Child Mind Institute(下称CMI)之前在 Kaggle 上举办了两场竞赛,一场与检测睡眠状态有关,另一场与检测有问题的互联网使用有关。加上这个月开始举办的关于检测强迫性重复行为的比赛总计3场。
比赛数据介绍
数据量986.46MB
该数据集包含大约500个手腕佩戴的加速度计数据的多日记录,这些记录被注释为两种事件类型:睡眠开始,和睡眠结束。任务是检测加速度计序列中这两种事件的发生。
对于这些数据,有以下几条具体的指导方针:
- 一个睡眠周期必须至少持续30分钟。
- 一个睡眠期可能会被不超过30分钟的活动中断。
- 除非手表被认为在整段时间内佩戴着,否则无法检测到不睡觉的时间窗口。
- 夜晚中最长的睡眠窗口是唯一被记录的。
- 如果无法识别有效的睡眠窗口,则不会记录该夜的入睡或唤醒事件。
- 睡眠事件不需要跨越日界线,因此没有硬性规定定义在给定时间内可能发生的次数。然而,每晚不应分配超过一个窗口。例如,同一天内,一个人有01:00-06:00和19:00-23:30的睡眠窗口是有效的,尽管分配在连续的夜晚。
- 记录的夜晚数大致等于该系列中的24小时周期数。
评估指标
评估指标是mean average precision(mAP)
第一名@sakami
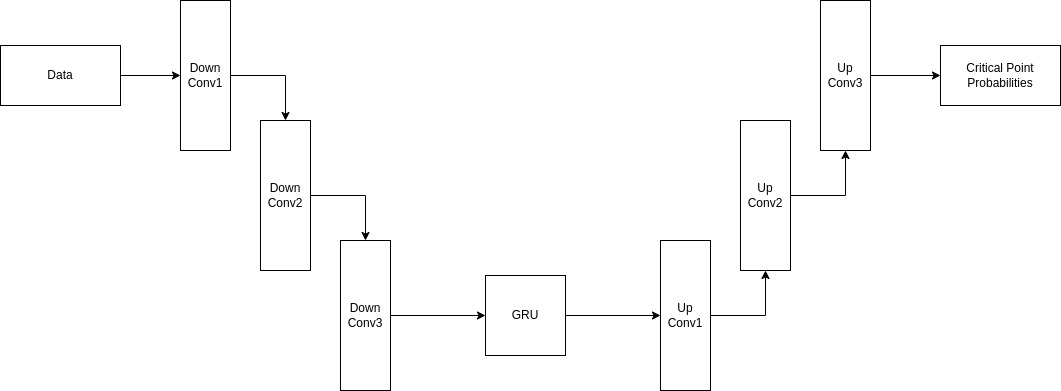
在输入缩放方面,使用了 SEModule。(https://arxiv.org/abs/1709.01507)
1
2
3
4
5
6
7
8
9
10
11
| class SEScale(nn.Module):
def __init__(self, ch: int, r: int) -> None:
super().__init__()
self.fc1 = nn.Linear(ch, r)
self.fc2 = nn.Linear(r, ch)
def forward(self, x: torch.FloatTensor) -> torch.FloatTensor:
h = self.fc1(x)
h = F.relu(h)
h = self.fc2(h).sigmoid()
return h * x
|
当真实事件发生时,分钟存在偏差。为解决这个问题,在最终层中,与分钟相关的特征被分别连接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def forward(self, num_x: torch.FloatTensor, cat_x: torch.LongTensor) -> torch.FloatTensor:
