图彩票论文速览
本文将介绍一系列的图彩票论文。
《a unified lottery ticket hypothesis for graph neural networks(2021ICML).pdf》
相关工作
Lottery Ticket Hypothesis
该论文首先提到了ICLR 2019最佳论文:The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks。该论文提出了彩票假说:密集的、随机初始化的、前馈网络包含子网络(中奖票),这些子网络在孤立地训练时,在类似数量的迭代中达到与原始网络相当的测试精度。
《Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask》也有类似的内容。展示了为什么将权重设置为零很重要,如何使用符号来进行重新初始化的网络训练,以及为什么掩蔽的行为类似于训练。最后,我们发现了超级掩码的存在,这些掩码可以应用于未经训练的随机初始化网络,以生成性能远远优于偶然的模型(MNIST 上为 86%,CIFAR-10 上为 41%)。
ICLR2020 的《Proving the Lottery Ticket Hypothesis: Pruning is All You Need宣称证明了The Lottery Ticket Hypothesis。一句话概括:只要对随机初始化的神经网络做个好剪枝,不怎么训练也能有个好效果。
该文证明了:
Fix some target fully-connected ReLU-network F of width k, depth d and input dimension n.Fix$\delta>0$.Then,arandomly-initialized network $G$ of width $poly(d,n,k,1/\epsilon,\log(1/\delta))$ and depth 2d, has w.p. $\geq1-\delta$ a subnetwork $\tilde{G}$ that approximates F up to $\epsilon.$
简单的说,给定一个深度为d的Relu目标网络。那么一个深度为2d,且足够宽的随机网络里,必然可以找到一个可以逼近目标网络的子网络。
本文
本文这项工作不仅是第一个将 LTH 推广到 GNN 的工作,而且也是第一个将 LTH 从简化模型扩展到新的数据模型联合简化前景的工作。
算法

复杂度分析
GLT 的推理时间复杂度为,其中 L 是层数。
$||\boldsymbol{m} _g\odot\boldsymbol{A}|| _0$是稀疏图中剩余边的数量。
F是节点特征的维度,$|\mathcal{V}|$是节点的数量。内存复杂度为$o(\mathcal{L} \times \left| \mathcal{V} \right| \times \mathcal{F}+ \mathcal{L} \times \left| m_ \theta \right| _ 0 \times \mathcal{F}^2)$。在我们的实现中,剪枝的边将从$\varepsilon$ (边集合)中删除,并且不会参与下一轮的计算。
代码
我们来直接看代码:
主函数
主函数中:
1 | |
每一个epochs中包括了run_get_mask和run_fix_mask,前者是获得mask,后者是保持mask,对模型继续训练。
run_get_mask函数
模型代码:
