Softmax Linear Units Softmax
出自Anthropic’s transformer circuits thread
在本文中,我们报告了一种架构变化,该变化似乎大大增加了看起来“可解释”的 MLP 神经元的比例(即响应输入的可表达属性),而对 ML 性能的影响很小甚至没有。具体来说,我们用 softmax 线性单元(我们称之为 SoLU)替换激活函数,并表明这显着增加了 MLP 层中神经元的比例,这些神经元在快速调查中似乎对应于人类容易理解的概念、短语或类别,通过随机和盲法实验测量。然后,我们研究 SoLU 模型,并使用它们来获得有关 Transformer 中信息如何处理的一些新见解。然而,我们也发现了一些证据,证明叠加假设是正确的,并且天下没有免费的午餐:SoLU 可能通过“隐藏”其他特征来使某些特征更容易解释,从而使它们更加难以解释。尽管如此,SoLU 似乎仍然是一个净胜利,因为实际上它大大增加了我们能够理解的神经元的比例。
SOLU的提出
GeLU是一种现代transformer常用的激活函数
$\mathrm{GELU}(x)=xP(X\leq x)=x\Phi(x)=x\cdot\frac{1}{2}\left[1+\mathrm{erf}(x/\sqrt{2})\right]$
一种近似版本:
$0.5x\Big(1+\tanh\Big[\sqrt{2/\pi}\Big(x+0.044715x^{3}\Big)\Big]\Big)$ 或$x\sigma(1.702x)$
于是Anthropic研究者们考虑了将sigmoid换为softmax。
将此激活函数称为“softmax 线性单元”或 SoLU:
SoLU(x)=x*softmax(x)
当 SoLU 应用于大值和小值的向量时,大值将抑制较小值:
SoLU(4,1,4,1)=(1.9051, 0.0237, 1.9051, 0.0237)≈(2, 0, 2, 0)
也许更重要的是,保留了大的基础对齐向量,而跨多个维度分布的特征将被抑制到较小的量级:
SoLU(4,0,0,0) ≈ (4,0,0,0)
