器翻译 (Multimodal Machine Translation): 在翻译文本的同时,考虑视觉或听觉信息,以提高翻译的准确性和语境理解。
多模态生成 (Multimodal Generation):
这类任务要求AI根据一种或多种模态的输入,生成另一种或多种模态的输出。
- 文本到图像生成 (Text-to-Image Generation): 根据文本描述生成对应的图像。例如,输入“一只穿着宇航服的猫”,AI能够生成符合描述的图像。Stable Diffusion 和 DALL-E 等模型就是这方面的典型代表。
- 图像到文本生成 (Image-to-Text Generation): (这与图像描述生成类似,但在某些语境下,生成更具创造性或特定风格的文本也属于此范畴)。
- 文本到语音生成 (Text-to-Speech, TTS): 将文本转换为自然流畅的语音。
- 语音到文本生成 (Speech-to-Text, STT): 将语音转换为文字,通常称为语音识别。
- 图像/视频到语音/音乐生成: 根据图像或视频内容生成相关的声音或音乐。
- 3D 内容生成: 结合文本或其他模态信息,生成三维模型或场景。
多模态交互 (Multimodal Interaction):
这类任务侧重于AI与用户之间,或AI系统内部不同模态之间的动态交互。
- 对话系统 (Conversational AI): 结合语音、文本、甚至视觉信息,实现更自然、更富有语境的对话。例如,一个智能助手不仅能理解用户的语音指令,还能根据屏幕上的视觉信息给出更精准的回答。
