快手推荐系统模型速览
推荐模型的一个大概结构如图所示。
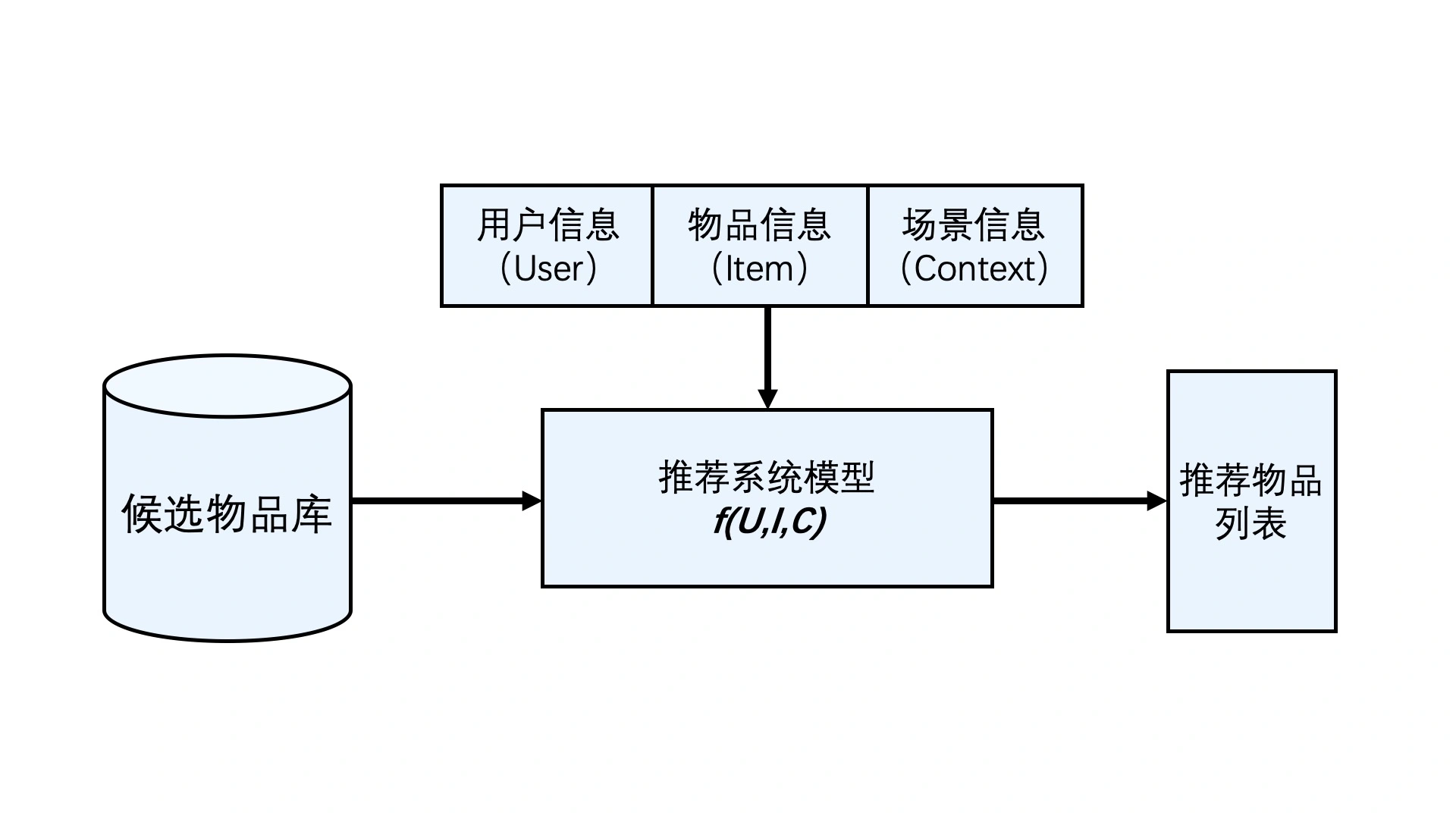
我们将要介绍快手的几个推荐系统模型。QARM和OneRec。
我们将按时间顺序介绍。
QARM
QARM= Quantitative Alignment Multi-Modal Recommendation
作者认为由于计算代价过大,导致业内通常使用非端到端的模型——二步部署方案,先使用MLLM提取embedding,再进一步训练。
Feature->Encoder->Embedding->Model
作者认为这种非端到端的模型有以下问题:
(1)embedding不匹配。
MLLM通常是由图文匹配训练的,而基于ID的特征并不是。
(2)embedding遗忘。
新添加的多模态特征不会随着推荐系统的训练而更新,而其他基于离散ID的特征(用户ID、物品ID等)可以实时端到端优化。
算法
检索模型遵循的经典设计:
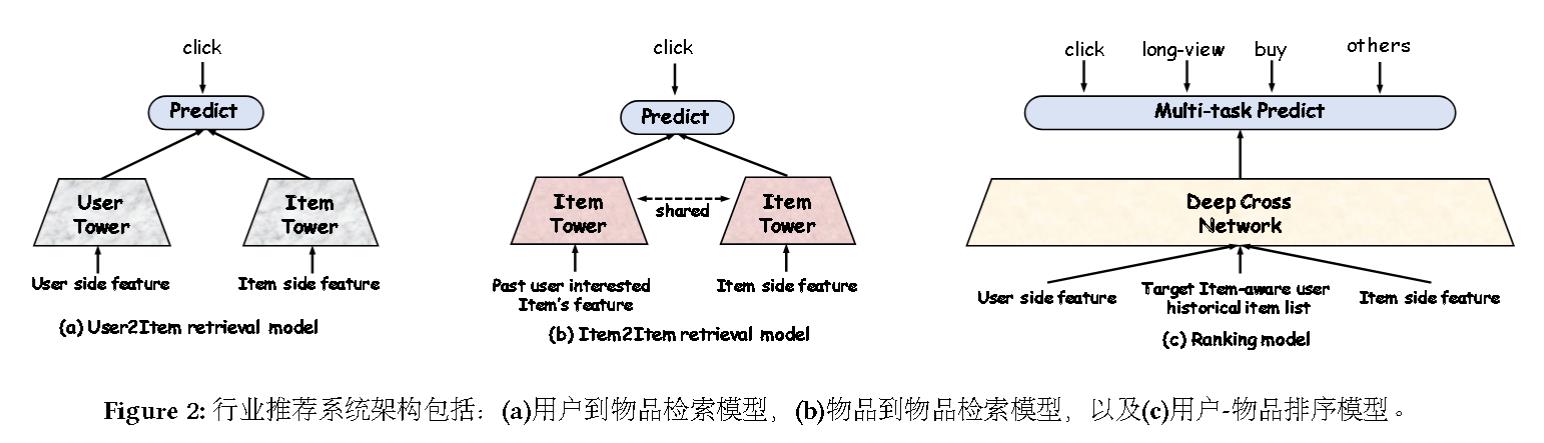
这也就是推荐系统常用的“双塔模型”。
QARM整体架构:
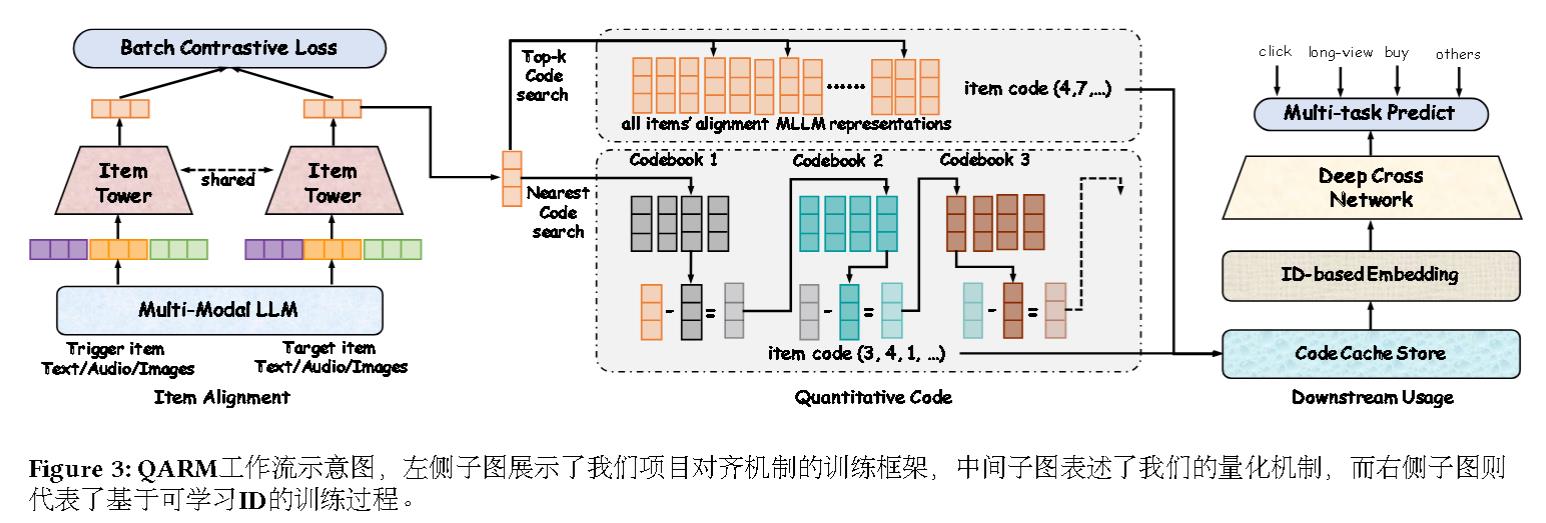
对齐
首先通过以下方式生成高质量的项目对:
