Graph Neural Networks with Learnable Structural and Positional Representations
该论文在拉普拉斯PE的基础上,新的可学习节点位置编码(PE),用于图嵌入。
(ICLR 2022)
为什么要使用位置编码
比如单靠信息传播,下图的结构并不能很好学习:
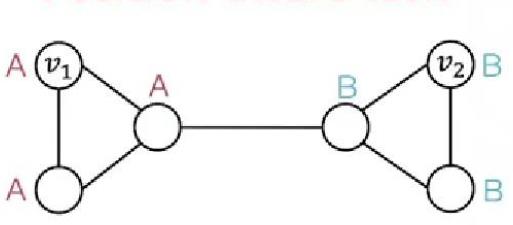
解决方案:
- 堆叠多层
由于过度压缩现象,它可能对远距离节点是不够的。
- 应用高阶
K 阶 WL-GNN 在扩展中比 MP-GNN 计算上更昂贵,即使对于中等规模的图也是如此。
- 考虑节点的位置编码(PE)(以及边的位置编码)
比如像graphormer(第一个Graph transfomrer),采用了三种位置编码:
(1)Centrality Encoding
即
1 | |
(2)Spatial Encoding
给定一个合理的距离度量 ϕ(v_i, v_j), 根据两个节点(v_i, v_j)之间的距离,为其分配相应的编码向量。距离度量 ϕ(⋅) 的选择多种多样,对于一般性的图数据可以选择无权或带权的最短路径,而对于特别的图数据则可以有针对性的选择距离度量,例如物流节点之间的最大流量,化学分子 3D 结构中原子之间的欧氏距离等等。
为了不失一般性,Graphormer 在实验中采取了无权的最短路径作为空间编码的距离度量。
(3)Edge Encoding
在计算两个节点之间的相关性时,作者对这两个节点最短路径上的连边特征进行加权求和作为注意力偏置,其中权重是可学习的。
另外简单的还有比如Laplacian Eigenvectors as PE,但由于拉普拉斯矩阵的特征向量 v 和其相反向量 −v 都描述了相同的结构信息(因为它们对应同一个特征值)。当我们将这些特征向量用作节点的位置编码时,就会出现不唯一性。它可能会将这些实际上表示相同结构信息的编码视为完全不同的输入,从而影响学习效率和泛化能力。
代码分析
官方代码:https://github.com/vijaydwivedi75/gnn-lspe
写得有些混乱,我们不如直接看dgl的源码:https://www.dgl.ai/dgl_docs/_modules/dgl/transforms/functional.html#random_walk_pe
1 | |
1 | |