利用物理知识进行预测的机器学习综述
《Machine Learning with Physics Knowledge for Prediction: A Survey》
36页的综述,还是比较详细的。
这项调查研究了将机器学习与物理知识相结合进行预测的广泛方法和模型,重点关注偏微分方程。这些方法引起了人们的极大兴趣,因为它们通过使用小型或大型数据集改进预测模型以及具有有用归纳偏差的表达预测模型,对推进科学研究和工业实践产生潜在影响。该调查分为两个部分。第一个考虑通过目标函数、结构化预测模型和数据增强将物理知识融入架构级别。第二个观点将数据视为物理知识,这促使人们将多任务、元和情境学习视为以数据驱动的方式整合物理知识的替代方法。最后,我们还提供了这些方法应用的工业视角,以及对物理信息机器学习的开源生态系统的调查。
简介
结合数据和机器学习方法的各种方式
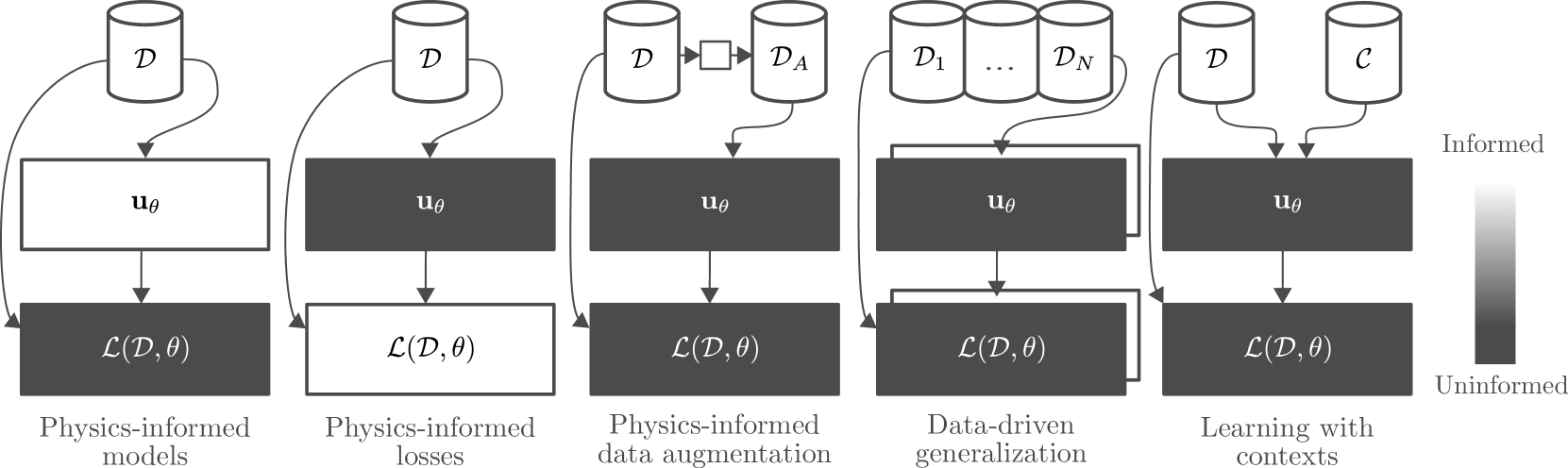
贡献:
这项调查的贡献是从机器学习的角度关注物理信息学习的挑战。这包括研究基于物理的架构和损失函数,以及适用于基于物理的环境的模型和方法,例如潜变量模型、数据增强、多任务学习和元学习。该调查旨在实现几个关键目标。首先,我们的目标是向机器学习研究人员识别和传达物理信息学习中的突出挑战,为未来的研究方向提供途径。其次,该调查提供了重要的指导,将物理知识学习概念定位在更广泛的机器学习领域以及各个工程领域之间的联系中。第三,我们建立了一个精细的方法分类法,为分类和区分不同方法提供了一个结构化框架。此外,该调查还评估了用于评估这些方法和用例的工业相关性的框架。 最后,我们确定了可能影响工业应用的未来趋势。通过这些贡献,该调查旨在弥合理论研究和实际实施之间的差距,使基于物理的机器学习更加强大和有用,以解决现实世界中的棘手问题。
背景
常微分方程
偏微分方程
系统识别(System Identification):
系统辨识是利用输入和输出的测量来构建动力系统数学模型的实践。这种实践是整个科学和工程的基础,以便根据观察到的现实来建立和校准数学模型。
系统识别涉及通过一系列输入来定义系统的动态$w_ t$,测量值$y_ t$,以及初始状态 $x_ {1}$ 在有限的地平线上$T$ 作为轨迹,即 $Y=[ \mathbf{y}_ 1,…,\mathbf{y}_ T]$ 。
通常,假设马尔可夫动力系统,即状态$x_ t+1=f_ \theta (x_ t,w_t)$和观察$y_ t=g_ \theta(x_ t)$两者参数化为$ \theta$,以及状态和观测值之间的映射$g$通常被设计为简化学习问题并确保可观察性。此外,可以添加附加噪声项来捕获动态和传感器中的不确定性,从而产生可能性$p(x_ {t+1}\mid x_ t,w_ t,\theta)$ 和$p(\mathbf{y}_ t\mid\mathbf{x}_ t,\boldsymbol{\theta})$。
由于轨迹数据不是独立同分布(IID),因此数据集上的典型回归方法可能无法产生令人满意的结果,因为随着时间的推移,预测误差可能会因累积的预测误差而发生漂移。一种可能的解决方案是通过时间反向传播,
$$
L_{BPTT}(\theta) = \sum_{k=1}^{K} \sum_{t=1}^{T-h} \sum_{j=1}^{h} L(y_{t+j+1}^{(k)}, g_{\theta}(f_{\theta} \circ \cdots \circ f_{\theta}(x_{t}^{(k)}, w_{t}^{(k)})),