基于User2Item检索模型,针对每位用户正向点击的目标项目,从其最近50次正向点击的项目集合中,选取在ID表示空间内相似度最高的项目作为触发项。
基于Item2Item检索模型,利用已学成稳定且高相似度的物品对作为数据源,例如从我们的Swing检索模型中导出的数据。
再通过对比学习进行批量(为$\beta$)训练:
$$
\begin{align}
M _ {trigger}&=MLLM(T _ {trigger}^{text},T _ {trigger}^{audio},T _ {trigger}^{image})\\
M _ {target}&=MLLM(T _ {target}^{text},T _ {target}^{audio},T _ {target}^{image})\\
\mathcal{L} _ {align}&=Batch\_Contrastive(M _ {trigger},M _ {target},\beta)
\end{align}
$$
Quantitative Code
作者首先是将多模态表征量化压缩成语义ID, 再将语义ID输入到推荐模型中。
作者采用了两种量化机制。
一种是最常用的VQ,首先训练一个codebook,然后利用top-k最近邻搜索来哈希表示。
由于预训练的MLLM已经能表示复杂项目的相关系数,故不再训练codebook,而直接采用所有项目的对齐作为codebook。
另一种是RQ,即Residual-Quantized。出自RQ-VAE。
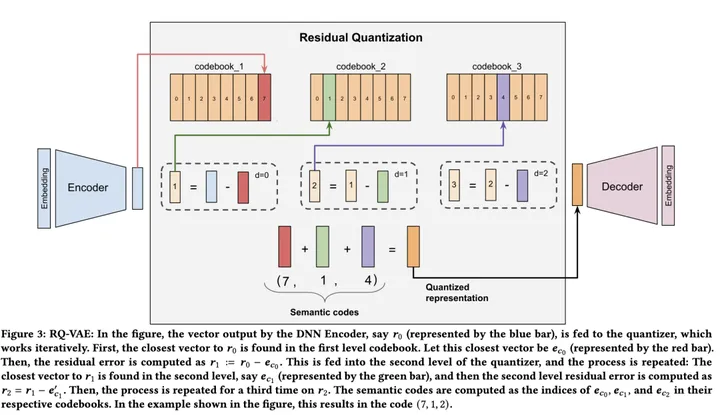
具体而言,
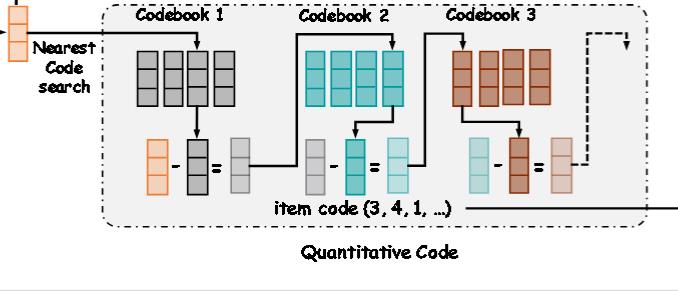

端到端训练
最后将这几个编码作为新的ID特征送入模型中,进行端到端训练:

OneRec
虽然也是快手出品,但研究团队完全换了一批人。
该模型用统一的生成模型替换了级联学习框架。是第一个端到端的生成模型。
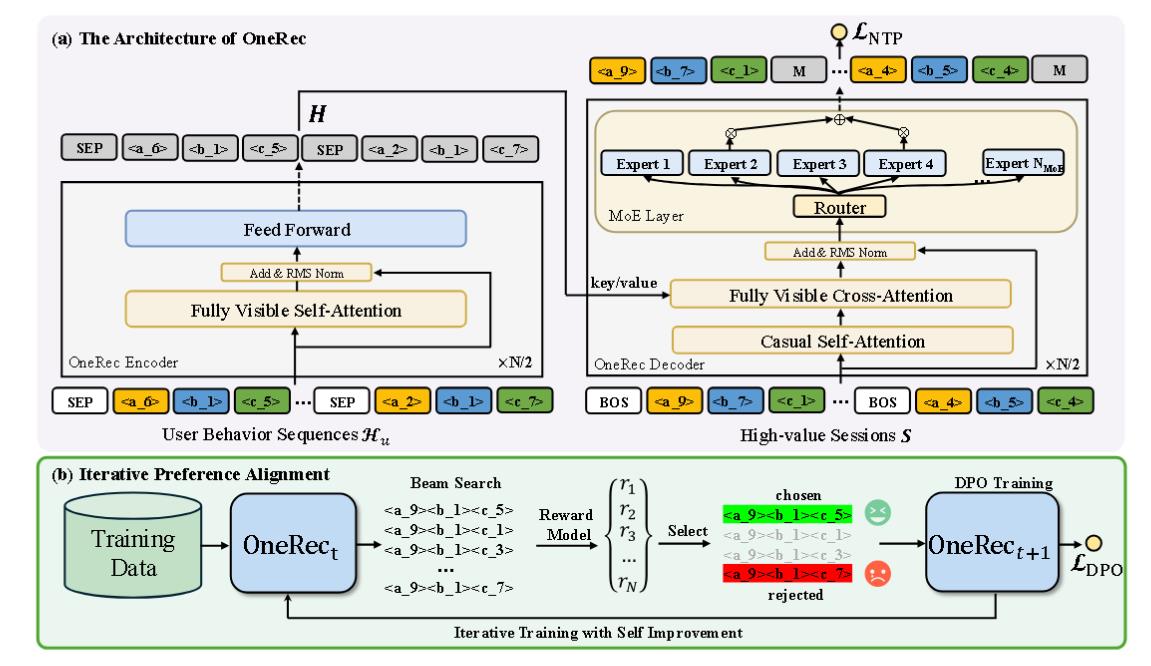
该模型基于tranformer。首先使用QARM的对齐和Quantitative Code的方法来作为Tokenizer,转化为模型可以接受的输入。
完成模型的预训练之后, 由于模型是只预测next-token。所以还会再利用 DPO 等强化学习进行对齐训练。最后,在预测的时候, 通过 beam search 筛选出视频流。
Tokenizer
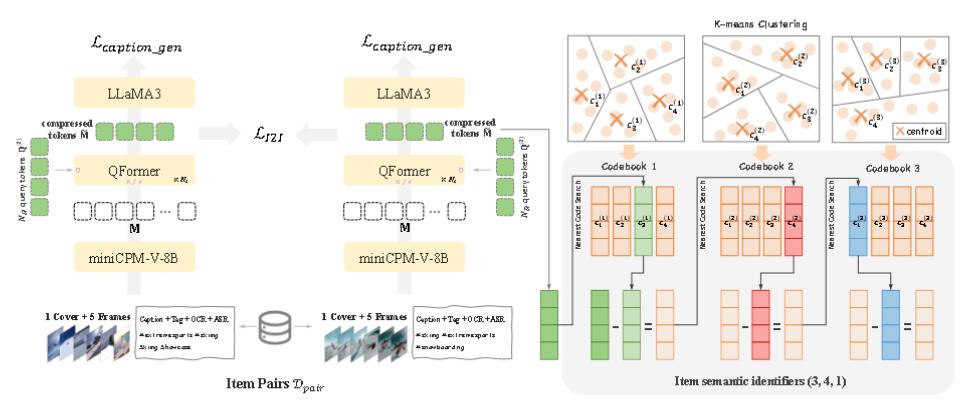
编码器部分
多尺度特征工程
用户静态路径
用户静态路径生成核心用户特征的紧凑表示,包含用户标识符(uid)、年龄(age)、性别(gender)等,随后将其变换为模型的隐藏维度。
短期路径
