VisualMixer-通过像素重排来保护视觉DNN任务的训练数据
(NDSS 2024)该论文提出了一种通过打乱像素来保护DNN图像数据视觉隐私的方法。(很奇妙的方法)
现有技术的局限性:
差分隐私 (Differential Privacy, DP):虽然DP能提供强大的隐私保证,但它通过添加噪声来实现,这些噪声对于人眼来说很容易被过滤掉,因此无法有效保护图像的“视觉特征” 。同时,要达到足够的视觉混淆程度,DP引入的噪声会严重损害模型的准确性 。
同态加密 (Homomorphic Encryption, HE):HE允许在加密数据上进行计算,但其巨大的计算开销使得它在处理高维图像数据时不太实用 。
可信执行环境 (TEE):TEE依赖特定的硬件,并且其有限的资源和兼容性问题限制了在DNN计算中的应用 。
算法
主要关注以下三种攻击。
访问客户端上传的数据。 服务器上的攻击者可以直接访问客户端上传的数据。即使客户端对其图像进行了混淆,攻击者仍会尝试通过暴力破解或启发式攻击来恢复原始视觉特征。
重构 DNN 训练数据。 攻击者可以对训练好的 DNN 模型进行成员推断攻击,以识别训练过程中所
用数据的所有权 。此外,他们可以利用数据增强方法,如基于 GAN 的数据重构,生成视觉特征,并根据客户端上传数据训练的模型权重恢复部分私有训练数据的信息。
恢复中间梯度和特征。 攻击者基于训练和推理过程中的中间梯度和特征图重构视觉上可区分的图像
视觉特征熵 (Visual Feature Entropy, VFE)
论文首先定义了一个视觉特征熵的概念。

论文中说:VFE值越高,代表图像的梯度变化越密集,视觉上越难识别,隐私性越强 。这个指标是与具体任务无关的(task-agnostic),因此具有普适性 。
其实这和用于边缘检测的sobel算子很相似。
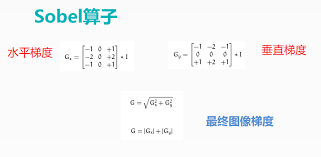
另一角度来说,包含边缘信息可能包含更多的纹理和细节,可能包含更多有用的特征。
VisualMixer (VIM)
这一部分用来打乱图像。
非均匀混淆 (Non-uniform Shuffling):与在整张图上采用统一策略不同,VisualMixer认为图像的不同区域包含不同的信息量 。它根据VFE值对图像进行非均匀处理:
对于VFE值较低的区域(通常是背景等平滑区域),使用较大的混洗窗口(Window Size, WS),混淆强度更高 。
对于VFE值较高的区域(通常是包含重要特征的区域),使用较小的混洗窗口,以保留更多结构信息,保证数据可用性 。
空间与通道混洗 (Spatial and Per-channel Shuffling):在每个选定的窗口 内,VisualMixer执行两种混洗操作:
空间混洗:在二维空间上随机打乱像素的位置 。
通道混洗:在每个颜色通道(R, G, B)内部独立地混洗像素值 。这能有效破坏颜色特征,同时对纹理和结构特征影响较小,这些特征对视觉任务更为重要 。
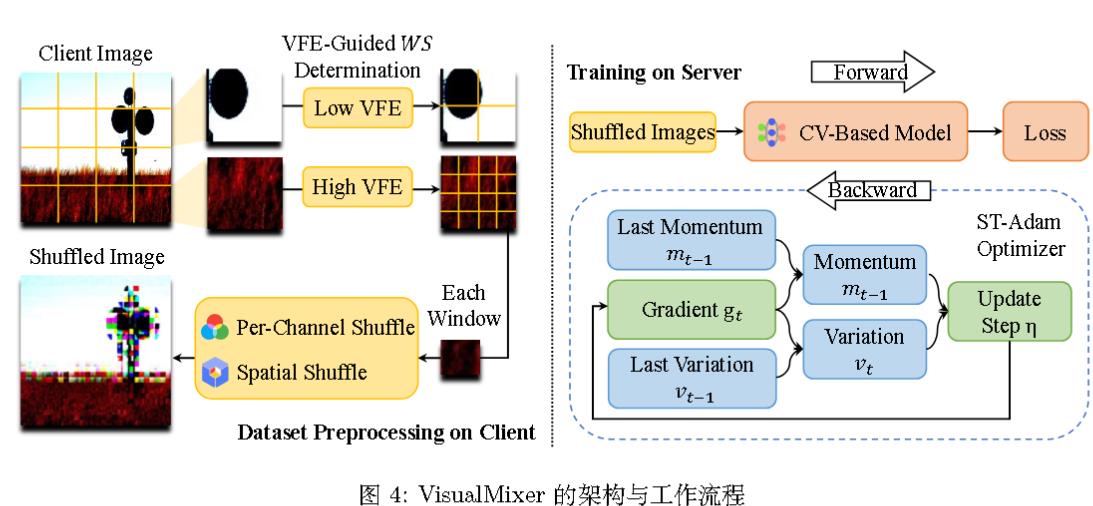
per-channel-shuffling让我想到了RWKV中的time mixing,虽然它们不是一个东西。
ST-Adam 优化器
经过VisualMixer处理的图像,其梯度在训练过程中会产生剧烈波动,即梯度震荡 (gradient oscillation) 。这使得像Adam这样的标准优化器难以收敛,或者容易陷入局部最优解 。
| 步骤 | ST-Adam | Adam |
|---|---|---|
| 1. 梯度计算 | $$g _ {t}=\nabla f(w _ {t})$$ | $$g _ {t}=\nabla f(w _ {t})$$ |
| 2. 动量更新 | $$m _ {t}=\beta m _ {t-1}+(1-\beta)g _ {t}$$ | $$m _ {t}=\beta m _ {t-1}+(1-\beta)g _ {t}$$ |
| 3. 二阶矩更新 | $$v _ {t}= \gamma v _ {t-1}+(1-\gamma)g _ {t}^{2}$$ | $$v _ {t}= \gamma v _ {t-1}+(1-\gamma)g _ {t}^{2}$$ |
| 4. 偏差校正 | 无此步骤 | $$\hat{m} _ {t}=\frac{m _ {t}}{1-\beta^{t}}$$ $$\hat{v} _ {t}=\frac{v _ {t}}{1-\gamma^{t}}$$ |
| 5. 参数更新 | $$w _ {t+1}=w _ {t}-\eta \frac{m _ {t}}{\sqrt{v _ {t}}+\epsilon}$$ | $$w _ {t+1}=w _ {t}-\eta \frac{\hat{m} _ {t}}{\sqrt{\hat{v} _ {t}}+\epsilon}$$ |
作者认为:在 VisualMixer的场景中,由于混合操作,梯度更有可能在有限的范围内剧烈变化。也就是说,灵活的更新步长对我们的模型训练过程来说更像是一种毒药而非益处。尽管自适应更新步长可以让模型更快地收敛,但它也使得模型更有可能陷入局部极小。因此,保持更新步长稳定是更好的选择,能避免模型陷入局部极小。