- 机器人学与具身智能 (Robotics and Embodied AI): 让机器人能够通过视觉、听觉、触觉等多种感官感知环境,并做出相应的动作。
- 人机交互 (Human-Computer Interaction, HCI): 探索更自然、直观的多模态交互方式,如手势控制、眼动追踪等。
多模态表示学习 (Multimodal Representation Learning):
这类任务的目标是学习如何将不同模态的数据映射到一个共同的、有意义的表示空间中,以便于后续的任务处理。
- 联合表示 (Joint Representation): 将来自不同模态的数据映射到同一个向量空间中,使得不同模态之间的语义相似性可以在这个空间中衡量。
- 协同表示 (Coordinated Representation): 学习不同模态的单独表示,但这些表示可以通过一些机制(如共享的语义概念)相互关联。
从ViLT引入
当前的视觉与语言预训练(VLP)方法高度依赖于图像特征抽取过程。则效率/速度方面存在问题,即仅仅提取输入特征所需的计算量远大于多模态交互步骤;且在表达能力方面,因为它的表达能力受限于视觉嵌入器及其预定义的视觉词表。
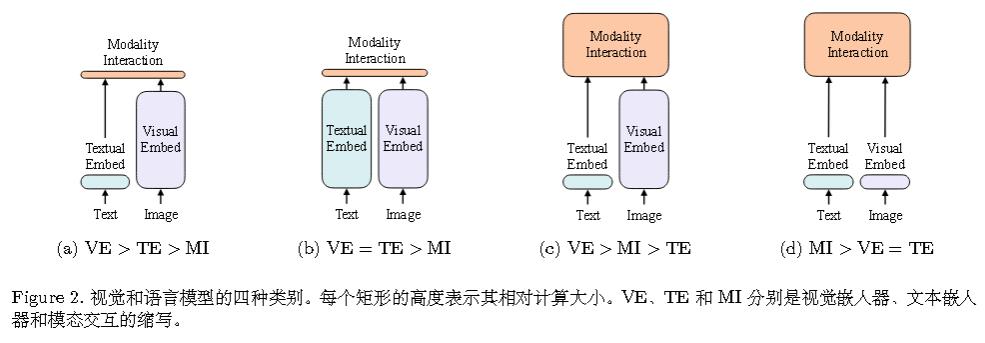
早期的都依赖预训练的目标检测器。
第一种就是早期的工作。 比如VSE(visual-semantic embeddings)或者VSE++。
VSE++的主要贡献是将难例负样本纳入损失函数中,主要是在损失函数的创新。
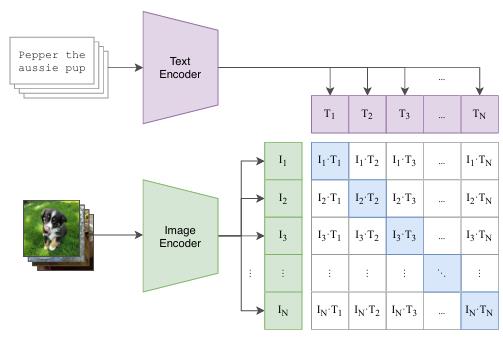
第二种是CLip。
