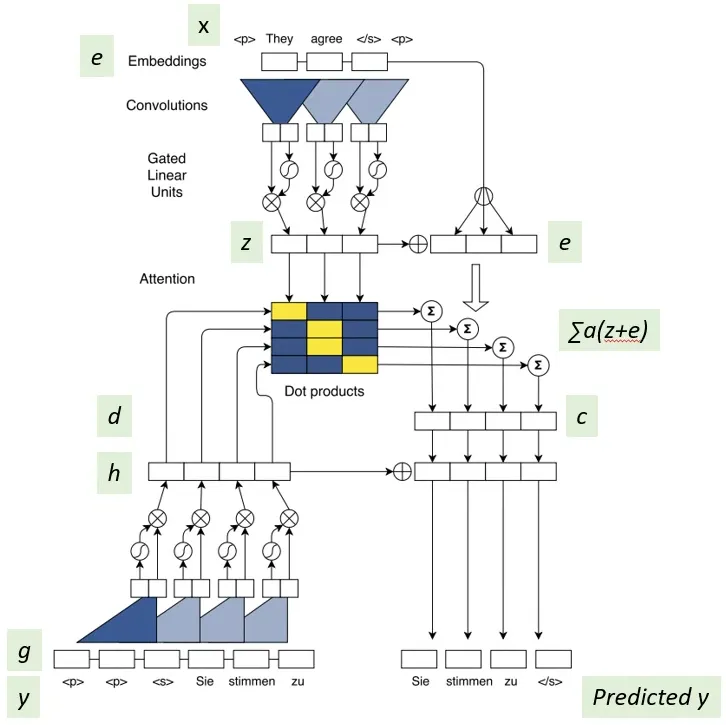
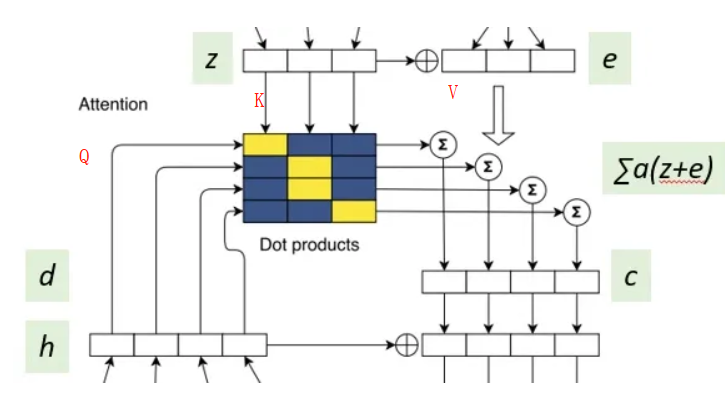
classAttentionLayer(nn.Module): def__init__(self, conv_channels, embed_dim, bmm=None): super().__init__() # projects from output of convolution to embedding dimension self.in_projection = Linear(conv_channels, embed_dim) # projects from embedding dimension to convolution size self.out_projection = Linear(embed_dim, conv_channels)
self.bmm = bmm if bmm isnotNoneelse torch.bmm
defforward(self, x, target_embedding, encoder_out, encoder_padding_mask): residual = x
# attention x = (self.in_projection(x) + target_embedding) * math.sqrt(0.5) x = self.bmm(x, encoder_out[0])
# don't attend over padding if encoder_padding_mask isnotNone: x = ( x.float() .masked_fill(encoder_padding_mask.unsqueeze(1), float("-inf")) .type_as(x) ) # FP16 support: cast to float and back
# softmax over last dim sz = x.size() x = F.softmax(x.view(sz[0] * sz[1], sz[2]), dim=1) x = x.view(sz) attn_scores = x
x = self.bmm(x, encoder_out[1])
# scale attention output (respecting potentially different lengths) s = encoder_out[1].size(1) if encoder_padding_mask isNone: x = x * (s * math.sqrt(1.0 / s)) else: s = s - encoder_padding_mask.type_as(x).sum( dim=1, keepdim=True ) # exclude padding s = s.unsqueeze(-1) x = x * (s * s.rsqrt())
# project back x = (self.out_projection(x) + residual) * math.sqrt(0.5) return x, attn_scores
defmake_generation_fast_(self, beamable_mm_beam_size=None, **kwargs): """Replace torch.bmm with BeamableMM.""" if beamable_mm_beam_size isnotNone: delself.bmm self.add_module("bmm", BeamableMM(beamable_mm_beam_size))