cat_embeddings = [embedding(cat_x[:, :, i]) for i, embedding in enumerate(self.category_embeddings)]
num_x = self.numerical_linear(num_x)
x = torch.cat([num_x] + cat_embeddings, dim=2)
x = self.input_linear(x)
x = self.conv(x.transpose(-1, -2)).transpose(-1, -2)
for gru in self.gru_layers:
x, _ = gru(x)
x = self.dconv(x.transpose(-1, -2)).transpose(-1, -2)
minute_embedding = self.minute_embedding(cat_x[:, :, 0])
x = self.output_linear(torch.cat([x, minute_embedding], dim=2))
return x
|
数据准备
每系列数据被分为每日的数据块,间隔为 0.35 天。在训练过程中,每个数据块的一半在每个 epoch 中使用。
目标值处理
基于与真实事件距离创建衰减目标,距离越大,值越小。
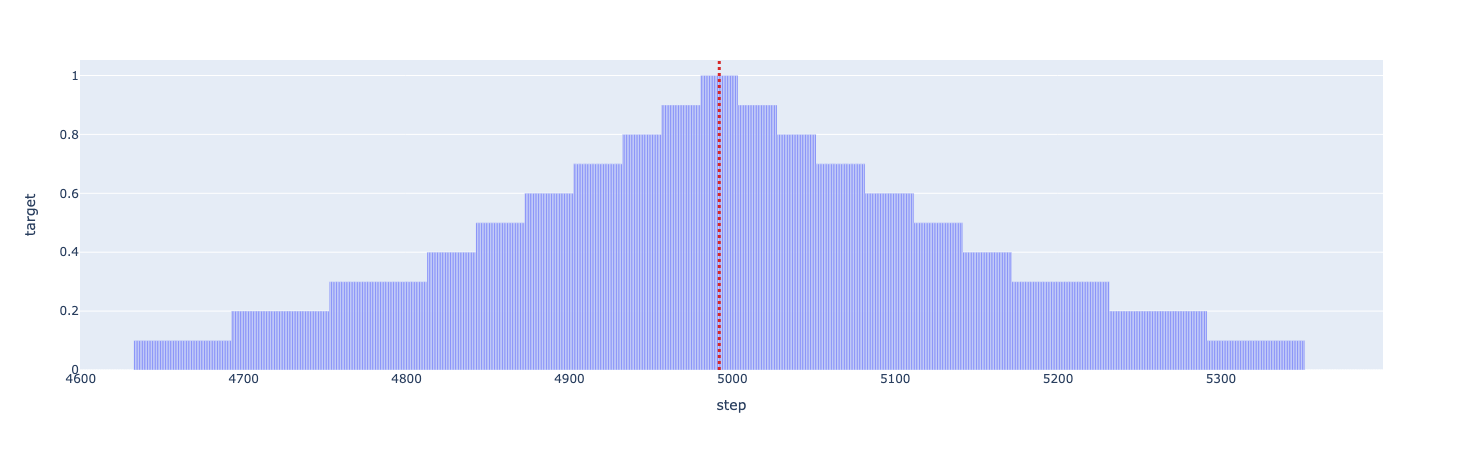
目标在每个 epoch 中都会更新以进一步衰减。
1
2
|
targets = np.where(targets == 1.0, 1.0, (targets - (1.0 / config.n_epochs)).clip(min=0.0))
|
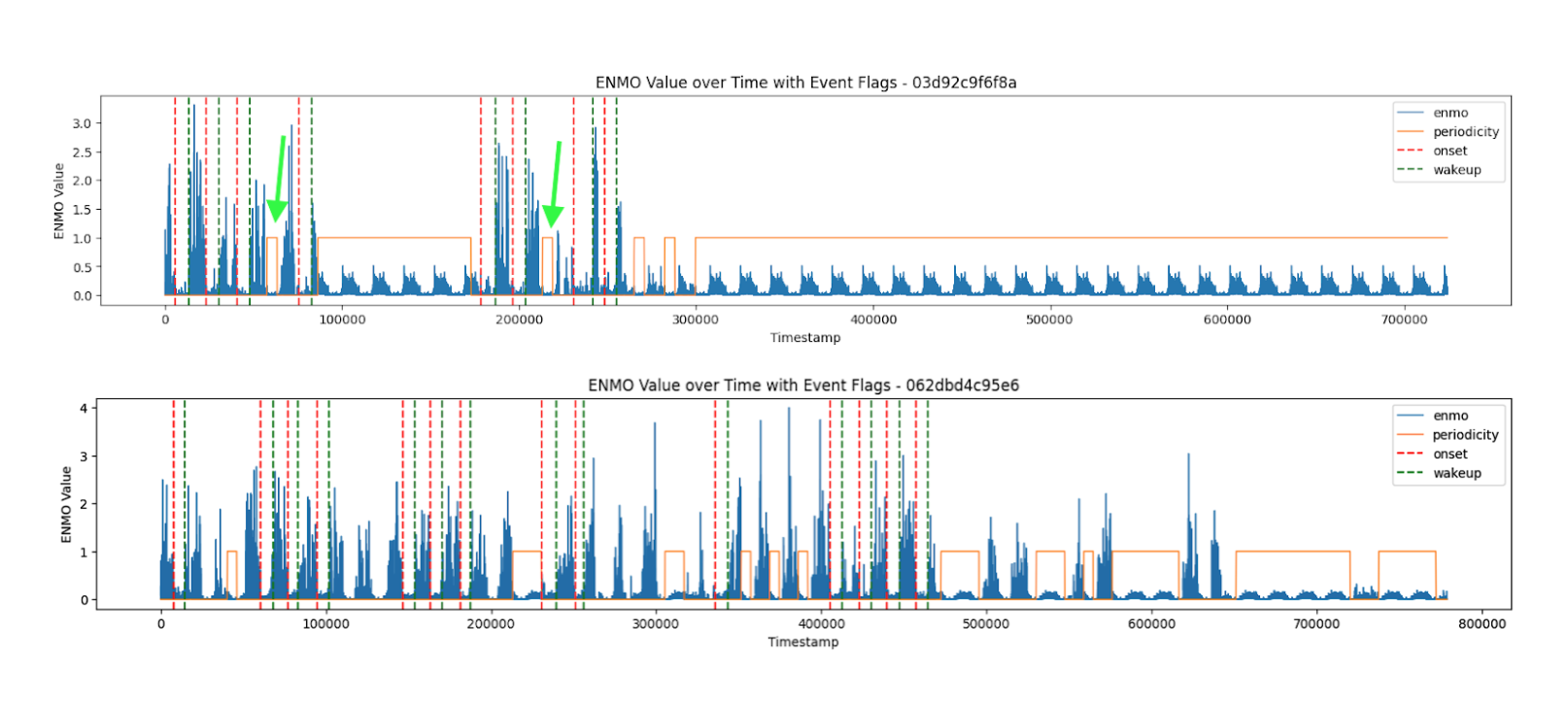
周期性滤波器
当测量设备被移除时,数据中存在日周期性。这被用来基于规则预测这些周期,并用作输入和预测的过滤器。
后处理
1.数据特点
目标事件的第二个值总是设置为 0。
2.创建第二级模型
第一级模型的预测被训练为识别与真实值在特定范围内的事件为正。
第二级模型将这些转化为每分钟真实值事件存在的概率。
第二级模型首先以每分钟为单位对第一级模型的预测进行平均,然后使用高度为 0.001、距离为 8 的 find_peaks 检测这些平均值中的峰值。
- 根据检测到的峰值,从原始时间序列中创建数据块,每个峰值前后各捕获 8 分钟。
- 其中的
step_size至关重要,因为正负样本的比例取决于包含的步数,这会影响后续阶段的准确性。因此调整了步数以获得最佳性能。
- 如果数据块是连接的,它们被视为一个数据块。