前两种模态之间只进行简单的交互。
比如Clip只做简单的点积。
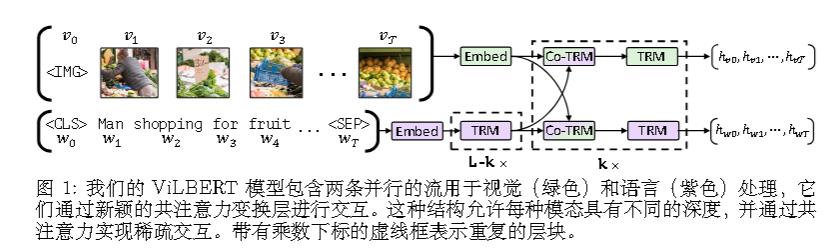
第三种就是OSCAR 、VILBERT、UNITER等模型的思路。
这一代开始认为,模态之间更深层的交互更重要。
OSCAR:

VILBERT:
UNITER:
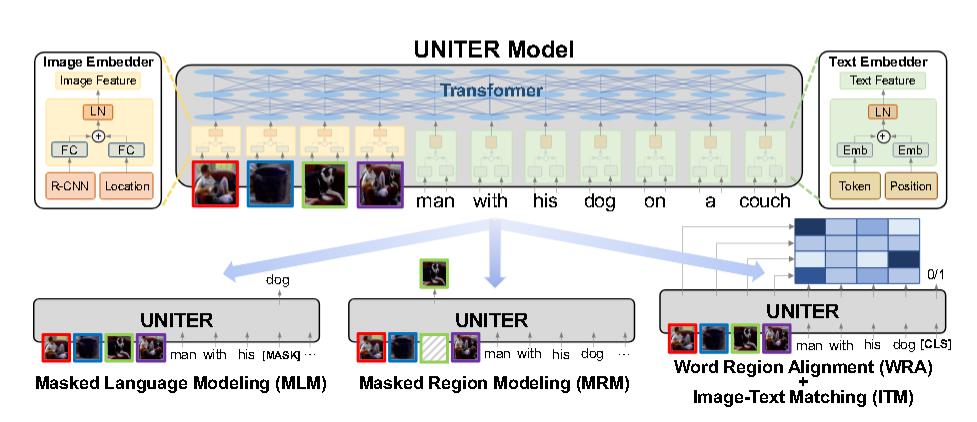
UNITER和OSCAR的处理方式让我想到了博客之前介绍的Fuyu。
前三种的缺点则是模型参数过大,效率/速度较慢。
第四种则是VilT。
自VIT出来后,由于patch都能蕴含信息,它实际上和目标检测的锚框是相似的,故ViLT 把预训练的目标检测器换成了一层可学习的 Patch Embedding。
当然伴随着参数的减小,模型的性能也变差了,不如第三类。(想到了No free lunch theorem)
而我们的数据集是更偏向图像而非文本。所以理论上,需要更强的视觉模型,而ViLT的文本部分强于视觉部分。
另一个缺点是训练时间很慢。
而ViLT发现Word Patch Alignment(WPA) loss非常慢。故可以考虑把它删去。
ALBEF
我们把以上的得到的内容综合,这正是ALBEF(Align before Fuse, 出自Salesforce Research,提出了Blip之类的高质量多模态模型)。
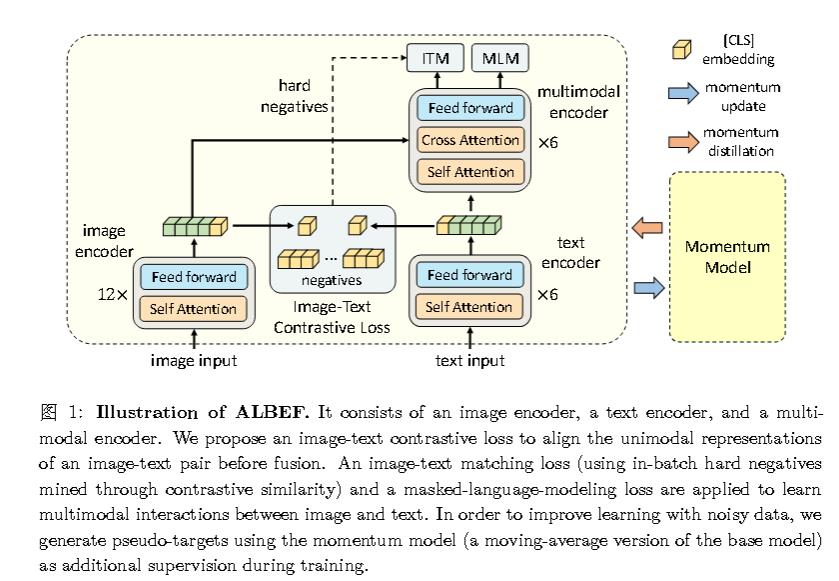
其中结构如图,并只用到了ITC、ITM、MLM loss。
让我们具体详解。
