CAAFE-将大型语言模型与半自动化数据科学的表格预测器相结合
CAAFE这是一种针对表格数据集的特征工程方法,该方法利用LLM基于数据集的描述,迭代地为表格数据集生成附加的语义上有意义的特征。该方法生成用于创建新功能的 Python 代码以及对所生成功能的实用程序的解释。尽管方法简单,但 CAAFE 提高了 14 个数据集中的 11 个的性能 - 将所有数据集的平均 ROC AUC 性能从 0.798 提高到 0.822 - 类似于在我们的数据集上使用随机森林而不是逻辑回归所实现的改进。此外,CAAFE 可以通过为每个生成的特征提供文本解释来解释。 CAAFE 为数据科学任务中更广泛的半自动化铺平了道路,并强调了上下文感知解决方案的重要性。
Team AGA等人使用该方法同autogluon结合,获得了TPS S4E8 automl比赛的第二名
动机
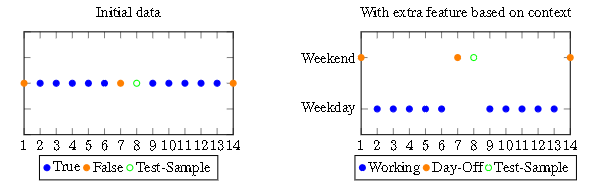
上下文信息可以极大地简化任务。在左侧,图中没有添加任何上下文信息,并且很难预测绿色查询点的标签。在右侧添加了上下文信息,并派生出有用的附加特征(周末或工作日),从中可以找到从特征到目标的映射。
方法

上图显示了CAAFE在Tic-Tac-Toe Endgame数据集上的示例运行。用户生成的输入以蓝色显示,ml分类器生成的数据以红色显示,LLM生成的代码以语法高亮显示。生成的代码包含每个生成的特性的注释,该注释遵循我们提示中提供的模板(特性名称、有用性描述、生成代码中使用的特性以及这些特性的样例值)。在这次运行中,CAAFE在两次特征工程迭代中将验证数据集上的ROC AUC从0.888提高到1.0。

上图显示了CMC dataset的完整prompt。
CAAFE-将大型语言模型与半自动化数据科学的表格预测器相结合
https://lijianxiong.space/2024/20240811/