对于每个数据块,汇总了第 1 个模型的预测结果以及其他特征,如 anglez 和 enmo。这些汇总特征随后用于训练 LightGBM 和 CatBoost 等模型。
将每个数据块视为一个序列来训练 CNN-RNN、CNN 和 Transformer 模型。
第二名@K_MAT
第一阶段:事件检测与睡眠/清醒分类
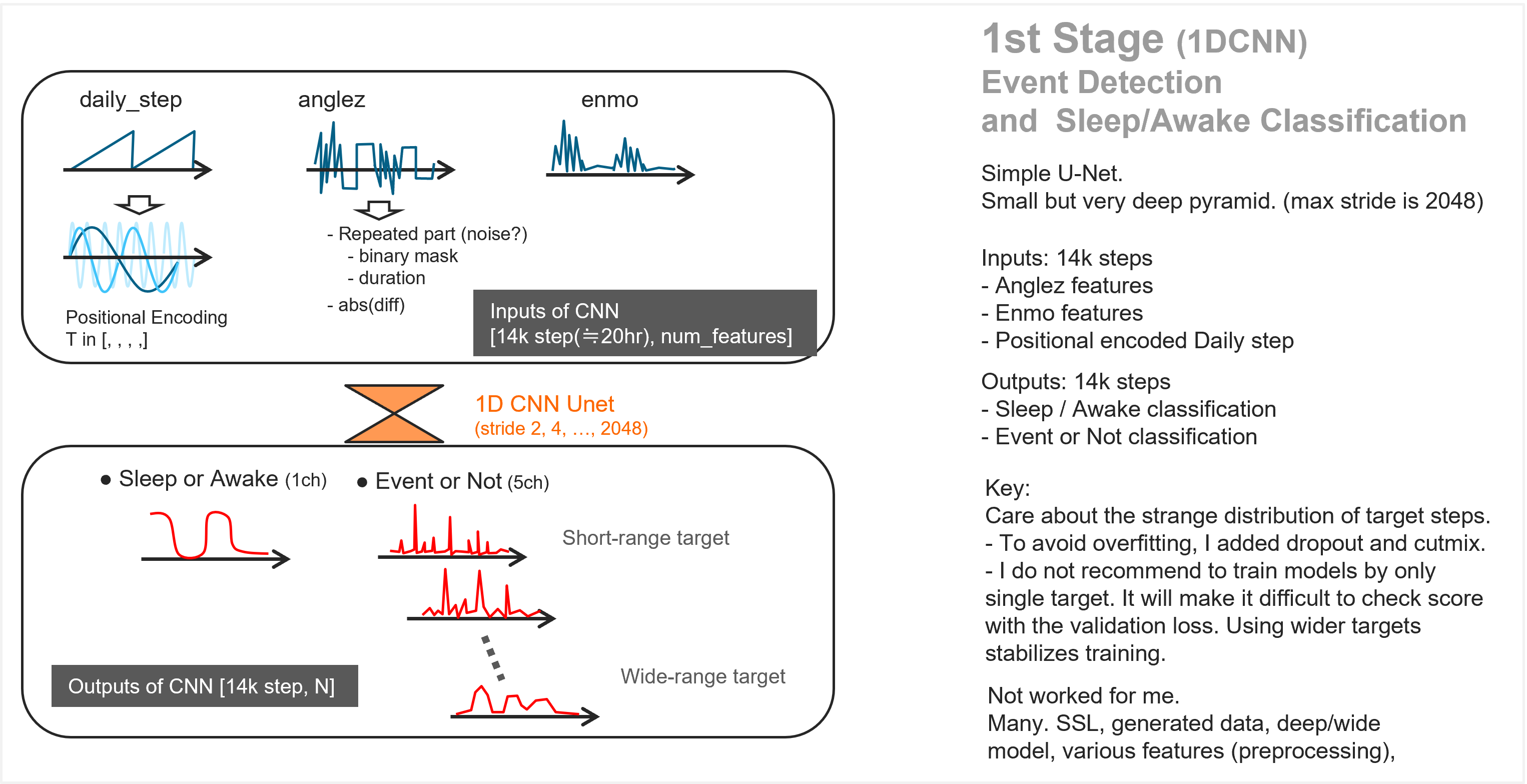
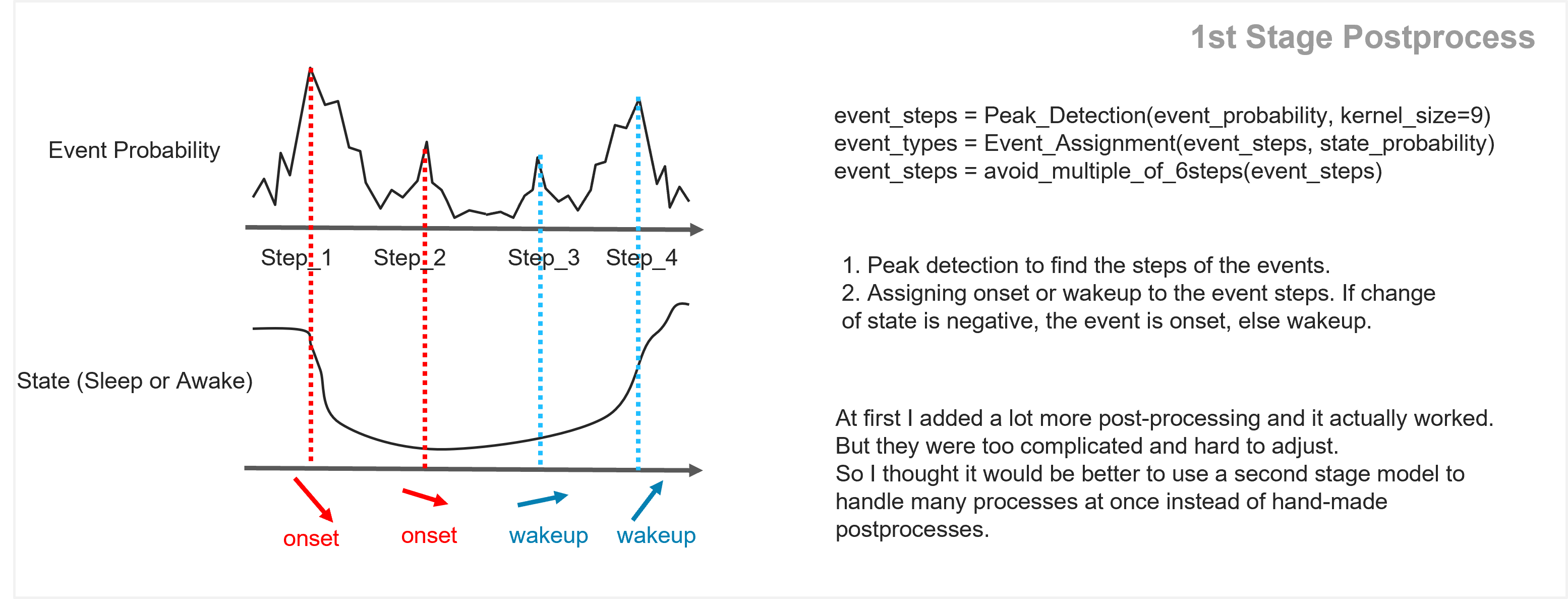
第二阶段:考虑每天最多 2 次事件的限制,重新评估置信度
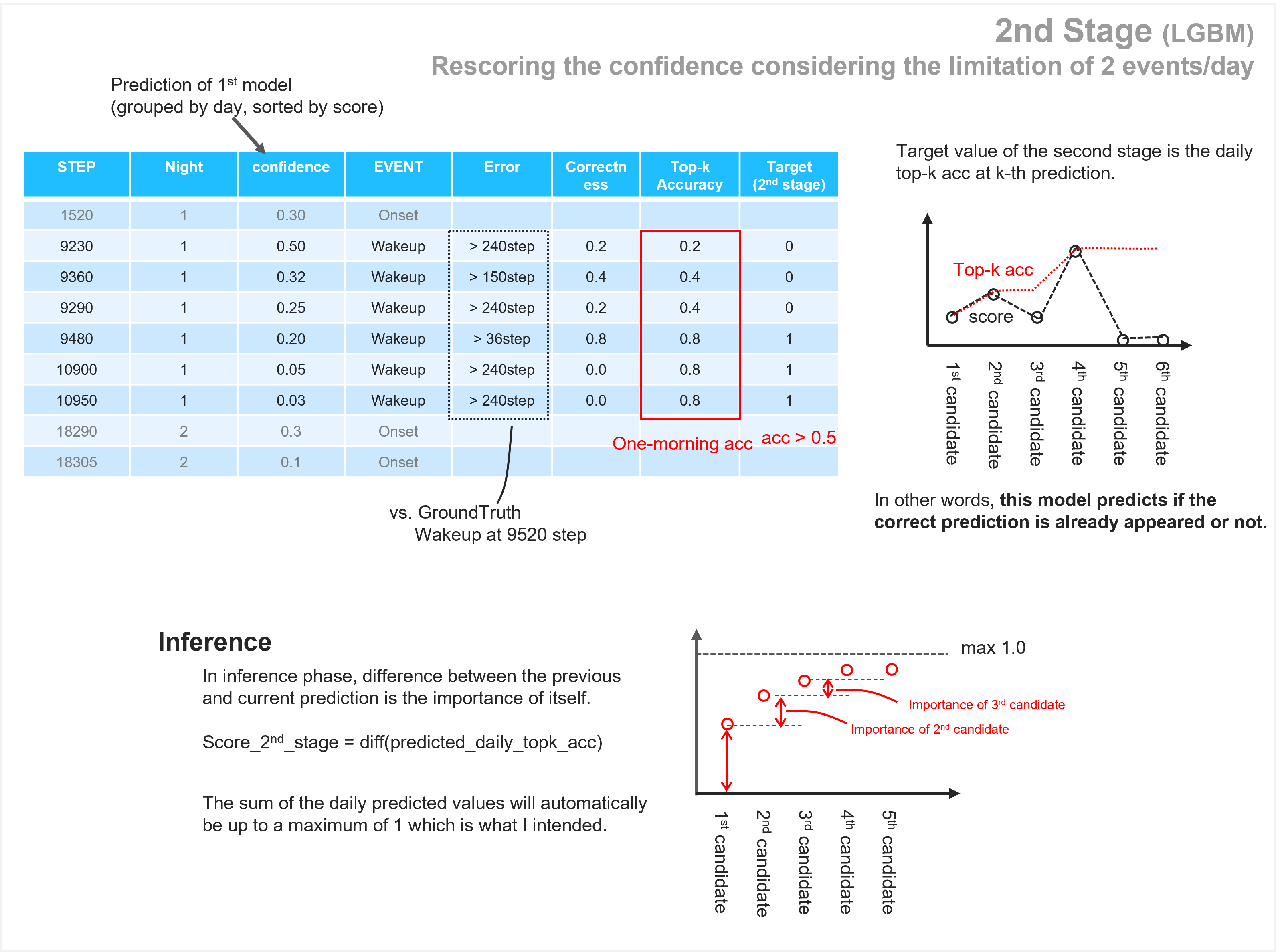
第三阶段:尽可能添加更多事件
- 准备 2 个 CNN 模型
- 每个模型在第一阶段对 10(5 折 x2 种子)的预测进行平均
- 对每个模型运行第二阶段
- 2 个模型的 Weighted Boxes Fusion(WBF)式集成
WBF出自《Weighted boxes fusion: Ensembling boxes from different object detection models》。
在这里,具体而言:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
| import pandas as pd
import numpy as np
def weighted_fusion_ensemble(df_0: pd.DataFrame,
df_1: pd.DataFrame,
distance_threshold: int = 12,
model_weights: list = [0.5, 0.5]) -> pd.DataFrame:
"""
对来自两个模型 (df_0, df_1) 的预测结果(包含 'step' 和 'score')进行加权融合。
融合是按 'series_id' 分组进行的。
参数:
df_0 (pd.DataFrame): 第一个模型的预测结果 DataFrame,
必须包含 'series_id', 'step', 'score' 列。
df_1 (pd.DataFrame): 第二个模型的预测结果 DataFrame,
必须包含 'series_id', 'step', 'score' 列。
distance_threshold (int): 'step' 值的距离阈值。如果来自 df_0 和 df_1 的两个 step
的绝对差小于此阈值,则认为它们匹配。
model_weights (list): 包含两个浮点数的列表,分别代表 df_0 和 df_1 的基础权重。
这些权重会被归一化。
返回:
pd.DataFrame: 包含融合后预测结果的 DataFrame。
"""
normalized_model_weights = [model_weights[0] / sum(model_weights),
model_weights[1] / sum(model_weights)]
large_val = 1e8
series_ids = df_0['series_id'].unique()
out_df_list = []
for series_id in series_ids:
df_0_id = df_0[df_0['series_id'] == series_id].copy()
df_1_id = df_1[df_1['series_id'] == series_id].copy()
df_0_id = df_0_id.sort_values("score", ascending=False).reset_index(drop=True)
df_1_id = df_1_id.sort_values("score", ascending=False).reset_index(drop=True)
steps_0 = df_0_id['step'].values.copy()
scores_0 = df_0_id['score'].values.copy()
steps_1 = df_1_id['step'].values.copy()
scores_1 = df_1_id['score'].values.copy()
not_assigned_predictions_from_df1 = []
for i in range(len(steps_1)):
step_1_current = steps_1[i]
score_1_current = scores_1[i]
dists = np.abs(steps_0 - step_1_current)
argmin_dist = np.argmin(dists)
min_dist_val = dists[argmin_dist]
if min_dist_val < distance_threshold:
matched_step_0 = steps_0[argmin_dist]
matched_score_0 = scores_0[argmin_dist]
weight_for_avg_0 = normalized_model_weights[0] * matched_score_0
weight_for_avg_1 = normalized_model_weights[1] * score_1_current
