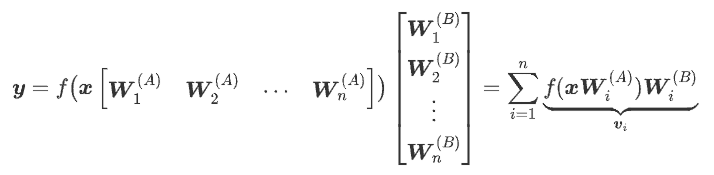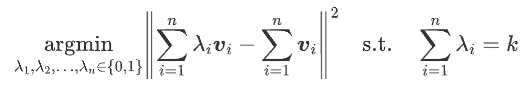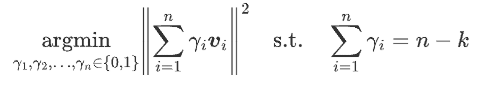MOE是当前比较火的技术之一。比如Mistral、当前最火的deepseek都用到了这一技术。
MOE具有预训练速度更快,推理速度更快的性质。但泛化能力不足,对显存需求比较高。
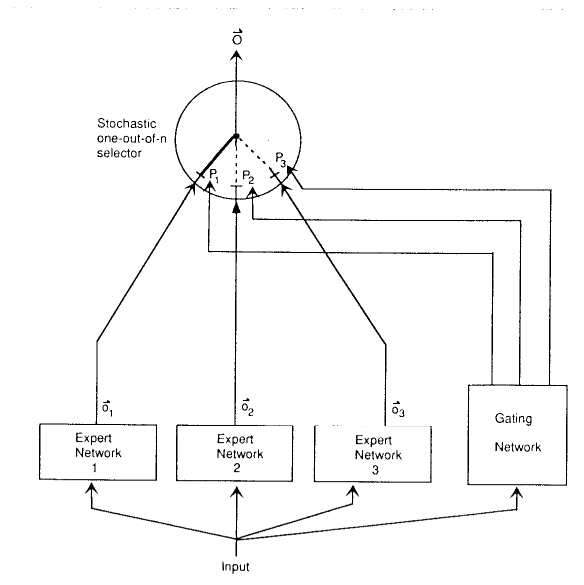
起源 MOE起源于1991的《Adaptive mixture of local experts》
原论文和BP比,且有着不错的性能。
从其论文图像就可以看出MOE的雏形和如今很像。
发展 在LLM潮浪之前,谷歌多个团队都有着几篇惊艳的论文。
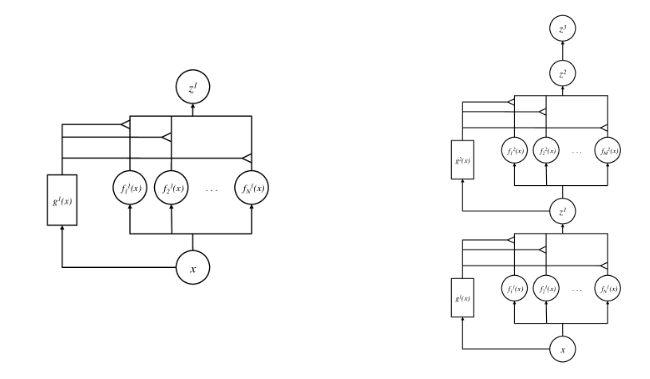
2013年的《Learning Factored Representations in a Deep Mixture of Experts》 作者有Ilya Sutskever。
架构图:
可以看出在原始的基础上还更多考虑了深度。
作者发现,Deep Mix of Experts 自动学习在第一层培养位置相关(“where”)的专家,在第二层自动学习培养特定于类(“what”)的专家。
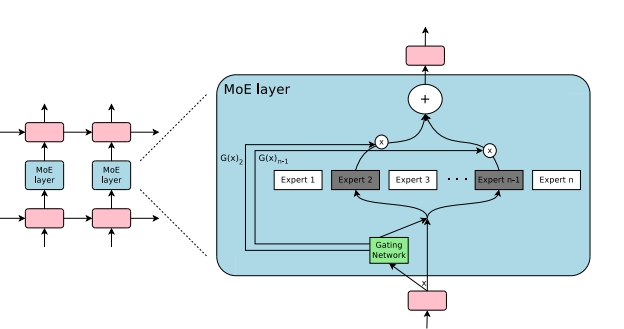
2017年的《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》 作者有Jeff Dean和Hinton。
架构图:
稀疏门控函数选择两个专家来执行计算。他们的输出由门控网络的输出调制。类似于后面的Top2 MOE。
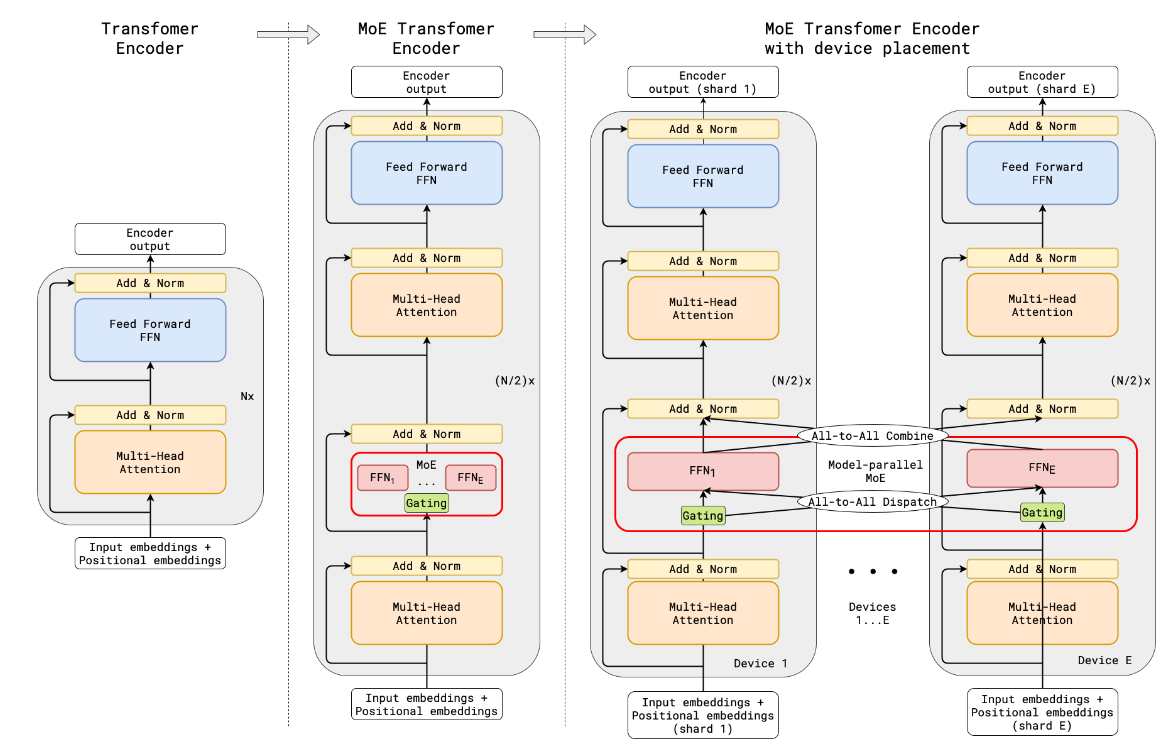
2020年的《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》 架构图也是类似的:
在前人的基础上增加了负载均衡、Auxiliary loss、为了能在多个GPU上并行运行的切片等相关操作。
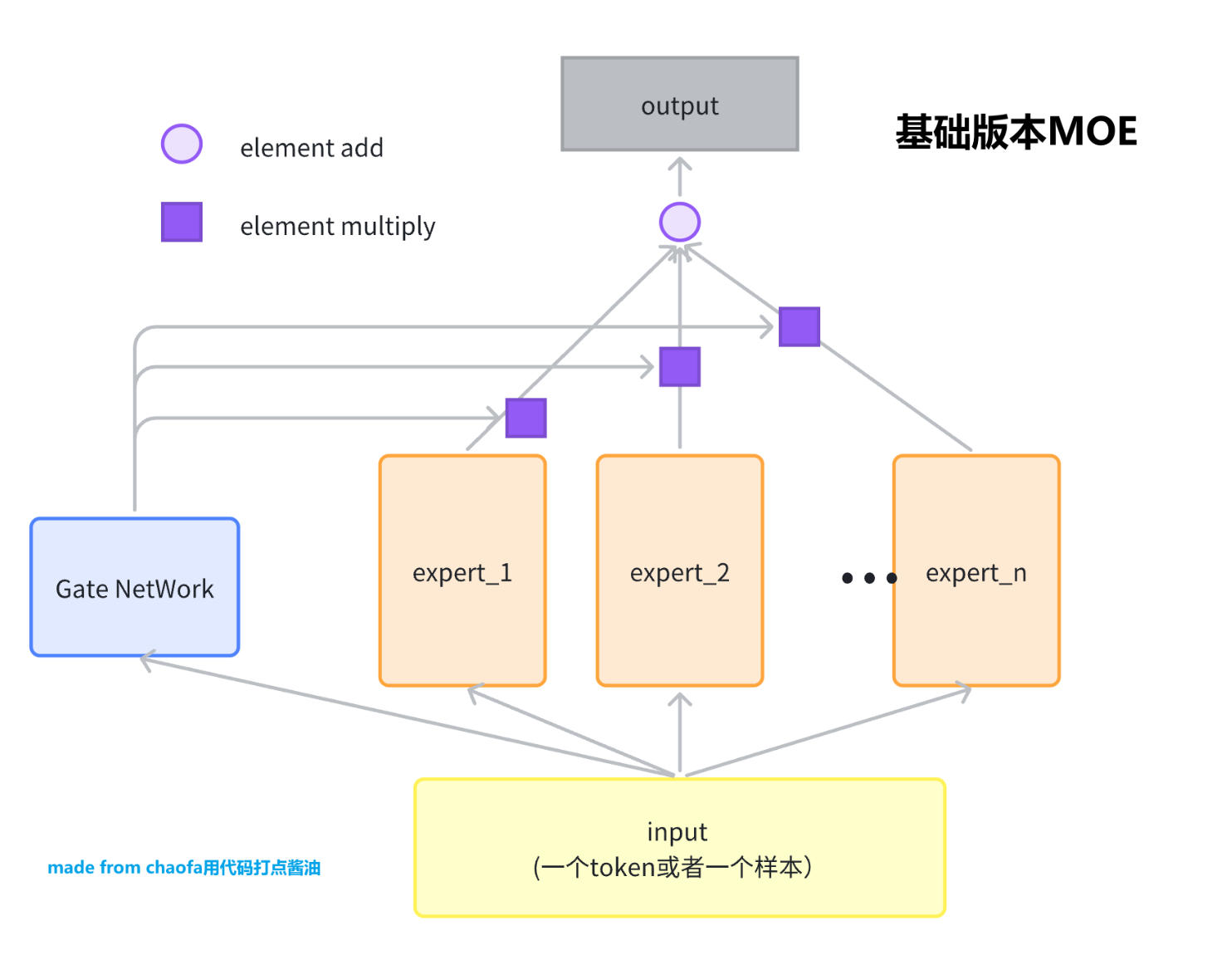
基础版本MOE MOE是FFN的替代品,其中的Expert 一般是一个 FeadFoward Network,FFN。
