方班128期研讨班涉及的一些论文阅读
《方班研讨班课需要把握的要点》——方班示范班第128期研讨厅(复盘课)暨电子科技大学方班实验班成立仪式
虽然这次讲座的核心并不是论文,而是学习方法,但其中提到的不少论文也值得阅读。
全讲座大概3小时,不得不感慨知识密度之密集和院士精力之充沛。
LLMembed
acl 2024
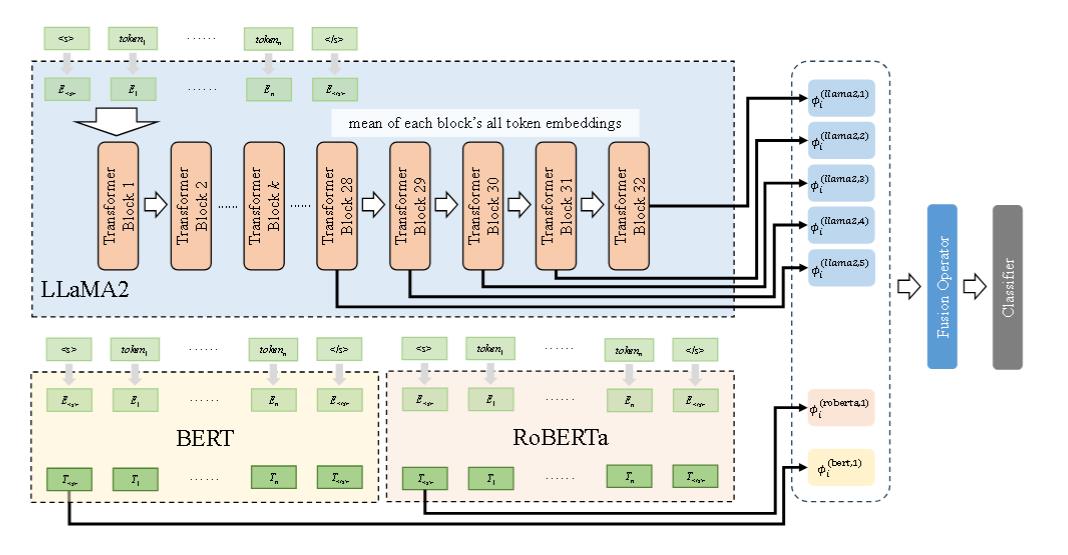
模型结构如下,即综合多个模型,在训练过程中仅训练分类器头的参数。对于 llama2,使用多个网络深度提取嵌入,并通过池化操作进行融合,以提高嵌入的泛化能力。
Toward Efficient Inference for Mixture of Experts
(NIPS 2024) FAIR
动态门控和专家缓冲优化

负载均衡优化
首先进行的是贪心算法,按专家的平均历史负载对专家进行排序,并依次分配专家。
反相关平衡。 当专家激活独立时(LM、MT‑Encoder),贪婪算法是有效的,但当 激活相关时(MT‑Decoder),它的效果较差。改进是计算负载加上了0.5*皮尔逊相关系数。
Parameter Disparities Dissection for Backdoor Defense in Heterogeneous Federated Learning
(NIPS2024)

客户端差异聚类 (Fisher Client Discrepancy Cluster, FCDC)
该组件旨在检测和隔离恶意攻击者 。
1.计算参数重要性: 每个客户端在本地训练后,在其本地数据上计算 FIM (Fisher信息矩阵,Fisher Information Matrix, FIM) 的近似值,以获得一个代表每个参数重要性的向量 。(对应伪代码的5)
在神经网络理论区域,Fisher矩阵可以用hessian近似,而hessian是一个计算量比较大的数值(所以使用hessian的牛顿法比梯度下降法更不流行)。足以见FIM计算量并不小,所以需要近似以加速。
论文近似的方法为直接使用对角线元素。FIM 的对角线元素衡量的是单个参数的重要性,而非对角线元素则描述了不同参数之间的相关性或交互影响。取对角线相当于忽略了不同参数之间的相关性。
然后对该重要性得分进行归一化 (对应伪代码的6)。
2.重加权梯度: 服务器根据每个客户端计算出的参数重要性得分,对其上传的梯度进行重加权 。这一步强调了客户端认为对其本地任务重要的参数更新。