ViLT弃用预训练的目标检测器是因为觉得参数过大会导致推理速度太慢了,而ALBEF则认为预训练的目标检测器没有端到端训练,故视觉和文本特征并不是对齐的。这是第一个贡献。
另外,作者认为网络上的数据太嘈杂了,为了从噪声网络数据中更好地学习,作者还提出了动量蒸馏,这是一种自训练方法,它从动量模型(出自MoCo,与主模型是同一个模型,参数由指数滑动平均得出)生成的伪目标中学习。这是第二个贡献。
Image Embedding 部分使用了标准的 ViT 模型,而文本部分相当于BERT,但是只用前 6 层做文本encoder,剩余部分当做多模态交互的部分。
损失函数
对于前6层使用的ITC loss,是完全按照MoCo的方法来的。先使用softmax对相似度进行归一化(惯用操作了),并将对比损失定义为交叉熵损失。
对于后面使用的ITM loss:
- 给定图片和文本,然后经过 ALBEF 的模型后,得到特征,再过一个FC层,以此做二分类,判断是否为一对。
- 但是判断正样本有点难,但是判断负样本很容易,因此准确度会上升得很快。
- 为解决上面的问题,这里通过某种方式选择最接近正样本的负样本。
- hard negatives :ITM 利用 ITC 把同一 batch 中图片和所有文本都算一遍余弦相似度。 利用最相似的做负样本。
对于后面使用的MLM loss,mask 掉一些文本,然后将 mask 过后的句子和图片一起通过 ALBEF 模型,最后把之前完整的句子预测出来。
要注意的一点是,MLM loss的输入和前两个 Loss 是不同的,分别是($I$,$T$)、($I$,$T_{mask}$),说明模型用了两次forward() 函数。
