V-JEPA 2
在23年,本Blog已经介绍过JEPA,也就是lecun推出的世界模型结构。
Lecun一直不相信当前的LLM,而布局于“世界模型”。
当时主要是对图片处理,也就是Image-JEPA。而V-JEPA代表是对视频(Video)处理。
不妨让我们回顾一下。
JEPA和I-JEPA
Joint-Embedding Predictive Architecture(JEPA)是一种架构,它从单个上下文块中学习预测图像中不同目标块的表示,并使用掩码策略来引导模型生成语义表示。
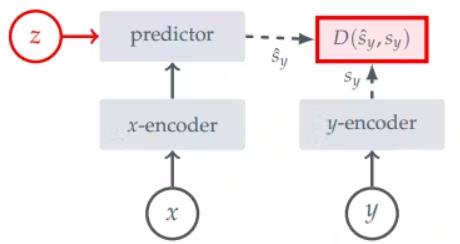
而I-JEPA的框架为:
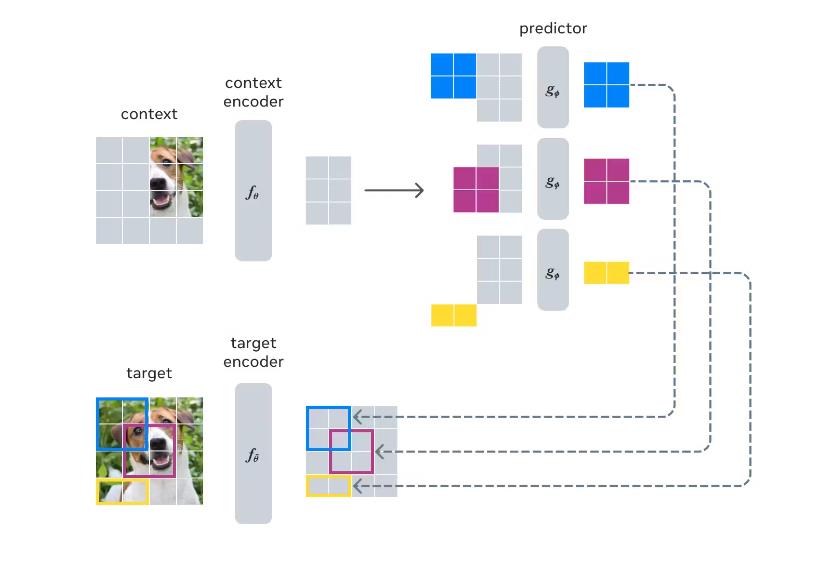
其中这一结构也有点类似对比学习。
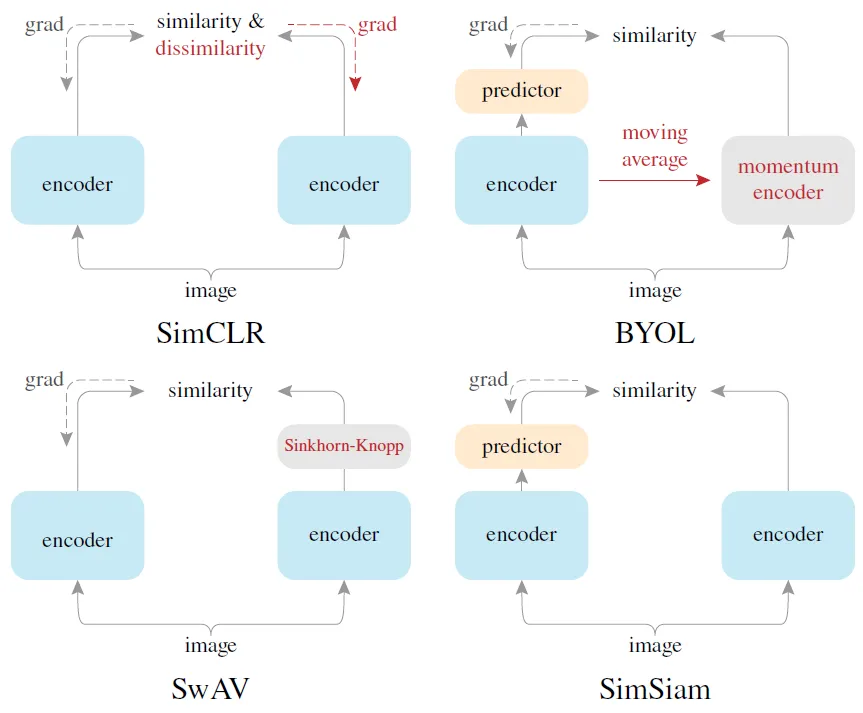
I-JEPA有点像Simsiam,而后续介绍的V-JEPA有点像BYOL。
题外话:
有人指出BYOL起作用是因为其中的batch norm,BYOL作者写了一篇《BYOL works even without batch statistics》做了一些实验证明了BN并不是必要的。BN只是保证模型稳定的技巧,一个合适的初始化才是更重要的。
V-JEPA 2
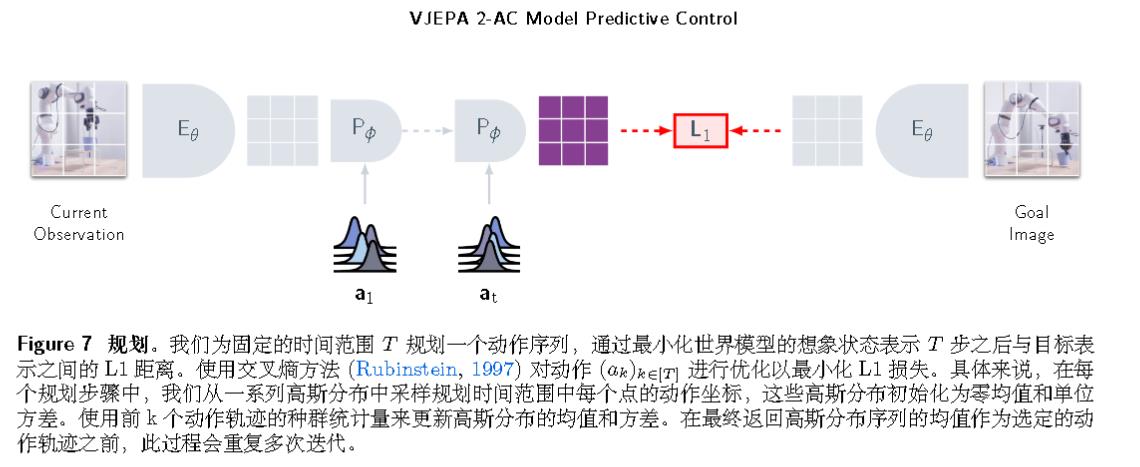