SoLU(1,1,1,1) ≈ ($\frac{1}{4}$, $\frac{1}{4}$, $\frac{1}{4}$, $\frac{1}{4}$)
初步实验发现,简单地使用 SoLU 激活函数似乎可以使神经元更容易解释,但会付出很大的性能代价。一般来说,没有任何其他改变的 SoLU 模型的性能相当于比实际尺寸小 30-50% 的模型,较大的模型受到的影响更大。 如果叠加假设成立,这正是我们所期望看到的——我们可以减少多语义性,但这样做会损害网络的机器学习性能。
然而,我们凭经验发现,通过在 SoLU 之后应用额外的 LayerNorm(类似于
[25]
),可以修复这种性能损失,同时保留可解释性增益。这极大地提高了 ML 性能,因此对于我们的大多数实验,我们实际应用的函数是 2 但请注意,我们尝试解释的激活是在额外层规范之前,而不是之后:
$$
f(x)=LN(SoLU(x))=LN(x*softmax(x))
$$
实验
“请注意,以任意性能代价来构建提高可解释性的架构既微不足道又无趣。”
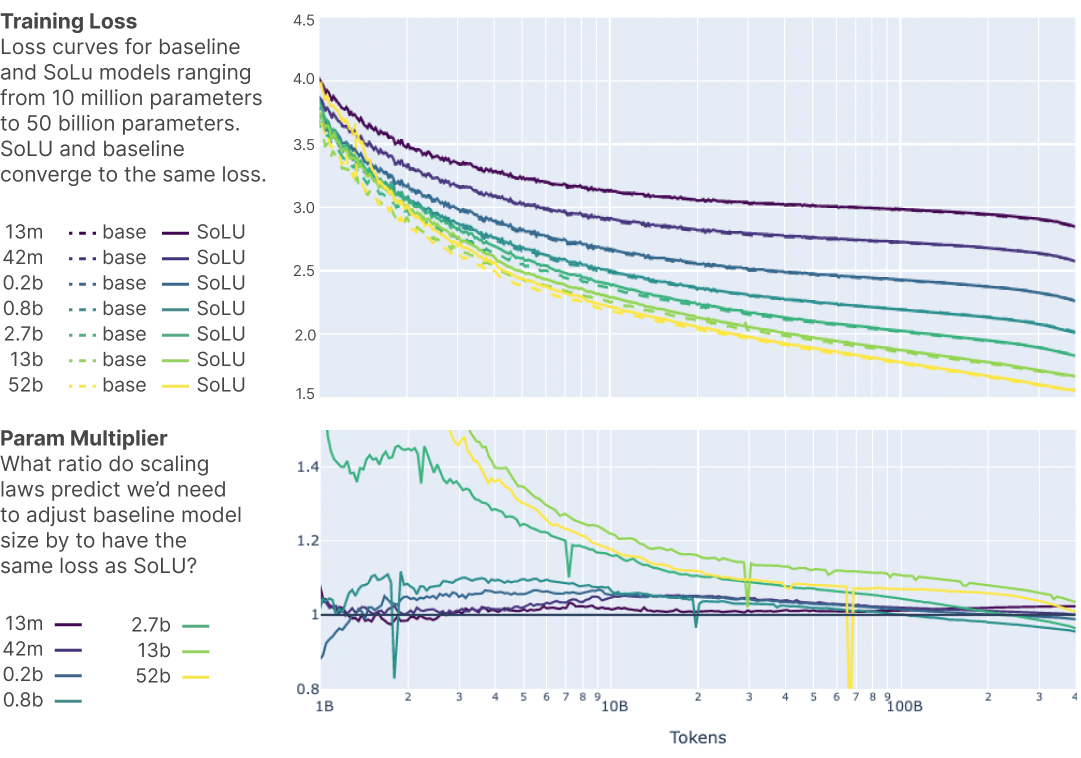
如图所示,SoLU 大致相当于所有模型大小的基线,始终落在模型大小的 1.05 倍和 0.95 倍乘数之间(与大多数情况下相比,大致相当于 ±0.01 纳特的损失变化)总共损失 1.6-3 纳特)。 尽管所有差异都很小并且更有可能是随机噪声(在 50B 模型上,SoLU 相当于将模型大小增加 1.01 倍),但在大模型尺寸下,SoLU 的性能可能会比基线稍好一些。 )。
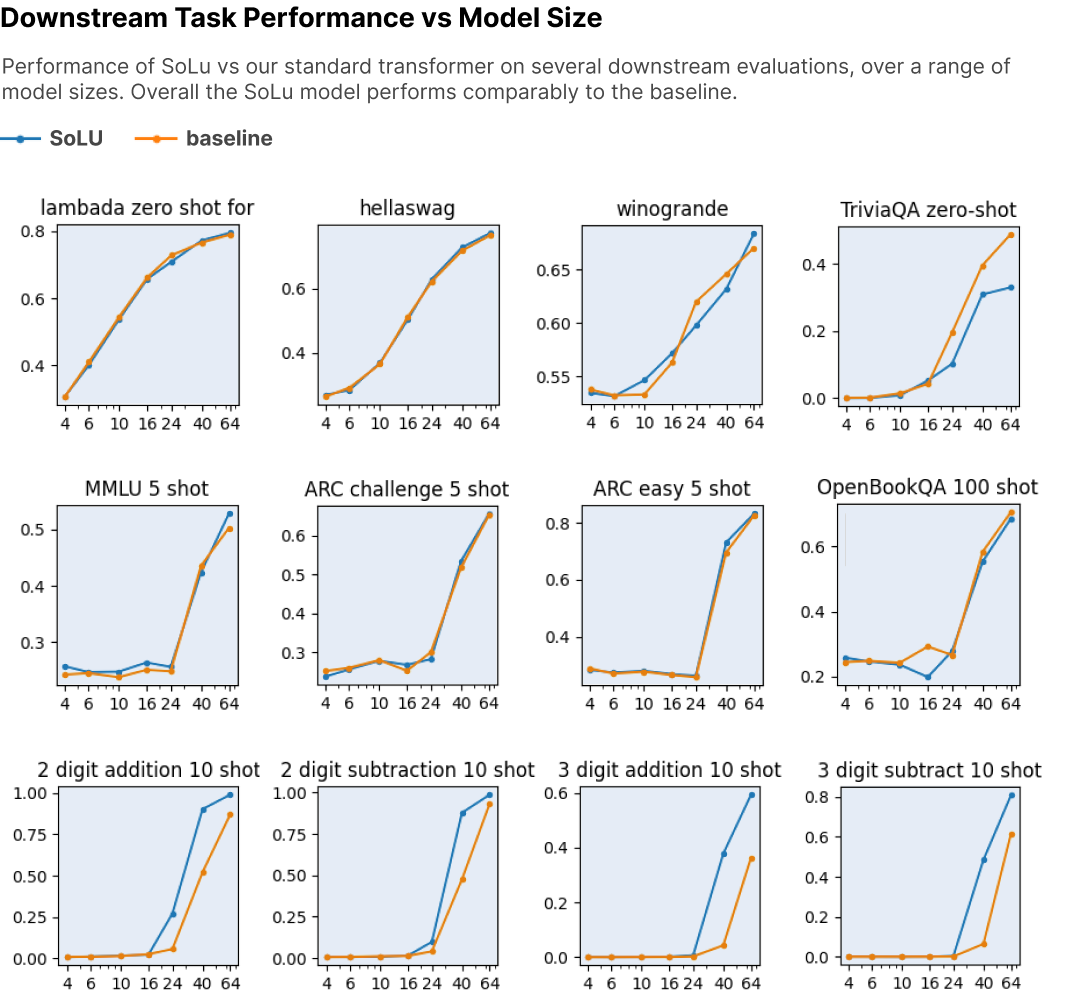
上图为下游任务的性能。由于SoLU 使用基线的一系列超参数,并且 SoLU 的最佳超参数可能与基线模型的最佳超参数不同。但表明 SoLU 至少与基线一样好。
总的来说,我们得出的结论是,与标准 Transformer 相比,带有 LayerNorm 的 SoLU 似乎实现了有竞争力的 ML 和训练性能。
可解释性
定量结果
我们关于哪些部分的神经元可以初步解释的实验结果如下图 4所示。对于从 1 层到 40 层的模型,SoLU 模型的神经元比基线的神经元更具可解释性,增加了大约 25 个绝对百分点,从约 35% 可解释到约 60% 可解释。 这将可解释神经元的比例增加了 1.7 倍。 尽管效果大小适中,但样本量、一致的间隙和一致的可解释神经元绝对率表明 SoLU 模型具有真实且持久的效果。