1 2 3 4 5 6 7 8 9 10 class BasicExpert (nn.Module):def __init__ (self, feature_in, feature_out ):super ().__init__()self .linear = nn.Linear(feature_in, feature_out)def forward (self, x ):return self .linear(x)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class BasicMOE (nn.Module):def __init__ (self, feature_in, feature_out, expert_number ):super ().__init__()self .experts = nn.ModuleList(for _ in range (expert_number)self .gate = nn.Linear(feature_in, expert_number)def forward (self, x ):self .gate(x) 1 ) for expert in self .experts1 )1 ) return output.squeeze()def test_basic_moe ():2 , 4 )4 , 3 , 2 )print (out)
SparseMoE (大模型训练使用) 比较有名的是switch transformer。
编码器解码器结构
1.6万亿参数的Moe, 2048个专家
网络结构升级
预训练速度为T5-XXL的4倍
和 Basic 区别是,MOE 选择 topK 个专家,然后对这 topK 个专家的输出进行加权求和,并且把输入样本变成了大模型中真实的输入 Shape,(batch, seq_len, hidden_dim)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 class MOERouter (nn.Module):def __init__ (self, hidden_dim, expert_number, top_k ):super ().__init__()self .gate = nn.Linear(hidden_dim, expert_number)self .expert_number = expert_numberself .top_k = top_kdef forward (self, hidden_states ):self .gate(hidden_states) 1 , dtype=torch.float )self .top_k, dim=-1 sum (dim=-1 , keepdim=True )self .expert_number2 , 1 , 0 ) return router_logits, router_weights, selected_experts, expert_maskclass MOEConfig :def __init__ ( self, hidden_dim, expert_number, top_k, shared_experts_number=2 , ):self .hidden_dim = hidden_dimself .expert_number = expert_numberself .top_k = top_kself .shared_experts_number = shared_experts_numberclass SparseMOE (nn.Module):def __init__ (self, config ):super ().__init__()self .hidden_dim = config.hidden_dimself .expert_number = config.expert_numberself .top_k = config.top_kself .experts = nn.ModuleList(self .hidden_dim, self .hidden_dim) for _ in range (self .expert_number)self .router = MOERouter(self .hidden_dim, self .expert_number, self .top_k)def forward (self, x ):1 , hidden_dim) self .router(hidden_states)for expert_idx in range (self .expert_number):self .experts[expert_idx]0 1 , hidden_dim) 1 ) 0 , top_x, current_hidden_states.to(hidden_states.dtype))return final_hidden_states, router_logits def test_token_level_moe ():2 , 4 , 16 )16 , 2 , 2 )print (out[0 ].shape, out[1 ].shape)