基本概述如下图所示。V-JEPA 2 采用分阶段训练流程,首先在互联网规模的视频上进行无动作的预训练,随后利用少量交互数据进行后训练。在第一阶段,采用掩码降噪特征预测目标 ,模型在学成的表示空间中预测视频的掩码片段。使用多达 10 亿参数和超过 100 万小时的视频来训练 V-JEPA 2 编码器。
在互联网规模的视频上进行预训练后,利用第一阶段学成的表示,在少量交互数据上训练了一个动作条件的世界模型 V-JEPA 2-AC。动作条件世界模型是一个拥有 3 亿参数的 Transformer 网络,采用了块因果注意力机制,能够自回归地预测在给定动作和先前状态下的下一帧视频的表示。该模型在给定子目标的情况下,仅使用来自 Droid 数据集 的 62 小时未标记交互数据,可用于规划 Franka 机械臂的动作,并在新环境中通过单目 RGB 摄像头 zero-shot 执行抓取操作任务。
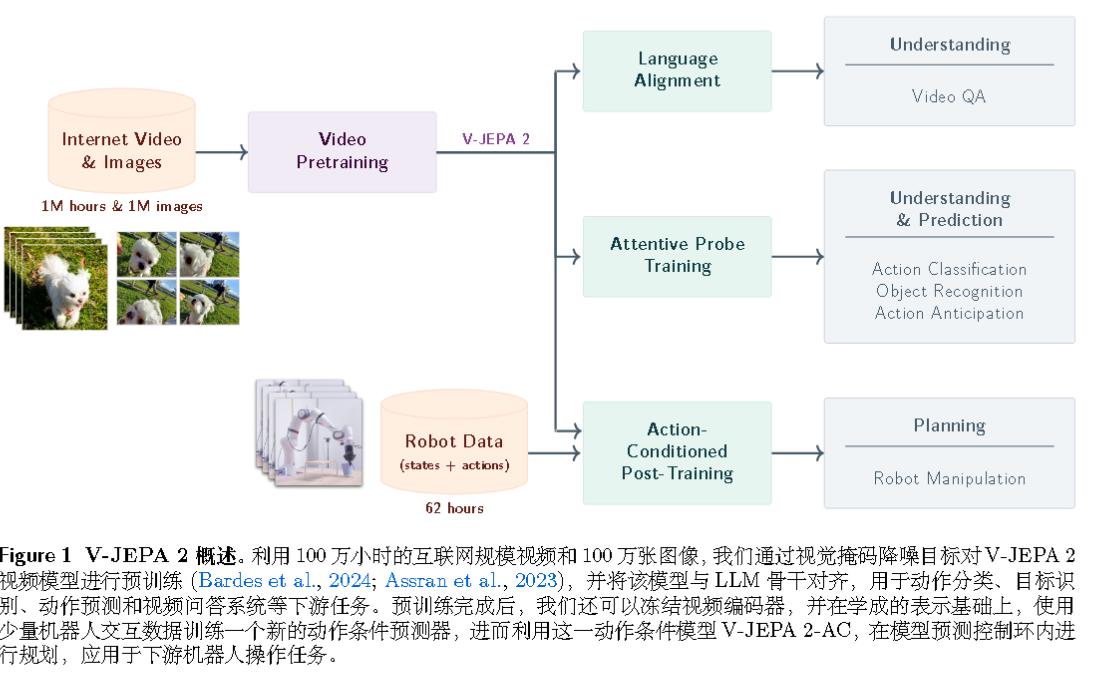
算法架构如下图所示:
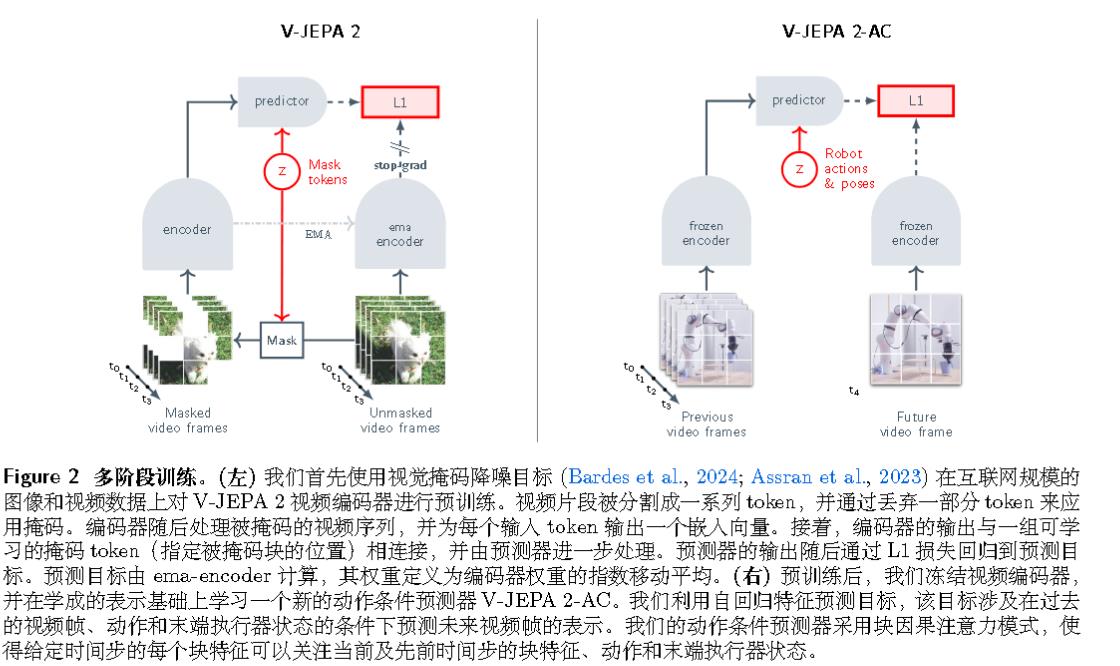
左图有点像BYOL,会有EMA和stop grad。
V-JEPA 2-AC会涉及以下损失:
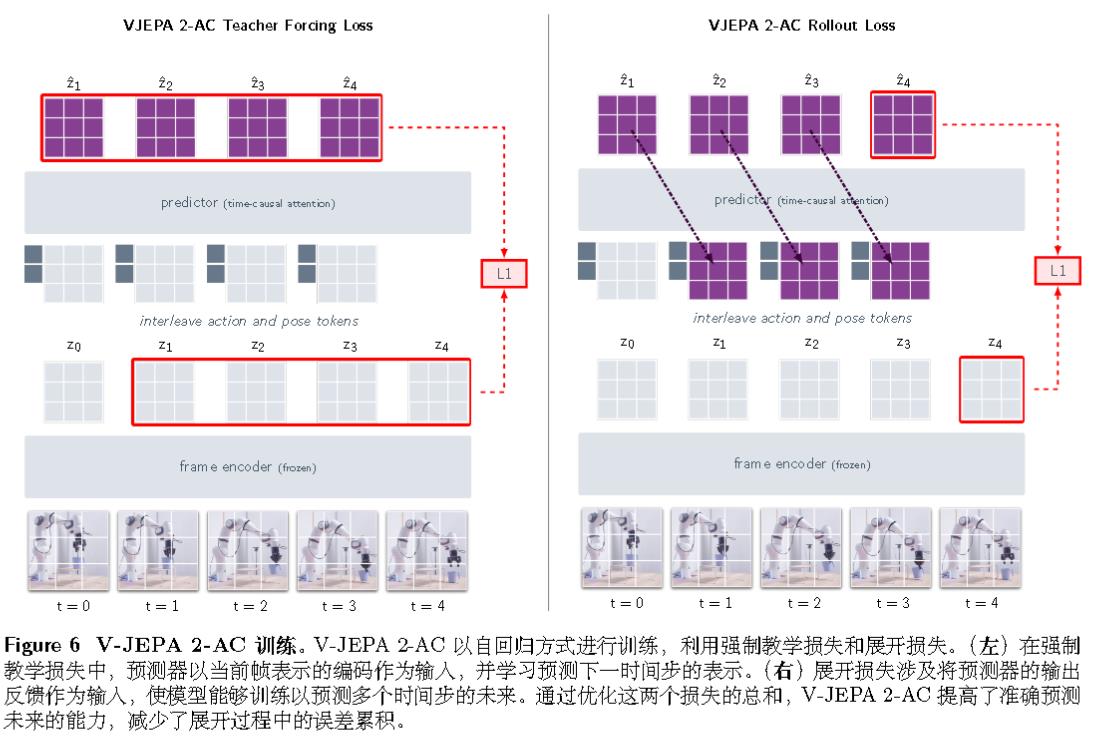
对于接下来的机械臂动作规划,算法会最小化目标条件的能量函数来规划固定时间范围内的动作序列。然后执行第一个动作,观察新状态,并重复该过程。