最大率失真(Maximal Coding Rate Reduction)是马毅组的作品。用于构建可解释性的神经网络。
马毅教授自称”弄明白了深度学习“,并把这一套理论命名为Deep (Convolution) Networks from First Principles。可以看出是比较大的名头。
最大率失真
《Learning Diverse and Discriminative Representations via the Principle of Maximal Coding Rate Reduction》
2007年马毅等人提出了编码整个数据集的feature所需要的比特数。

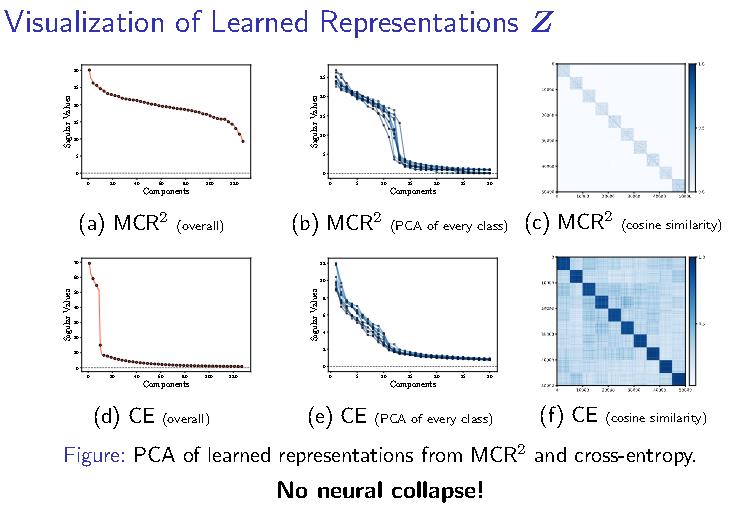
一个很自然的想法即所有特征的空间最大,但类内的特征空间尽量小。智能即压缩!