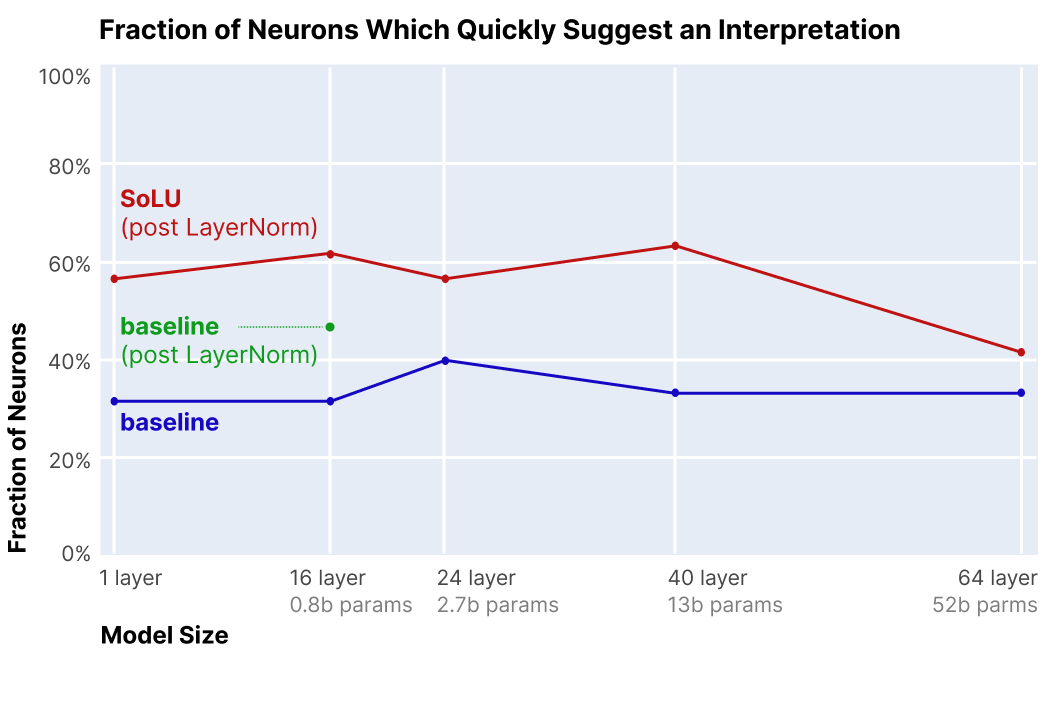
蓝线显示了标记为初步表明基线变换器中模型大小范围从 1 到 64 层的解释的神经元分数。 红线显示了标记为初步暗示 SoLU 转换器中的解释的神经元部分。 绿点显示了标记为初步表明 16 层模型中带有额外层范数但不带有 SoLU 的解释的神经元的分数。 总体而言,在 1 层到 40 层的模型中,SoLU 将可解释神经元的比例增加了约 25%,而在 64 层模型中,增益要小得多。
我们不知道为什么 64L 模型从 SoLU 中受益较少,但一种可能的理论是,随着模型变得更大,它们的神经元代表更复杂的概念并且变得更难以理解。这表明神经元仍然是可解释的,但不再“容易解释”。
定性
一层模型神经元

1 层 SoLU 模型中的神经元似乎对 Base64 编码的文本进行触发(左)。神经元对 logits 的扩展权重(右)增加了混合情况下很少出现在单词中的一堆标记的概率,同时降低了代表英语单词的多个标记的概率,这一事实证实了这一点。可以将其理解为一个可解释的规则,即在 Base64 文本上,下一个标记更有可能也是 Base64。
较大模型中的前面的神经元(”DE-TOKENIZATION”)
接下来我们将探索转向更大的型号——我们剩下的示例将来自 16L、24L、40L 和 64L 型号的混合。 我们最有趣的发现之一是,大型网络的早期、中期和晚期层的神经元往往扮演着非常不同类型的角色,就像已知的卷积网络视觉模型不同深度的特征是不同的一样。 我们将在各自的部分中讨论每个神经元,从前面层的神经元开始。
前面层神经元似乎经常参与将标记的“人工”结构映射到更自然、语义上有意义的表示。
- 神经元对被分成多个标记的特定单词做出反应:“银行”、“措辞”、“胆固醇”、“自由主义者”、“平民”、“上海”、“尽管如此”……
- 神经元对名人的名字做出反应:“马丁·路德·金”、“唐纳德·特朗普”、“林登·约翰逊”、“乔治·奥威尔”、“欧内斯特·海明威”、“穆罕默德·阿里”、“奥普拉·温弗瑞”……(参见 [17] )