Momentum Distillation(动量蒸馏)
这部分是用来从噪声网络数据中更好地学习。使用的是自训练方法。
关于噪声和自训练,有谷歌提出的Noisy Student。
具体而言,使用标准交叉熵损失训练一个教师模型。然后,使用教师模型在无标签的图像上生成伪标签,伪标签可以是软的(连续分布),也可以是硬的(独热分布)。然后基于上述有标签和伪标签图像,使用标准交叉熵损失训练一个学生模型。最后,不断迭代这个过程,将学生模型作为新的教师模型,以生成新的伪标签并训练新的学生模型。
博客之前介绍过的《Multi-teacher Self-training for Semi-supervised Node Classification with Noisy Labels》也是类似的方法。
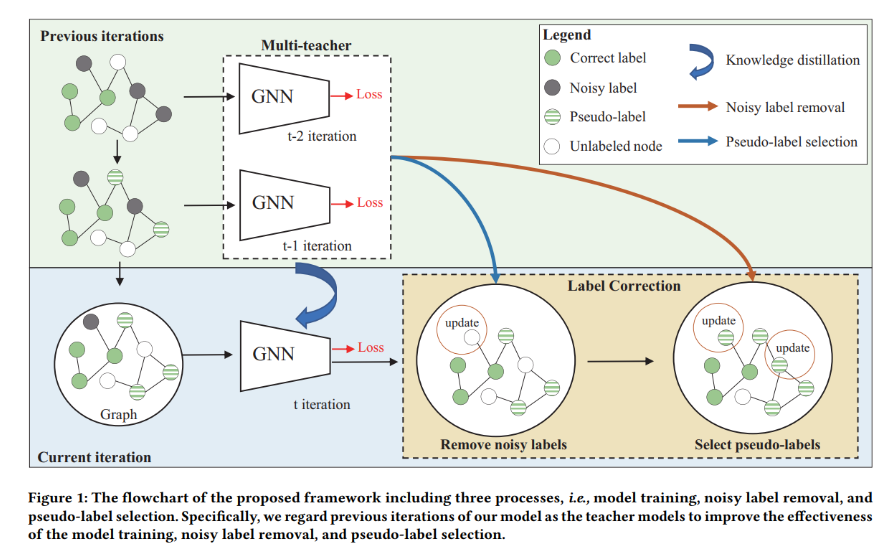
ALBEF的动量模型是个持续演进的教师模型。在训练过程中,训练基础模型使其预测与动量模型的预测相匹配。
这部分只对ITC、MLM做,而不对ITM做。
由于ITM已经有hard negative,所以就没必要再做了。
消融实验
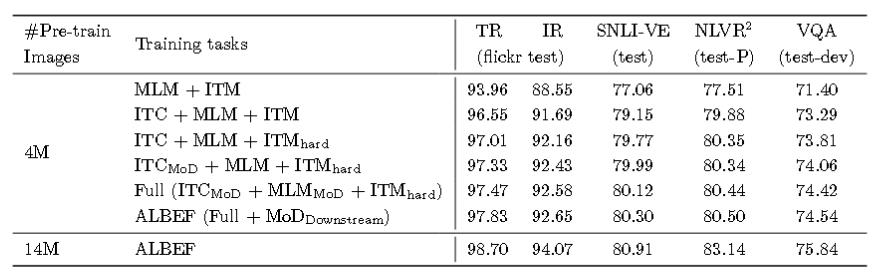
ViLT
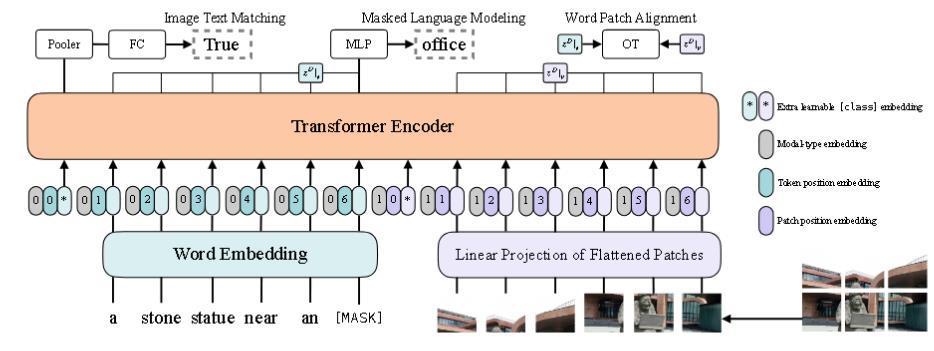
结构方面类似于UNITER和OSCAR,但变得更简单了。
后续的Fuyu则进一步更简化。
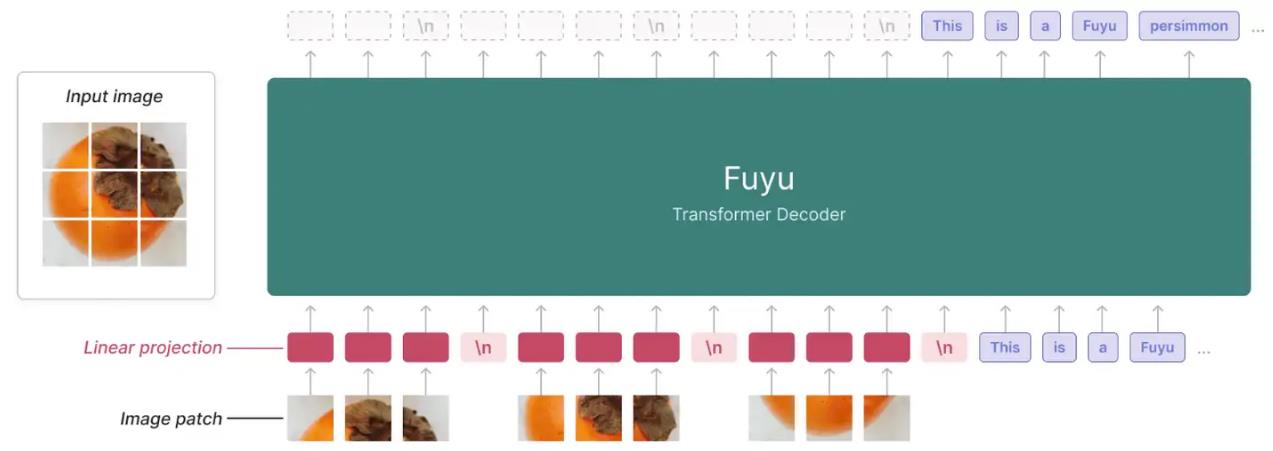
