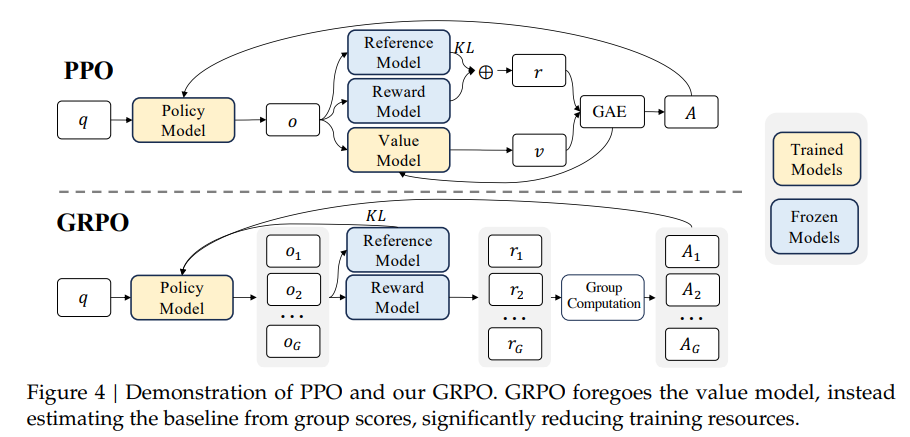
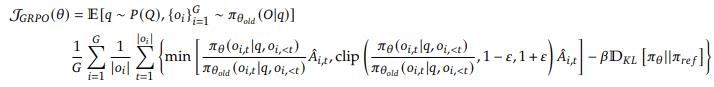Group Relative Policy Optimization(GRPO)起自deepseekmath,在deepseek-R1中也大放光彩。
看到复旦某组开源了一个简单的仅~200行的关于GRPO的项目simple_GRPO,故决定学习并写写。
GRPO是PPO的改进。
具体流程图:
流程看上去有点复杂,我们可以直接来看代码。
准备 源代码用100行代码实现了ref_server.py ,用了分布并行运行reference model。
1 system_prompt = """You are a helpful assistant. A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the user with the answer. ... """
奖励
1 2 3 4 5 6 7 8 def reward_correct (item, answer ):r'\d+\.\d+|\d+/\d+|\d+' if len (nums) == 0 : return -1.0 1 ]"A" ], extraction_config=[ExprExtractionConfig()])return 1 if verify(ans, ground_truth) else -1
如果回答符合指定格式,则奖励为 1.25,否则为 -1。
1 2 3 def reward_format (item, answer ):r"^<think>.*?</think><answer>.*?</answer>$" return 1.25 if re.match (pattern, answer, re.DOTALL | re.VERBOSE) else -1
loss 部分 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def GRPO_step (batch ):'plen' ]'inputs' ].to(engine.device)'rewards' ].to(engine.device)1 , :] 1 :] 1 :]'refs' ].to(per_token_logps.device)1 int ()1 , num_pre_Q).mean(dim=1 )1 , num_pre_Q).std(dim=1 )0 )0 )1e-4 )1 )sum (dim=1 ) / completion_mask.sum (dim=1 )).mean()return loss
无偏小方差KL 这里使用的并不是传统的KL,而是使用了一个无偏小方差KL,即$KL=rlogr-(r-1)$
传统的KL:一个好的估计量是无偏的(它有正确的均值)并且具有低方差。
一个无偏估计量k1 是$k1=log\frac{q(x)}{p(x)}=-log r$,但他有高方差,因为他对于因为它对于一半的样本是负的,而 KL 总是正的。
另一个低方差但存在偏差的估计量k2 是$k2=\frac{1}{2}(log\frac{q(x)}{p(x)})^2=\frac{1}{2}(logr)^2$。
它的期望可以从f-divergence 上考虑,其定义为凸函数f的$D_{f} ( p, q )=E_{x \sim q} [ f ( \frac{p ( x )} {q ( x )} ) ] $。
而
$E_{q} [ k_{2} ]=E_{q} [ \frac{1} {2} ( \operatorname{log} r )^{2} ]$,而$\frac{1}{2}(log(x))^2$和传统KL对应的$-log(x)$具有相同的$f’’(1)=1$。
另一个无偏但方差低的KL散度就是$rlogr-(r-1)$。为了降低方差,我们可以在k1的基础上再加入一个期望为0但与k1负相关的量,而$r-1$正是这个量。
另外,@ingambe在这里 尝试了把KL项去掉了,但也取得不错的效果。SimPO 也删去了reference model,且取得了比DPO更好的结果。既然GRPO在PPO的基础上去除掉了value model,那reference model也是必要的吗?我们可以完全去掉它吗?
优势函数 由于GRPO比PPO少了value model,所以GRPO采用了一个更简单的方式来代替它的功能。
实际上无clip
loss函数还有一个clip,用来约束新旧策略每次迭代之间不要偏移得太远。
但实际是代码实现上GRPO 的损失没有 clip,也直接假设ratio=1,( TRL 源码也是这样做的。)
对应代码中的 torch.exp(per_token_logps - per_token_logps.detach()),exp内恒为0,但有梯度,且$e^0=1$。
这是因为只update一次,如deepseekmath中所说。
“The policy model only has a single update following each exploration stage”——deepseekmath中4.2. Training and Evaluating DeepSeekMath-RL
所以old policy和new policy无变化。
参考资料
github项目: simple_GRPO 《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》 Approximating KL Divergence