1 | |
训练部分:
1 | |
我们仔细分析这部分:
对于add_mask函数,对边加mask。
1 | |
对于subgradient_update_mask函数,他是一个 l1 norm
具体而言
1 | |
简单来说,我们知道,$\frac{d}{dx}|x|=sgn(x)$,这里相当于做了一个梯度下降。
其余的就是传统的三件套
1 | |
run_fix_mask函数
1 | |
基本和run_get_mask一样,不同在于,将mask移出训练,也少了l1,和限定epochs。
实验
pass
《searching lottery tickets in graph neural networks a dual perspective(2023ICLR).pdf>
代码:https://github.com/Lyccl/RGLT
相关研究
探索了其对偶问题并提出对偶彩票假说 DLTH:给定随机初始化的网络,其随机挑选的子网络可以被转换成彩票子网络,并得到与 LTH 找到的彩票子网络相当甚至更好的准确率。
算法
DiffPool+mask+GIR(Gradually Increased Regularization)
它的mask矩阵只作用在领接矩阵上。
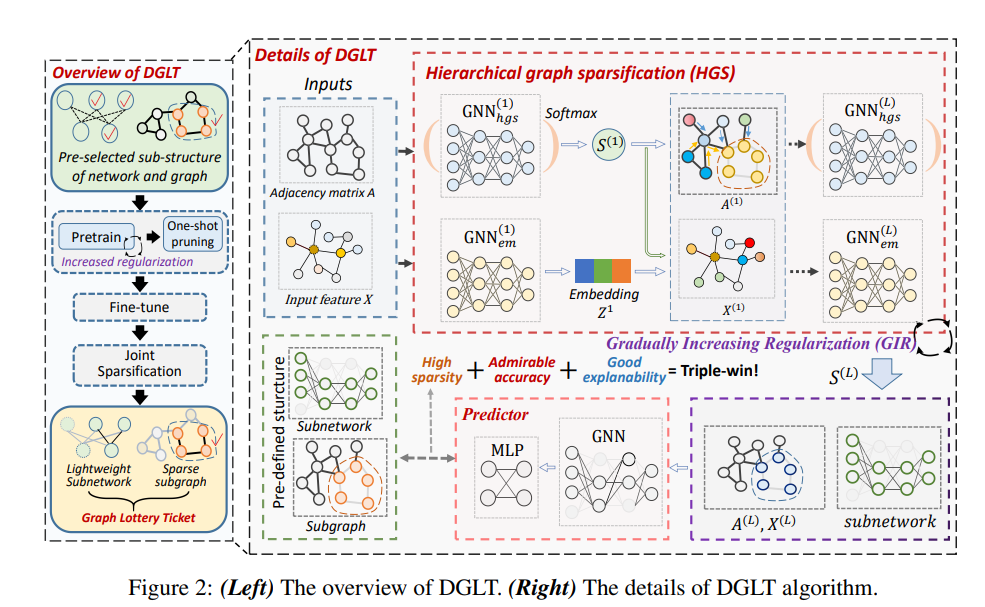
整体算法逻辑为:
1.DiffPool模型训练+GIR
2.one_shot_prune
3.run_fine_tune
1 | |
DiffPool
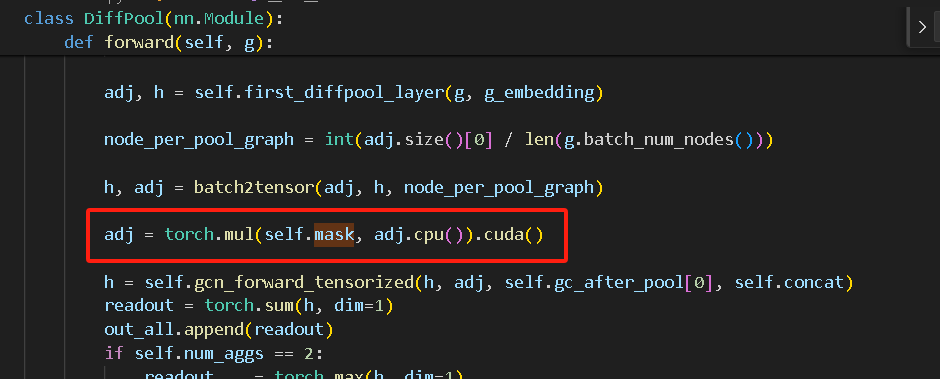
这部分该论文的代码和dgl库的Diffpool完全一样,该论文加了个mask。
例如下图所示,多了红框处的代码。
该论文出自NeurIPS 2018,它是一种可微图池化模块,可以生成图的层次表示,并可以以端到端的方式与各种图神经网络架构相结合。
模型框架:
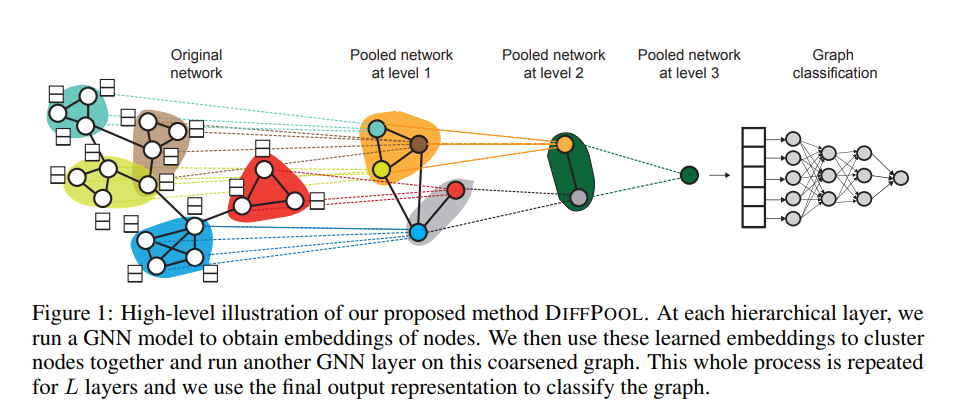
DIFFPOOL 可以表达为 :
$\text{}\left(A^{(l+1)},X^{(l+1)}\right)=\mathrm{DiFF~POOL}\left(A^{(l)},Z^{(l)}\right)$
即
$$
\begin{aligned}&X^{(l+1)}=S^{(l)^{T}}Z^{(l)}\in\mathbb{R}^{n_ {l+1}\times d}\quad(3)\&A^{(l+1)}=S^{(l)^{T}}A^{(l)}S^{(l)}\in\mathbb{R}^{n_ {l+1}\times n_ {l+1}}\quad(4)\end{aligned}
$$
Z称为嵌入矩阵,S称为分配矩阵。
并设计了两套GNN,来获得嵌入矩阵和分配矩阵。
$$Z^{(l)}=\mathrm{GNN}_ {l,\mathrm{~embed}}\left(A^{(l)},X^{(l)}\right)$$
$$S^{(l)}=\mathrm{softmax}\big(\mathrm{GNN}_ {l,\mathrm{pool}}\big(A^{(l)},X^{(l)}\big)\big)$$
Note: 最后一层设置聚类分配矩阵设置输出大小为 1。
作者说,4很难通过梯度进行训练,所以本文采用 最小化Frobenius norm
$$
L_ {\mathrm{LP}}=\left|A^{(l)},S^{(l)}S^{(l)^{T}}\right|_ {F}
$$