denominator = weight_for_avg_0 + weight_for_avg_1
if denominator == 0:
new_score = (matched_score_0 + score_1_current) / 2
new_step = (matched_step_0 + step_1_current) / 2
else:
new_score = (matched_score_0 * weight_for_avg_0 + score_1_current * weight_for_avg_1) / denominator
new_step = (matched_step_0 * weight_for_avg_0 + step_1_current * weight_for_avg_1) / denominator
df_0_id.loc[argmin_dist, "score"] = new_score
df_0_id.loc[argmin_dist, "step"] = new_step
steps_0[argmin_dist] = large_val
scores_0[argmin_dist] = new_score
else:
unmatched_pred_df1 = df_1_id.iloc[[i]].copy()
unmatched_pred_df1['score'] = score_1_current * normalized_model_weights[1]
not_assigned_predictions_from_df1.append(unmatched_pred_df1)
df_0_id.loc[steps_0 != large_val, "score"] *= normalized_model_weights[0]
out_df_list.append(df_0_id)
if len(not_assigned_predictions_from_df1) > 0:
concatenated_not_assigned = pd.concat(not_assigned_predictions_from_df1)
out_df_list.append(concatenated_not_assigned)
final_out_df = pd.concat(out_df_list).reset_index(drop=True)
return final_out_df
|
优先将两个模型中“相似”(step距离近)的预测进行智能融合,融合后的结果会赋予更高的权重(通过原始分数的参与)。
对于未能找到匹配项的预测,则保留它们,但其分数会根据其来源模型的权重进行调整。