其会使得特征空间正交化。

进一步我们可以使用projected gradient ascent。
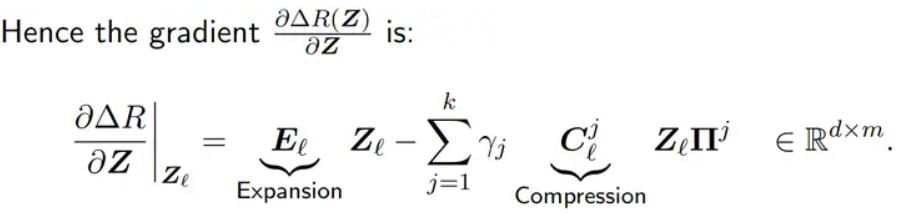
这长得像线性回归,所以我们可以执行那一套。
我们还可以使用softmax来进行分类。
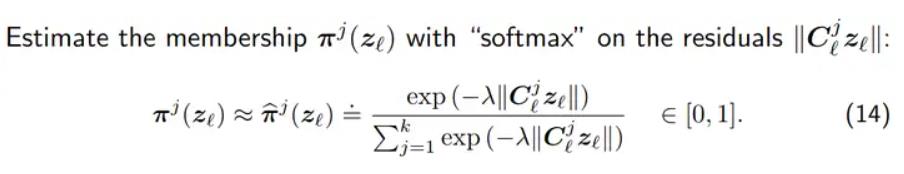
最终进行整理,我们可以得到以下结构,这正是马毅等提出的Redunet。
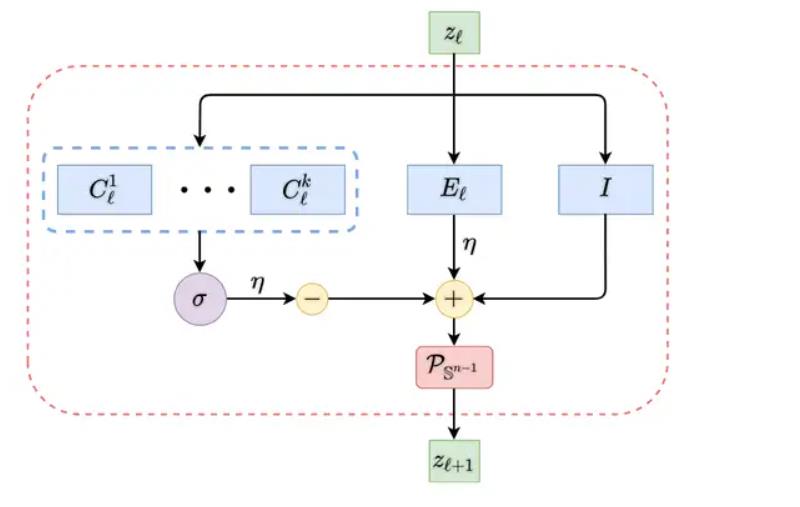
可以看到有resnet、MOE等的影子。
图上的应用
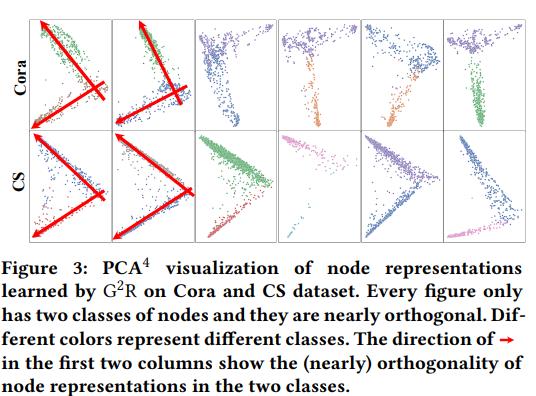
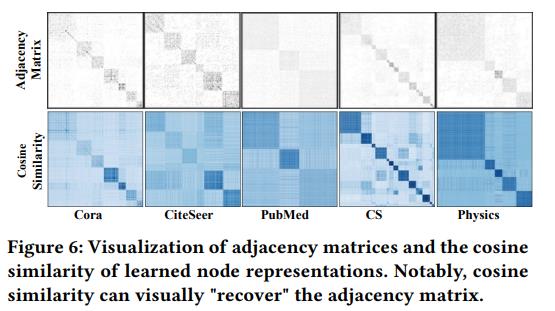
我们主要讲WWW2022《Geometric Graph Representation Learning via Maximizing Rate Reduction》。ICASSP2024也有一篇《Maximal Coding Rate Reduction for Graph Embeddings》。
原始的MCR2的公式为
$$
\frac{1}{2}logdet(I+\frac{d}{m\epsilon^2}ZZ^T)-\sum \frac{\Pi_j}{2m}logdet(I+\frac{d}{tr(\Pi_j)\epsilon^2}Z\Pi_j Z^T)
$$
作者改写为:
$$
\frac{1}{2}logdet(I+\frac{\gamma_1p}{m\epsilon}ZZ^T)-\sum \frac{sum(\Pi_j)}{2m}logdet(I+\frac{p}{tr(\Pi_j)\epsilon}Z\Pi_j Z^T)
$$
p是特征维度,$\Pi$是邻接矩阵。
代码:https://github.com/ahxt/G2R
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| class MaximalCodingRateReduction(torch.nn.Module):
def __init__(self, gam1=1.0, gam2=1.0, eps=0.01):
super(MaximalCodingRateReduction, self).__init__()
self.gam1 = gam1
self.gam2 = gam2
self.eps = eps
def projection(self, z: torch.Tensor) -> torch.Tensor:
z = F.normalize(z, dim=0)
return z
def compute_discrimn_loss_empirical(self, W):
"""Empirical Discriminative Loss."""
p, m = W.shape
I = torch.eye(p).cuda()
scalar = p / (m * self.eps)
logdet = torch.logdet(I + self.gam1 * scalar * W.matmul(W.T))
return logdet / 2.
def compute_compress_loss_empirical_all(self, W, Pi):
"""Empirical Compressive Loss."""
p, m = W.shape
k, _ = Pi.shape
sum_trPi = torch.sum(Pi)
I = torch.eye(p).cuda()
compress_loss = 0.
for j in range(k):
trPi = torch.sum(Pi[j]) + 1e-8
scalar = p / (trPi * self.eps)
a = W.T * Pi[j].view(-1, 1)
a = a.T
log_det = torch.logdet(I + scalar * a.matmul(W.T))
compress_loss += log_det * trPi / m
num = data.x.shape[0]
compress_loss = compress_loss / 2 * (num / sum_trPi)
return compress_loss
def forward(self, X, A):
i = np.random.randint(A.shape[0], size=num_node_batch)
A = A[i,::]
A = A.cpu().numpy()
W = X.T
Pi = A
Pi = torch.tensor(Pi, dtype=torch.float32).cuda()
discrimn_loss_empi = self.compute_discrimn_loss_empirical(W)
compress_loss_empi = self.compute_compress_loss_empirical_all(W, Pi)
total_loss_empi = - self.gam2 * discrimn_loss_empi + compress_loss_empi
return total_loss_empi
|
可以看到效果是相当不错的。