数学理解 苏神对这一类型的MOE做了一个偏数学的分析。
1、一个常规的Dense模型FFN,可以等价改写为n个Expert向量v1,v2,⋯,vn之和;
FFN可以写为
2、为了节省计算量,我们试图挑出k个向量求和来逼近原本的n个向量之和;
MOE要解决的问题是:
能否只挑k个向量的和来逼近n个向量的和呢?这样就可以将计算量降低到k/n了。
3、转化为数学问题求解后,我们发现挑选规则是模长最大的k个向量;
写成数学公式是
记$\gamma_i = 1 - \lambda_i$,则
在这里苏神强行地假设了$v_i$两两正交。(我觉得这个可以和高维空间任取两个向量几乎正交的性质 结合起来)
则上式最优解显然就是让模长$||v_i||$最小的$n-k$个$\gamma_i$等于1。
4、直接去算n个Expert的模长然后选k个实际上是不省计算量的,所以要重新设计Expert;
5、将$v_i$归一化得到$e_i$,然后用另外的小模型(Router)预测模长$p_i$,最终的Expert为$p_ie_i$;
归一化即$\boldsymbol{e}_i = \boldsymbol{v}_i/ \Vert\boldsymbol{v}_i\Vert$
我们也不一定用L2 Normalize,也可以gamma参数恒等于1的RMS Norm等等等。
PS:当实际上当前主流的MOE都没有归一化操作,苏神也在他博客的评论区指出。
6、此时,我们就可以先算全体$p_i$,挑出k个后才去计算$e_i$,达到节省计算量的目的。
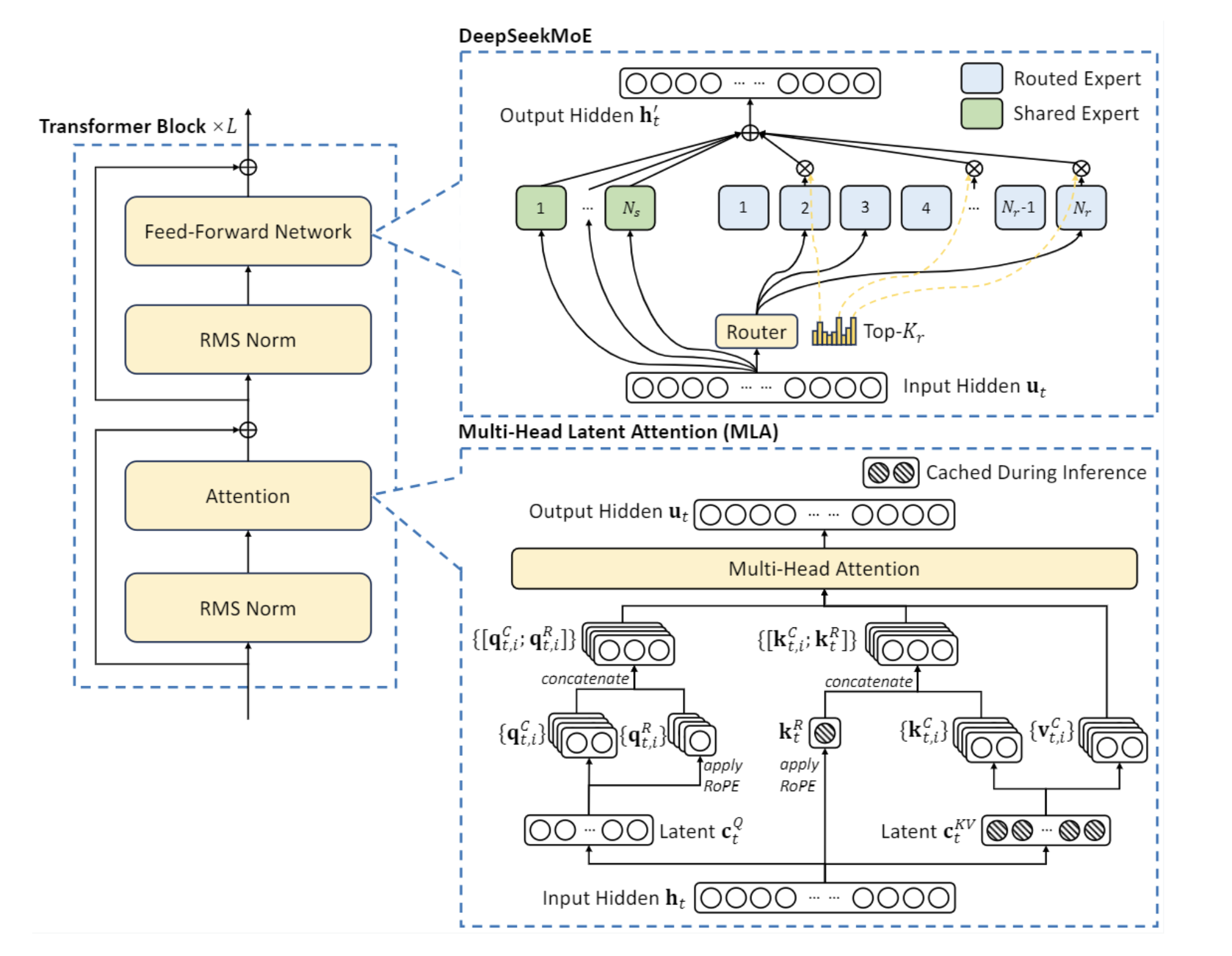
ShareExpert SparseMoE (deepseek 版本) 和前面的sparsemoe不同的是,有一个shared experts 的模型,是所有 token 共享的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class ShareExpertMOE (nn.Module):def __init__ (self, config ):super ().