挑选用户最近交互的 ($L_s=20$) 个视频的 <video identifier, author identifier, tag, timestamp, playtime, duration, labels> 等信息进行融合:
正反馈路径
将用户给与最多正反馈的 ($L_p=200$) 个视频的 <video identifier, author identifier, tag, timestamp, playtime, duration, labels> 等信息进行融合:
对于以上三个部分,变换方式都是:$f_u$为各特征拼接,$h_u=Dense(LeakyReLU(Dense(f_u)))$。
终身路径
终身行为路径旨在处理包含多达 100,000 个视频序列的超长用户交互历史。直接对此类序列应用注意力机制在计算上是不可行的。
行为压缩
使用类似QARM的分层 K-均值,使用最接近簇中心的项目作为该簇的代表。
特征聚合
依旧使用上面的:$f_u$为各特征拼接,$h_u=Dense(LeakyReLU(Dense(f_u)))$。
最后再通过 QFormer 压缩。
解码器
对于每个目标视频 $m$,解码器输入序列通过将可学习的序列起始 token 与视频的语义标识符连接而构造:
$$
S_m = \{s_{\text{EOS}}^1, s_m^1, s_m^2, \dots, s_m^{L_s}\}
$$
$$
d_m^{(0)} = \text{Emb_lookup}(S_m)
$$
解码器通过 $L_{\text{dec}}$ Transformer 层处理此序列。每层执行顺序操作:
$$
d_m^{(l+1)} = d_m^{(l)} + \text{CausalSelfAttn}(d_m^{(l)})
$$
$$
d_m^{(l+1)} = d_m^{(l+1)} + \text{CrossAttn}(d_m^{(l+1)}, Z_{\text{enc}}, Z_{\text{enc}})
$$
$$
d_m^{(l+1)} = d_m^{(l+1)} + \text{MoE}(\text{RMSNorm}(d_m^{(l+1)}))
$$
每个解码器层都包含一个混合专家模型 (MoE) 前馈网络,以增强模型容量,同时保持计算效率。MoE 层采用 $N_{\text{experts}}$ 个专家网络,并采用 top-k 路由策略:
$$
\text{MoE}(x) = \sum_{j=1}^k \text{Gate}_j(x) \cdot \text{Expert}_j(x)
$$
其中 $\text{Gate}_j(x)$ 表示由路由机制确定的权重,$\text{Expert}_j(x)$ 表示第 $j$ 个选定的专家网络的输出。并使用了DeepseekV3的无损失的负载均衡策略。