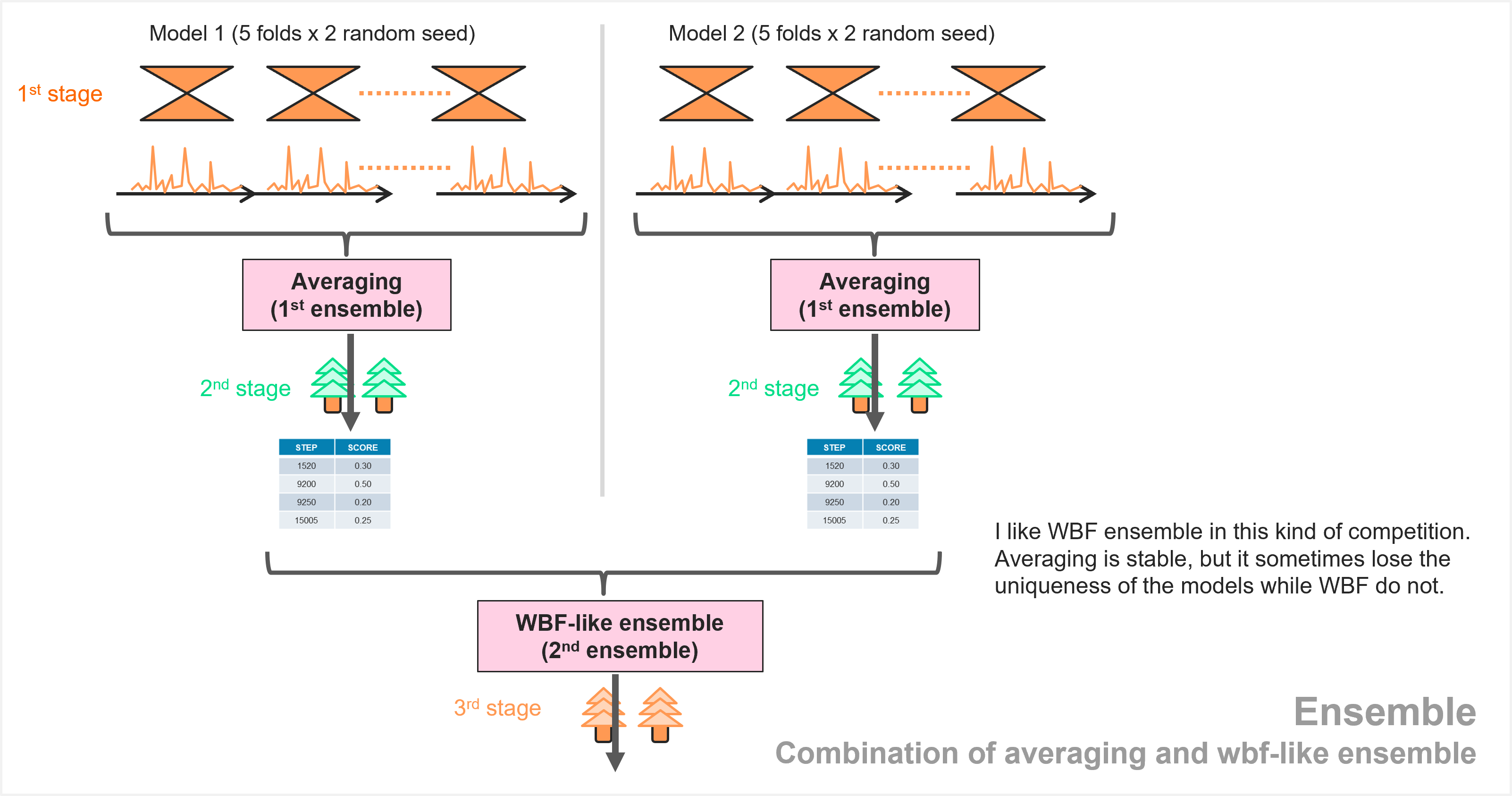
第三名@FNOA
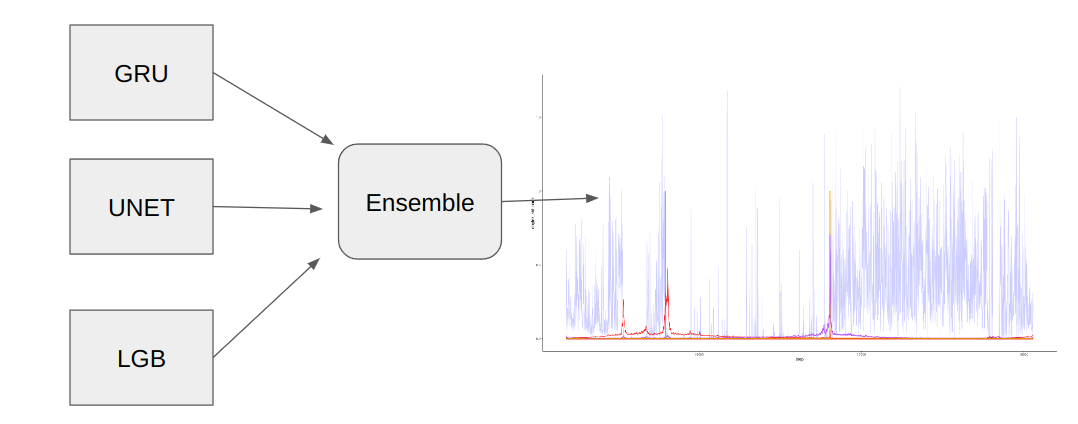
预处理
对于最终提交,GRU + UNET 模型仅使用 7 个特征。
数据集构建
将序列分为一天一段的序列,并将粒度从 5 秒降低到 30 秒。
因此得到了长度为 2880 的序列,其中通常包含一个睡眠开始和一个醒来。
噪声处理也重要
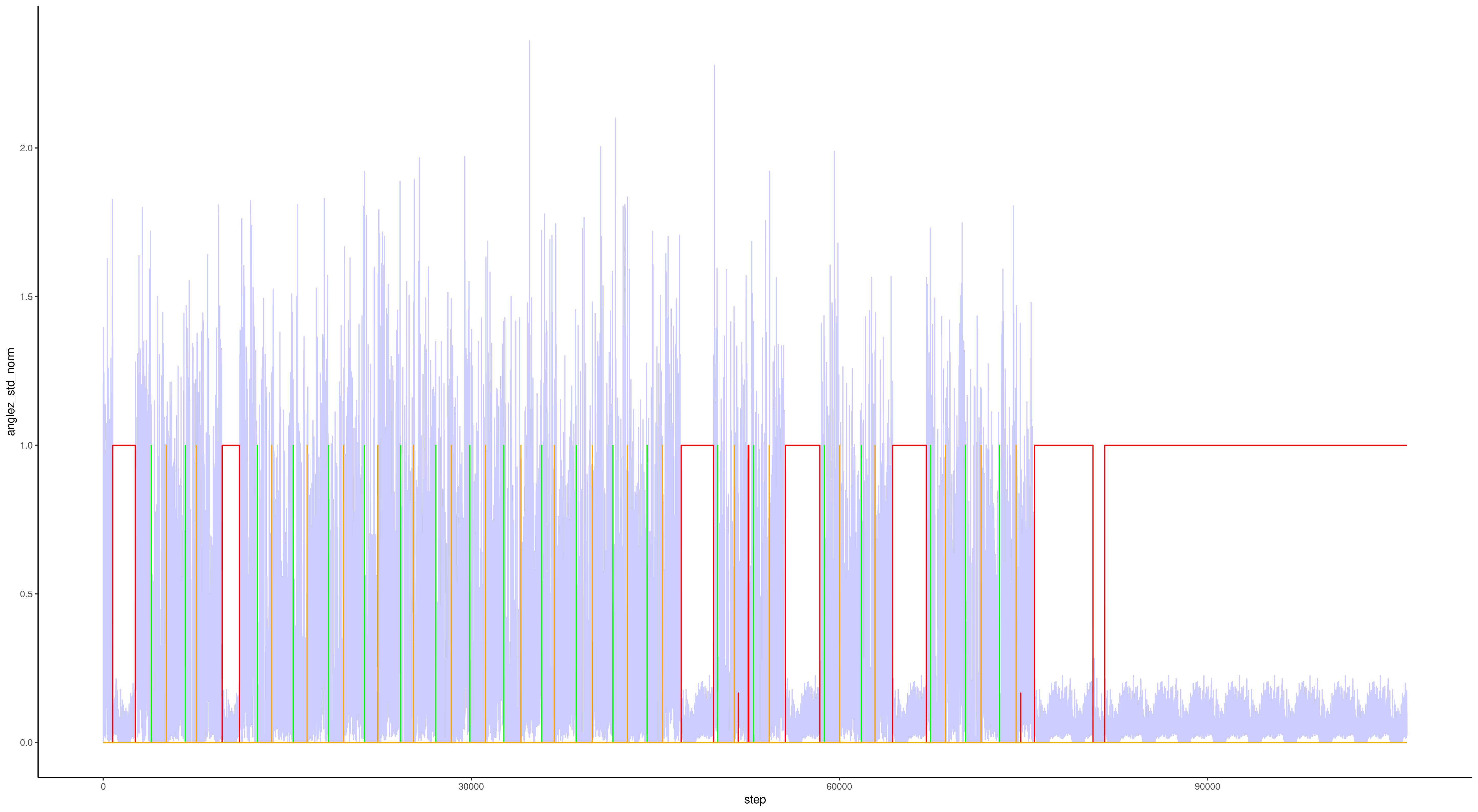
当在相同的小时、分钟和秒内,同一系列中重复出现完全相同的值时,这基本上就是噪声。红线是检测到的噪声。
问题性互联网使用
shakeup的比赛
比赛数据介绍
6.73GB
Demographics - 参与者的年龄和性别信息。Internet Use - 每天使用电脑/互联网的小时数。Children's Global Assessment Scale - 心理健康临床医生用于评估 18 岁以下青少年一般功能的数值量表。Physical Measures - 血压、心率、身高、体重和腰围、臀围的测量数据集合。FitnessGram Vitals and Treadmill - 使用 NHANES 跑步机协议评估的心血管健康测量。FitnessGram Child - 健康相关的体能评估,测量五个不同参数,包括有氧能力、肌肉力量、肌肉耐力、柔韧性和身体成分。Bio-electric Impedance Analysis - 关键身体成分指标的测量,包括 BMI、脂肪、肌肉和水分含量。Physical Activity Questionnaire - 关于儿童在过去 7 天内参与剧烈活动的情况。Sleep Disturbance Scale - 用于对儿童睡眠障碍进行分类的量表。Actigraphy - 通过研究级生物追踪器对生态物理活动进行客观测量。Parent-Child Internet Addiction Test - 20 项量表,用于测量与强迫性互联网使用相关的特征和行为,包括强迫性、逃避性和依赖性。
目标 sii : 0 对应 None , 1 对应 Mild , 2 对应 Moderate , 3 对应 Severe 。
评估指标
基于二次加权 kappa 系数
第一名@LENNART HAUPTS
模型为投票集成,包括:
- LGBMRegressor
- 两个 XGBoost 回归器
- CatBoostRegressor
- ExtraTreesRegressor
数据清洗、特征工程和插补
数据清洗:
- 移除了不合理的值,例如超过 60%的身体脂肪百分比或负的骨矿物质含量,并用 NaN 替换。
特征工程:
- 创建了多种描述性的活动追踪器特征,并为白天和夜晚设置了不同的掩码。
- 使用 PCA 对活动追踪器数据进行降维保留了 15 个成分。
- 额外包含的特征基于年龄组均值进行归一化的值,以及其他看似合理的特征,如每日能量消耗与基础代谢率之间的差异。
- 对大部分特征应用了分位数分箱来处理噪声,效果出奇地好。
插补:
- Lasso 用于特征插补,由于维度较高且存在噪声。
- 使用 Lasso 进行特征插补。对于每个目标列,使用缺失值少于 40%的特征训练模型,并基于训练好的模型插补这些特征中的缺失值。如果找不到可用于插补的有效特征(即缺失值少于 40%的特征),或者有效样本数量过少,解决方案则默认采用均值插补。
参数调优和特征选择
在比赛早期,很明显常规的参数调优与交叉验证设置会导致结果不稳定。
为解决这一问题:
- 在参数调优过程中采用了重复分层 K 折交叉验证。重复次数为 10 到 20 次。计算成本更高,但得到了更稳健的结果。
- 基于特征重要性手动进行特征选择,将数据集减少到 39 个特征
第三名@JOBAYER HOSSAIN
交叉验证
主要关注点之一是建立一个稳定可靠的 CV 框架。
在整个过程中,避免使用任何固定的随机种子。进行了 100 次 5 折分层 KFold 重复实验获得稳定的结果,而在 Optuna 超参数调优时使用了 20 次重复。
为了优化最终的 QWK 阈值,使用了所有这些重复实验的 OOF 预测。
模型
LightGBM
特征工程
- 活动记录数据:
- 计算了 X、Y、Z 和 AngleZ 的标准差,以及 Elmo 的平均值。
- 使用 Elmo 表示的五组最长的非活跃和活跃连续时间特征。
- 将”light”列按从黄昏到直射阳光的范围分类,并统计每个类别的值计数。
- 仪器数据:
- 从公共笔记本开始,检查每个特征是否真的对模型有贡献。之后,根据实验添加了一些自定义特征。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def feature_engineering(df):
for col, (col_min, col_max) in min_max_dict.items():
df[col] = df[col].clip(lower=col_min, upper=col_max)
bins = [0, 6, 12, 18, 100]
labels = ['1 to 6', '7 to 12', '13 to 18', '19 to 100']