__init__()self .moe_model = SparseMOE(config)self .shared_experts = nn.ModuleList(for _ in range (config.shared_experts_number)def forward (self, x ):self .moe_model(x)for expert in self .shared_experts0 sum (dim=0 )return sparse_moe_out + shared_experts_out, router_logitsdef test_share_expert_moe ():2 , 4 , 16 )16 , 2 , 2 )print (out[0 ].shape, out[1 ].shape)
模型训练测试代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 def switch_load_balancing_loss (router_logits: torch.Tensor, num_experts: int ) -> torch.Tensor:""" 计算 Switch Transformers 的负载均衡损失 Args: router_logits: shape [batch_size * sequence_length, num_experts] num_experts: 专家数量 Returns: total_loss: 总损失 = auxiliary_loss + z_loss """ 1 ) 2 , dim=-1 ) float () 0 )sum (actual_load * router_probs.mean(dim=0 )) * num_experts0.001 return total_lossdef test_moe_training ():32 16 32 100 4 ,2 ,2 )0.001 )for batch in range (num_batches):0.01 * aux_lossif batch % 10 == 0 :print (f"Batch {batch} , Loss: {total_loss.item():.4 f} " f"(MSE: {mse_loss.item():.4 f} , Aux: {aux_loss.item():.4 f} )" )
微调 (1)冻结MOE,这个更好,和全量更新相当。
(2)冻结除MOE以外的,类似于迁移学习。
参考资料
LLM MOE的进化之路,从普通简化 MOE,到 sparse moe,再到 deepseek 使用的 share_expert sparse moe MoE环游记:1、从几何意义出发