这里写的不明白,应该是$$L_ {\mathrm{LP}}=\left|A^{(l)}-S^{(l)}S^{(l)^{T}}\right|_ {F}$$
每个聚类分配矩阵 被希望接近于一个 one-hot 向量,以便明确每个簇的隶属关系,所以本文通过最小化簇分配的熵:
$$
\bar{L}_ {E}=\frac{1}{n}\sum_ {i=1}^{n}H(S_ {i})
$$
其中:H为熵函数$H(X)=-\sum_x\in\tau p(x)\log(x);$
$S_i$为 $S$的第$i$行;
然而,据作者所说,原因是由于分配预测包含 [0,1] 之间的值,因此交叉熵比 Frobenius 范数中的 l2 更有效。官方的代码是使用了交叉熵来代替 Frobenius 范数。
具体而言:
self.link_loss = -adj * torch.log(pred_adj+eps) - (1-adj) * torch.log(1-pred_adj+eps)
模型训练部分:
也是常规的backward三件套,直接来看loss。
loss = model.loss(ypred, graph_labels)
reg_loss = Regularization(model, weight_decays[int(count / 10)], masks, p=2)
pool_loss = cau_loss(mask, model, weight_decays[int(count / 10)])
my_reg = reg_loss(model)
loss = loss + my_reg + pool_loss
即对应论文的
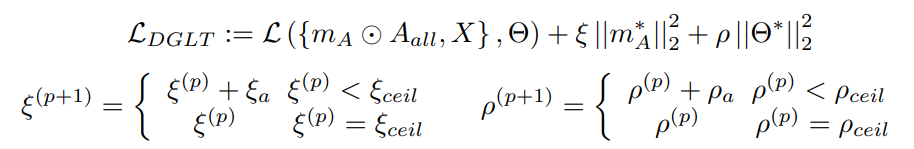
由于正则项的系数会发生递增变化,也就是Gradually Increased Regularization。
我们仔细看下去
对于cau_loss,他是对mask进行正则项的计算,对应上式的第2部分:
1 | |
对于reg_loss,他是对模型参数进行正则项的计算,对应上式的第3部分:
1 | |
注意:mask和masks
one_shot_prune
1 | |
进行随机剪枝操作,和UGS等不同。
run_fine_tune
和train函数是一样的,多了每一epoch后执行类似于one shot_prune的操作
1 | |
理论部分
时间复杂度计算
GLT是$o(\mathcal{L}\times\left|\boldsymbol{m}_ g\odot\boldsymbol{A}\right|_ 0\times\mathcal{F}+\mathcal{L}\times\left|\boldsymbol{m}_ \theta\right|_0\times\left|\mathcal{V}\right|\times\mathcal{F}^2)$
而DGLT是$\mathcal{O}\left(\left|\left|m_ {A}\odot A_ {all}\right|\right|_ {0}\times F+\left|\left|m^{*}\right|\right|_ {0}\times\left|\mathcal{V}\right|\times F^{2}\right)+\mathcal{O}\left(\mathcal{K}\right)$,其中 $m_ {A}= { m_ {A}^{0},:\hat{m}_ {A}^{1}\ldots m_ {A}^{L} }$ 所有领接矩阵的mask。$\mathcal{O}(K)$ 为学习节点嵌入和分配矩阵的推理时间复杂度。它们由多个矩阵相乘得到,推理时间复杂度为$\mathcal{O}\left(\mathcal{K}\right)=\mathcal{O}\left(L\times|\mathcal{V}|^{3}+L\times|\mathcal{V}|\times F\right).$