df['Age_Binned'] = pd.cut(df['Basic_Demos-Age'], bins=bins, labels=labels, right=True)
df['Age_Sex'] = df['Age_Binned'].astype(str) + '_' + df['Basic_Demos-Sex'].astype(str)
df['BFP_BMI'] = df['BIA-BIA_Fat'] / df['BIA-BIA_BMI']
df['BFP_BMR'] = df['BIA-BIA_Fat'] * df['BIA-BIA_BMR']
df['BMR_Weight'] = df['BIA-BIA_BMR'] / df['Physical-Weight']
df['Muscle_to_Fat'] = df['BIA-BIA_SMM'] / df['BIA-BIA_FMI']
df['Hydration_Status'] = df['BIA-BIA_TBW'] / df['Physical-Weight']
df['PreInt_FGC_CU_PU'] = df['PreInt_EduHx-computerinternet_hoursday'] * df['FGC-FGC_CU'] * df['FGC-FGC_PU']
df['FGC_GSND_GSD_Age'] = df['FGC-FGC_GSND'] * df['FGC-FGC_GSD'] * df['Basic_Demos-Age']
df['SDS_Activity'] = df['BIA-BIA_Activity_Level_num'] * df['SDS-SDS_Total_T']
df['CGasync_Score_Normalized'] = df['CGAS-CGAS_Score'] - df.groupby('Basic_Demos-Enroll_Season')['CGAS-CGAS_Score'].transform('mean')
df['Internet_Physical_Difference'] = df['PreInt_EduHx-computerinternet_hoursday'] - df['PAQ_A-PAQ_A_Total']
df[df.select_dtypes(include='object').columns] = df.select_dtypes(include='object').astype('category')
return df
|
数据增强
后处理
使用’PCIAT-PCIAT_Total’这一列进行训练。应用了优化后的阈值来计算每个 100*5 模型的 sii,并取众数来生成最终预测。