$$
其中考虑了预测误差$\kappa$时间范围内的轨迹$h$ 。这捕获了预测问题的顺序性质,但需要更昂贵且可能更难以优化的巨标。概率方法考虑联合分布$p(Y,X|W,\theta)$继续马尔可夫假设,分解为$p(x_1)\Pi_{t=1}^Tp(y_t|x_t,\theta)p(x_{t+1}|x_t,w_t,\theta)$。潜在状态$x$使用贝叶斯过滤和平滑算法推断,以及模型参数$\theta$进行优化以最大化测量的对数边际可能性$\mathcal{L}_\mathrm{LML}(\boldsymbol{\theta})=\log\int p(\boldsymbol{Y},\boldsymbol{X}|\boldsymbol{W},\boldsymbol{\theta})$d$\boldsymbol{X}$使用期望最大化 (EM)等算法。如果后验概率为1,则需要近似推理技术$p(X\mid Y,W,\theta)$不能以封闭形式计算。
神经网络函数逼近
知识驱动的物理学先验
从数据中学习差分模型
学习物理过程模型的一个挑战是我们的现实存在于连续时间中,而数值算法需要离散化。在这种情况下,一个有用的归纳偏差是通过将积分纳入预测来定义连续时间内的(黑盒)模型。结果是一个更灵活的预测模型,可以在不规则的时间间隔上学习和预测,而不是严格的离散化。这种方法称为学习微分方程。
常微分方程
ODE 和深度学习之间的联系——神经 ODE,是一个强大的工具。也许学习微分方程的最早尝试是He 等人提出的 ResNet 架构(即残差流块)。尽管最初的动机是减轻早期层参数的梯度衰减。 ResNet 块定义离散时间残差变换:$x_ {t+1} = x_ t +f_ {\theta_ t}(x_ t)$
受 ResNet 架构的启发, Weinan ( 2017 )和Haber 等人。 ( 2018 )都提出参数化(无穷小)连续时间变换:
$\frac{\mathrm{d}x(t)}{\mathrm{d}t}=f_ {\theta}(x(t),t),$
这相当于离散时间变换 $x_ {t+1}-x_ t=\epsilon f_ \theta(x_ t)$,其中$\epsilon\to 0$。从神经网络的角度来看, Chen 等人表明方程上述相当于具有起始输入的“连续深度”神经网络 $x_0$ 和连续权重 $\theta$ 。这种网络的可逆性自然来自于 ODE 解的存在唯一性定理。
使用神经 ODE 进行预测和训练需要选择 ODE 求解技术,这又需要时间变量的离散化。神经 ODE 的强大之处在于其训练时的内存效率,无需通过求解器进行反向传播,从而使其能够有效地学习长范围数据序列。
具有物理信息损失的学习解决方案领域
代数结构的学习模型
算子学习
动力系统的潜变量模型
桥接系统辨识与功能逼近
不变性驱动的先验
数据驱动的实验先验
pass
工业应用探讨
文献中描述的利用物理知识进行机器学习的工业应用案例
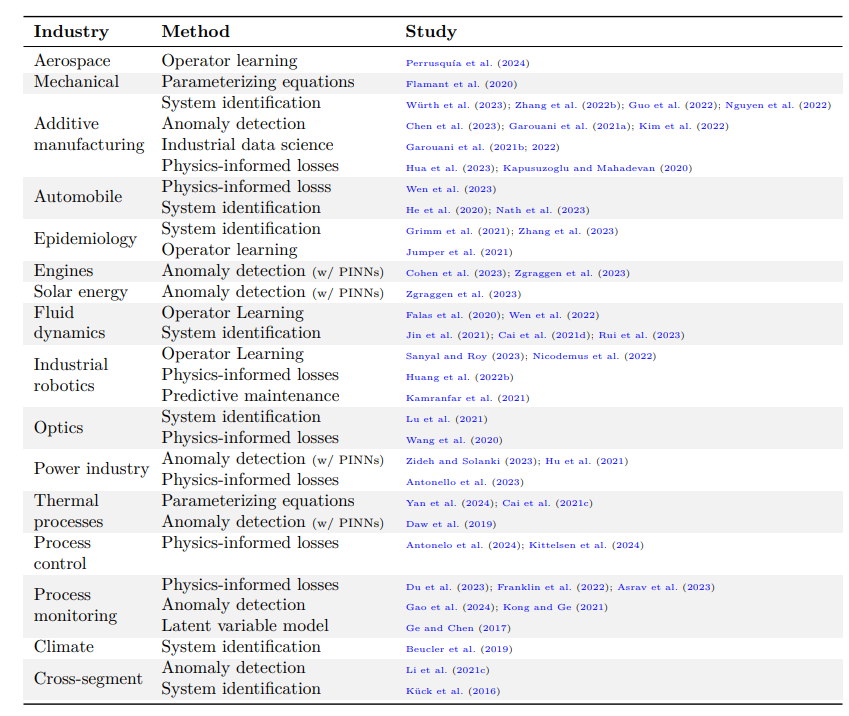
尽管应用前景广阔,但仍不确定这些方法是否会取代传统的数值方法。在天气预报等数据丰富的环境中,机器学习已经取得了重大进展(Lam 等人, 2023 年;Kurth 等人, 2023 年) 。然而,在工业环境(例如过程工业或制造业)中应用机器学习的真正挑战在于,与消费市场的要求相比,它们的要求不同(Hoffmann 等人, 2021a ) 。工业环境通常处理稀疏数据,操作员可能会因其不透明性而对黑匣子系统持怀疑态度。