- 神经元对其他名词做出反应:“人权观察”、“国际货币基金组织”、“马修飓风”、“皇家马德里”……
- 神经元对复合词做出反应:“读书俱乐部”、“社会保障”、“计算机视觉”、“有组织犯罪”、“生日聚会”、“心脏病发作”……
- 神经元响应 LaTeX“\”命令:“\left”、“\frac{”、“\begin”…
较大模型中的后层神经元(“RE-TOKENIZATION”)
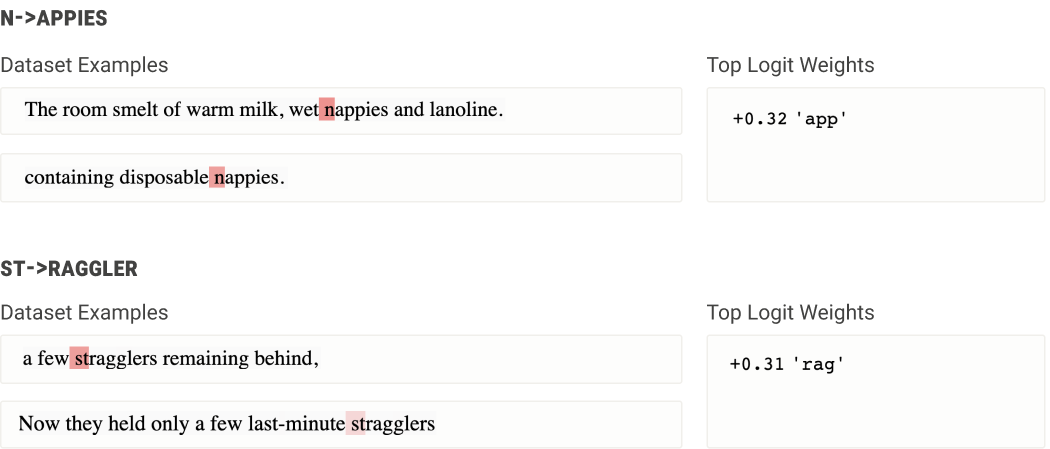
后期层神经元(靠近网络输出的神经元)通常会做与早期层神经元相反的事情:它们介导单词或上下文标记返回文字标记的转换。例如,最后一层中的一个神经元会触发标记“st”,同时增加后续标记是“rag”的可能性;本质上,这是一种将单词“stragglers”的表示形式逐个转换或指示为其组成标记以进行输出的方法。类似地,“nappies”输出神经元在标记“n”上触发,并增加标记“app”帮助写入“nappies”的概率。这些神经元本质上模拟了一个额外的输出词汇项,该词汇项仅在前面的标记满足某些条件时才可用。
较大模型中的中间层神经元
中间层的神经元通常代表更复杂、抽象的想法。例如,当且仅当数字涉及多个人时,有一个神经元似乎代表数字:

在这些层中可以发现各种各样有趣的神经元。我们观察到的一些常见类别包括:
- 对特定类型的描述性从句激发的神经元:对描述声音的从句激发的神经元、对描述服装的从句激发的神经元、对音乐描述性从句激发的神经元(例如“C 大调”)、对从句激发的神经元描述写在物体上的文字,…
- 对话语标记做出反应的神经元:对强调某件事的重要性的标记做出反应的神经元(例如“令人惊奇的是”),对对冲做出反应的神经元(例如“在我看来……”),……
- 消除对标记的特殊解释的歧义的神经元:当用作成绩时对 A/B/C/D 做出响应的神经元,对日期的“日”部分做出响应的神经元,对数字进行响应的神经元是菜谱中的一个数量,一个响应字符串中 C 风格格式说明符(例如“%s”或“%d”)的神经元,……
但是有很多神经元很难归入这些类别,例如似乎有助于解析 ASCII 表列的神经元。