3.衡量差异: 服务器从这些重加权的梯度中计算出一个聚合的全局梯度 。然后,它衡量每个客户端的重加权梯度与这个全局梯度之间的差异(平方差)。其直觉是,专注于不同分布的恶意客户端将显示出较大的差异 。
4.聚类与排除: 服务器使用一种无参数的聚类算法 (FINCH) 对这些差异值进行聚类,将客户端分组 。平均差异较大的聚类被标记为恶意,并通过将其聚合权重设置为零来从最终聚合中排除 。
参数重缩放聚合 (Fisher Parameter Rescale Aggregation, FPRA)
在过滤掉恶意客户端后,FPRA 旨在通过智能地聚合良性客户端的更新来改进学习过程 。
FPRA 不在聚合过程中平等对待所有参数,而是根据每个参数元素的重要性来重新缩放其更新 。
其目标是为被认为重要的参数提供更显著的更新(更高的“可变范围”),从而加速它们对目标分布的适应,同时减弱次要参数的影响 。
RAPIER
(NDSS2024)
动机:良性与恶意流量数据之间具有分布差异
观察到正常数据的分布倾向于相似且稠密,而恶意数据(可能由大量恶意软件生成)的分布则趋于稀疏。
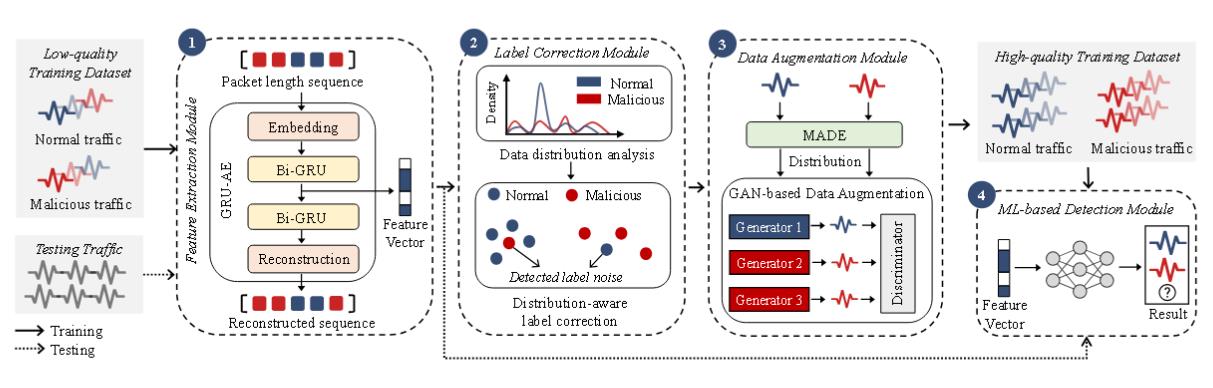
标签矫正。
使用MADE来进行分布估计。
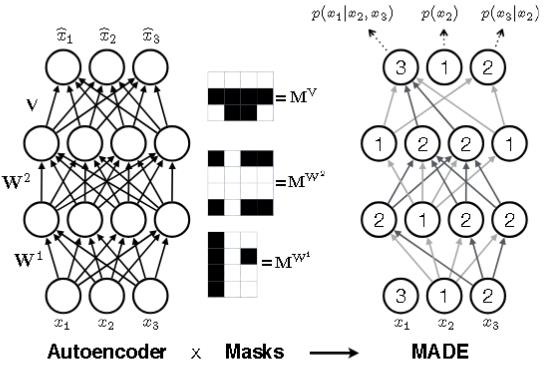
对标签修正后的数据集通过集成学习推断 真实标签。即构建了七个经典机器学习分类器的集成,包括线性判别分析、AdaBoost、随机森林、逻辑回归、高斯朴素贝叶斯、SVC 和 XGBoost。
数据增强。
对标 签校正的原始训练集进行数据增强。使用GAN进行三种数据增强。