感觉模型发展就是不断往更简化的模式去。就像对比学习中的SimCLR、BYOL再到何恺明更简单的SimSiam。
真可谓大道至简。
VLMo
微软出品。
- 模型结构上的改进 Mixture-of-Modality-Experts
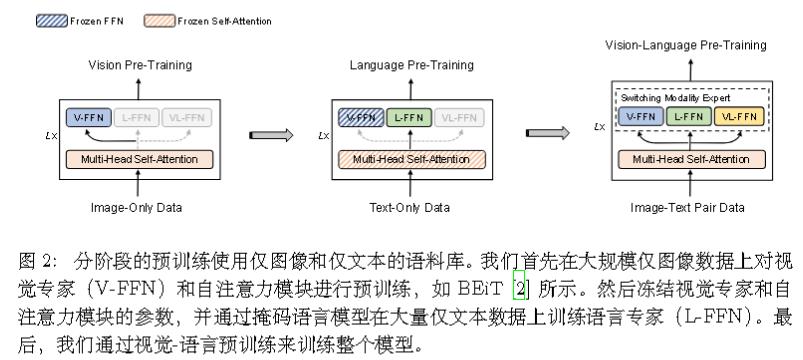
- 训练方式改进:分阶段模型预训练
模型架构:
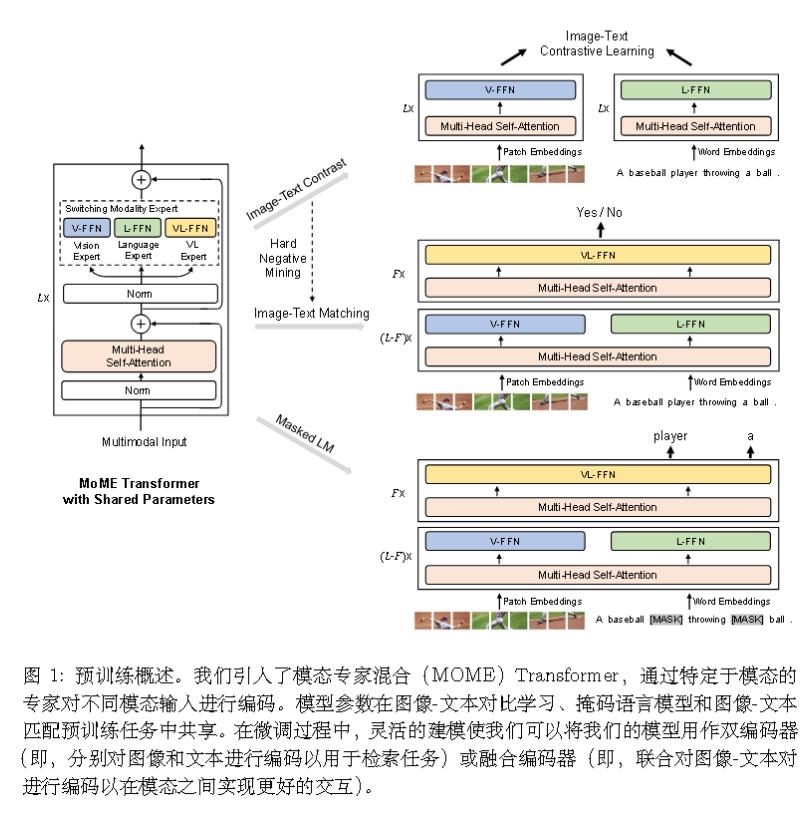
分阶段训练:
未来工作
1.更大模型 —— BeiTv3
2.文本图像都可以mask ——VL-BeiT
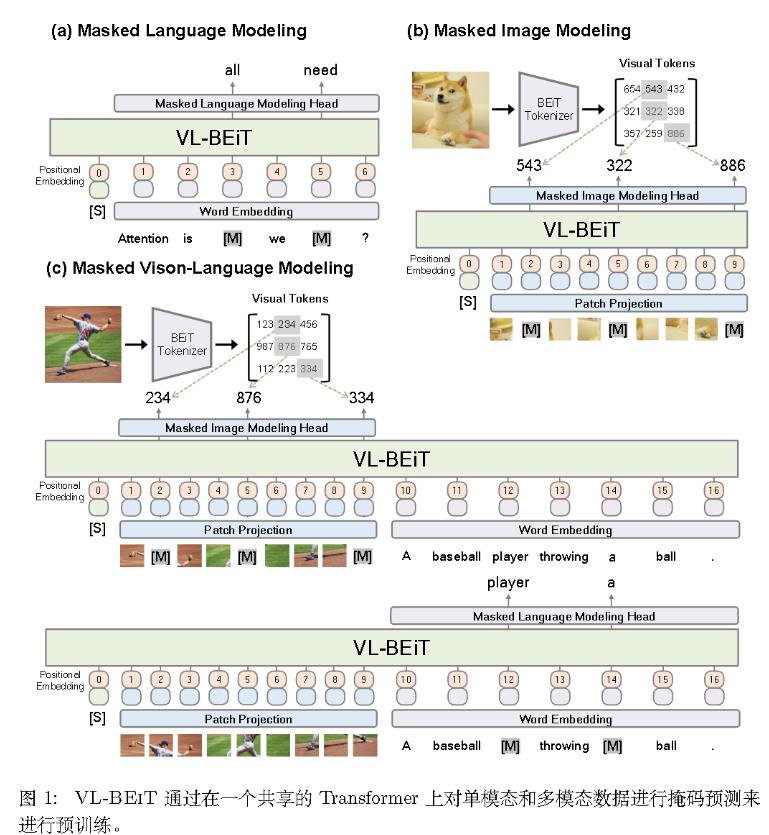
3.单模态可以帮助多模态,多模态也可以帮助单模态——BeiTv3
4.更多模态,如视频等——MetaLM
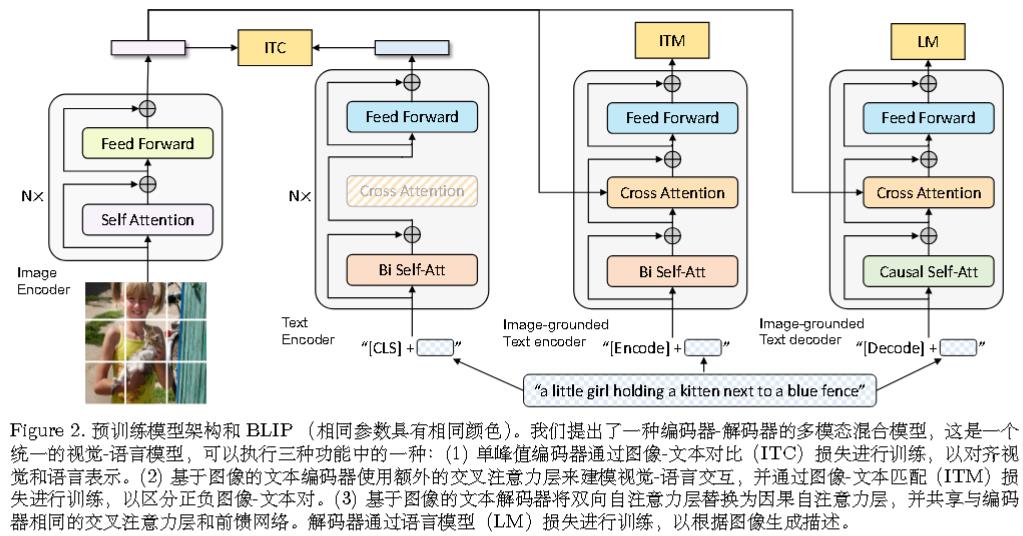
BLip
ALBEF原班人马所做,因此结合了 ALBEF 和 VLMo。
《BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation》
Bootstrap: 先用嘈杂数据训练模型,再用比较干净的数据训练模型。
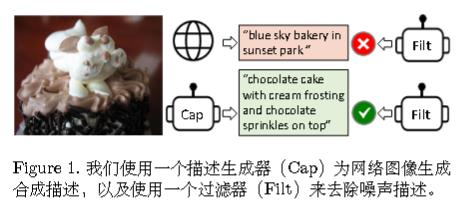
Unified: 统一了图像-语言的理解与生成任务。
架构
CoCa
谷歌出品,《CoCa: Contrastive Captioners are Image-Text Foundation Models》
也是ALBEF的一个后续工作。
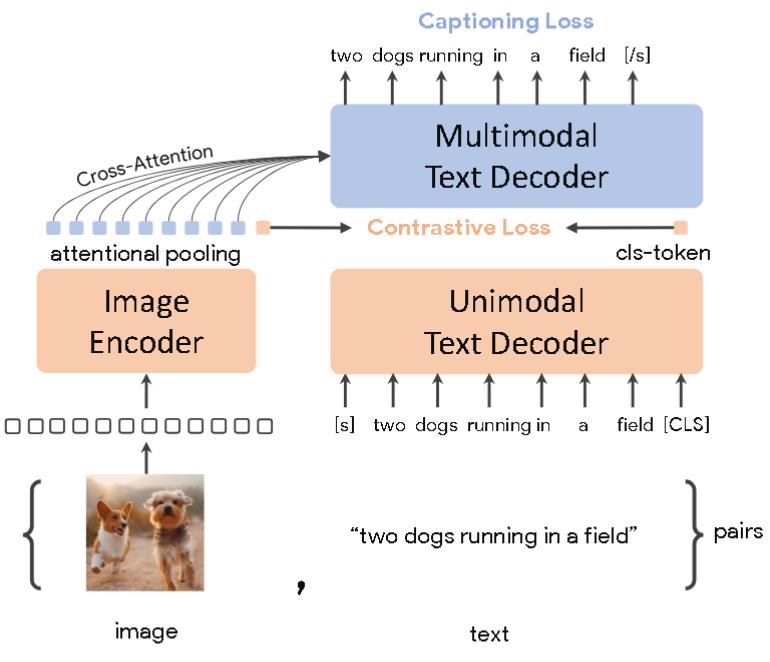