强化学习
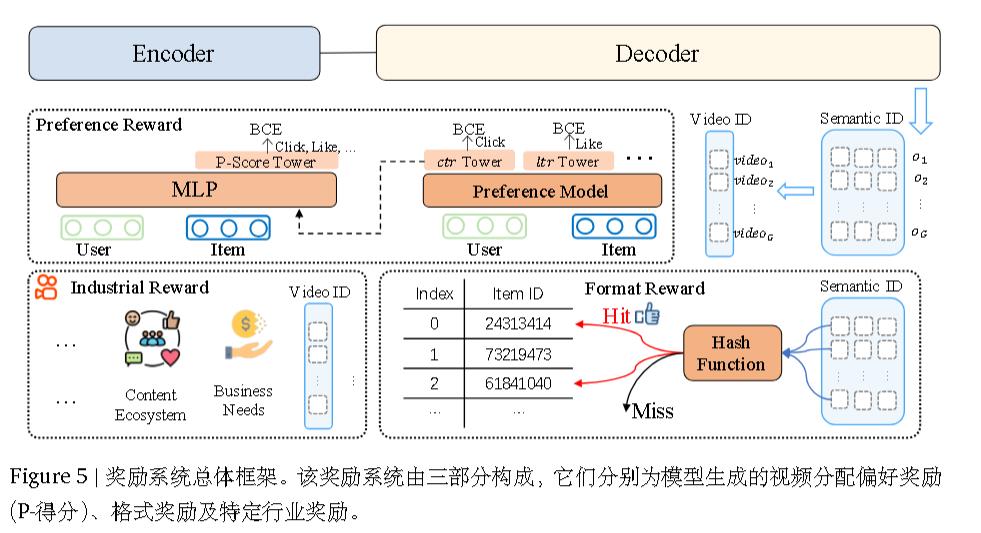
在训练过程中,这些塔使用相应的目标标签作为辅助任务计算二元交叉熵(BCE)损失。每个塔的隐状态,连同用户和物品的表示,被输入到最终层的多层感知机(MLP)中。该 MLP 之后是一个单塔输出 P-Score,它使用所有目标的标签计算二元交叉熵损失。
使用的是GRPO的修改版(被称为早起阶段GRPO,ECPO),具体而言,多了31式:

生成格式正则化
引入强化学习与 ECPO会显著增加了非法输出的生成,即在推
理过程中生成没有对应物品 ID 的语义 ID 序列。
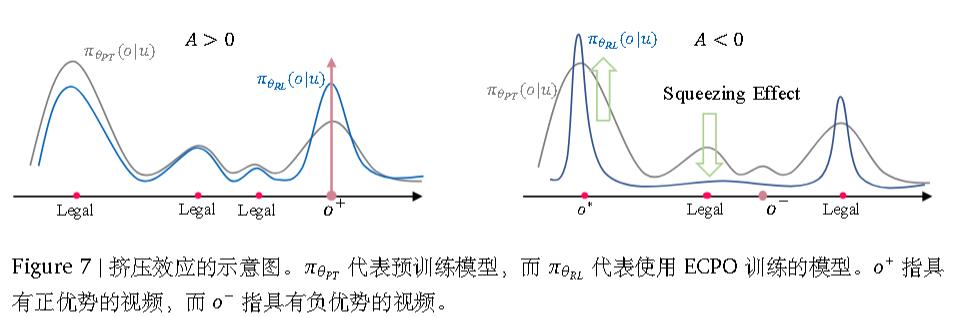
这是由于挤压效应引起的,即当A<0时,一部分合法token被挤压到非法token,使得模型难以区分合法token。
作者直接引入格式奖励以鼓励模型正确生成。具体而言,对合法样本设置为1,对非法样本设置为0,即丢弃。
参考文献
OneRec Technical Report.http://arxiv.org/abs/2506.13695
OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment.https://arxiv.org/abs/2502.18965