图像部分使用Encoder,文本部分全用Decoder。
因为效率问题所以如此设计。解耦的自回归解码器设计的一个主要优势是它可以高效地计算两种训练损失。由于单向语言模型是在完整句子上使用因果掩码进行训练的,因此解码器可以通过一次前向传播高效生成对比损失和生成损失的输出。而前面提到的方法需要两次。
BEITV3
《Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks》
引言:大一统
第一,Transformer的成功从语言问题和多模态问题中得到了体现。网络结构的合一使我们能够无缝处理多种模态。对于视觉-语言建模,由于下游任务的不同性质,有多种应用 Transformer 的方式。
例如,双塔结构用于高效检索,编码器-解码器网络用于生成任务,融合编码器结构用于图像-文本编码。
然而,大多数基础模型必须根据特定架构手动转换终端任务格式。此外,参数通常在不同模态之间无法有效共享。在本工作中,采用 Multiway Transformers 进行通用建模。其实是VLMO的Mixture of Modality Experts。
第二,基于掩码数据建模的预训练任务已被成功应用于各种模态。当前的视觉-语言基础模型通常多任务其他预训练目标(如图像-文本匹配),导致缩放不友好且效率低下。
相反,该作仅使用一个预训练任务,即掩码-预测,来训练一个通用的多模态基础模型。通过将图像视为一种外语,我们以相同的方式处理文本和图像,而没有根本性的建模差异。因此,图像-文本对被用作“平行句子”,以学习不同模态之间的对齐.
第三,普遍地扩大模型规模和数据规模可以提高基础模型的泛化质量,从而使它们能够转移到各种下游任务中。
算法
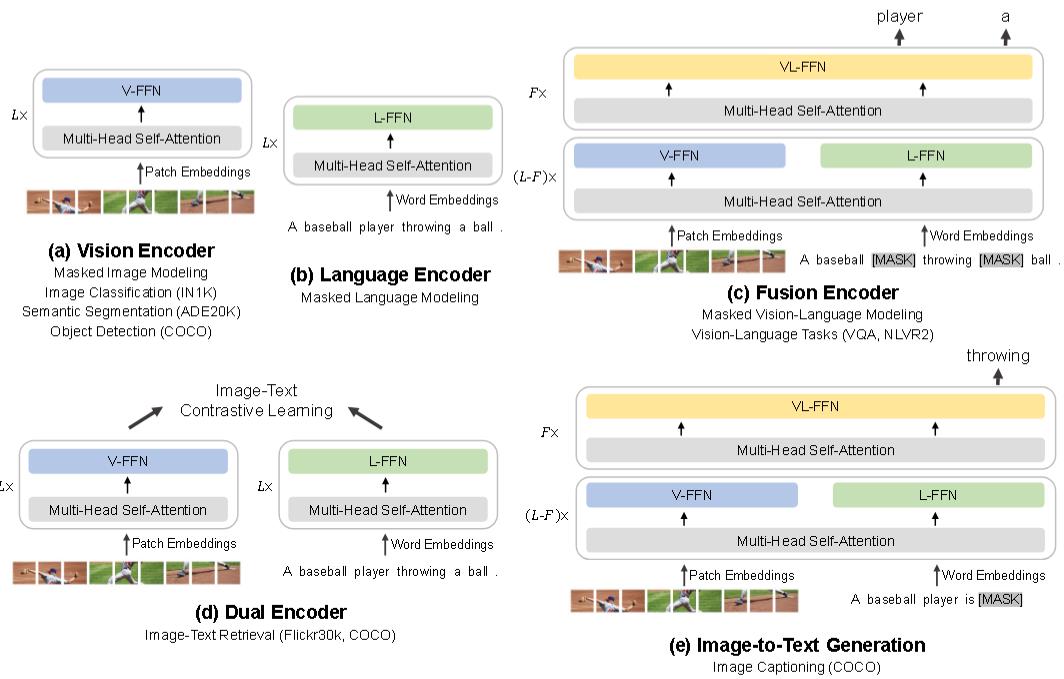
架构:
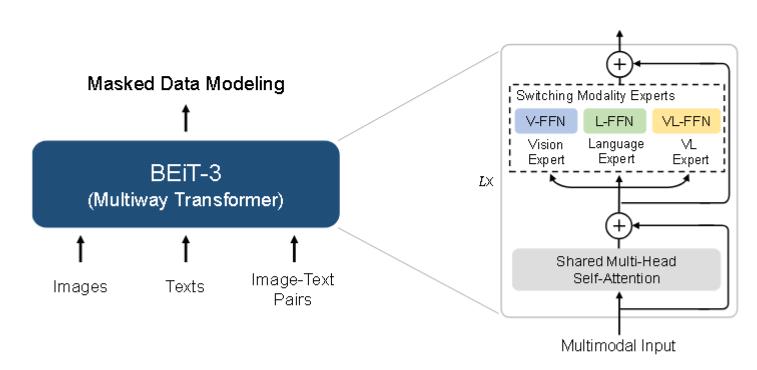
EBiT-3 可以转移到各种视觉和视觉-语言下游任务。通过一个共享的 Multiway Transformer。
参考资料
1.李沐老师的《多模态论文串讲》