实验
pass
另外
https://openreview.net/forum?id=Dvs-a3aymPe
DGLT 声称可以将随机预定义的图转换为具有高信息量形式的适当条件。如果这个猜想是正确的,那么它具有相当有希望的实际意义——它表明训练 GNN 模型的消息传递功能(即信息聚合)实际上是不必要的,因为只需要选择邻接矩阵的目标大小或目标GNN的子结构,然后使用层次图稀疏(HGS)算法或逐渐增加正则化进行信息挤出。
《Brave_the_Wind_and_the_Waves_Discovering_Robust_and_Generalizable_Graph_Lottery_Tickets(2023PAMI).pdf》
简介
在现实场景中,未见过的测试数据的分布通常是多种多样的。我们将分布外(OOD)数据的失败归因于无法辨别因果模式,而因果模式在分布变化中仍然保持稳定。在传统的空间图学习中,当图/网络稀疏度超过一定的高水平时,模型性能会急剧恶化。更糟糕的是,由于手头的训练集有限,修剪后的 GNN 很难推广到看不见的图数据。为了解决这些问题,我们提出了弹性图彩票(RGLT),以在 GNN 中找到更强大和更通用的 GLT。具体来说,我们通过每个剪枝点的瞬时梯度信息重新激活一部分权重/边缘。经过充分的修剪后,我们进行环境干预以推断潜在的测试分布。最后,我们执行最后几轮模型平均值以进一步提高泛化能力。
处理大型图有两个主要研究方向,要么简化图,要么压缩 GNN 模型。第一种,各种图形采样策略或稀疏化方法。在第二个流上所做的努力要少得多,即修剪 GNN ,因为 GNN 通常比其他学科中的 DNN 参数化程度较低。
GLT仍然有改进空间:
**鲁棒性降低:**在 GLT 中,当图(或网络)稀疏度达到一定程度 时,GNN 的性能将急剧下降,例如超过70%。从概念上讲,GLT 通过基于幅度的剪枝来识别“幸运”图彩票,这可以看作是极化剪枝,在后续训练中不为中等幅度的权重或边缘留下一些余地。在高稀疏度下,模型很难探索完整的权重空间,并且由于稀疏度约束 ,模型更新路线被切断。
泛化能力降低:
然而,图上的剪枝可能会降低模型的泛化性,因为 GNN 与深度学习网络(例如卷积神经网络)一样需要大量数据。
此外,《Sparse Double Descent: Where Network Pruning Aggravates Overfitting》(ICML2022)揭示了一个相反的现象——网络剪枝有时甚至会在超稀疏和某些中度稀疏现象下恶化泛化性。该文是第一个报告稀疏双下降现象的工作。更具体地说,证明高模型稀疏度可以显着减轻过度拟合,而中等模型稀疏度可能导致更严重的过度拟合。极端的模型稀疏性 ( →100% ) 往往会丢失所有学到的信息。另外,还得到了和 lottery ticket hypothesis 的相反的结论,从原始初始化重新训练稀疏模型可能不会始终获胜。例如,在某些情况下,随机重新初始化的修剪模型可以在很大程度上超越在某些稀疏度下具有原始初始化的模型。
这个意外问题使 GLT 在具有不同样本和实例的实际应用程序中的使用变得复杂。
算法
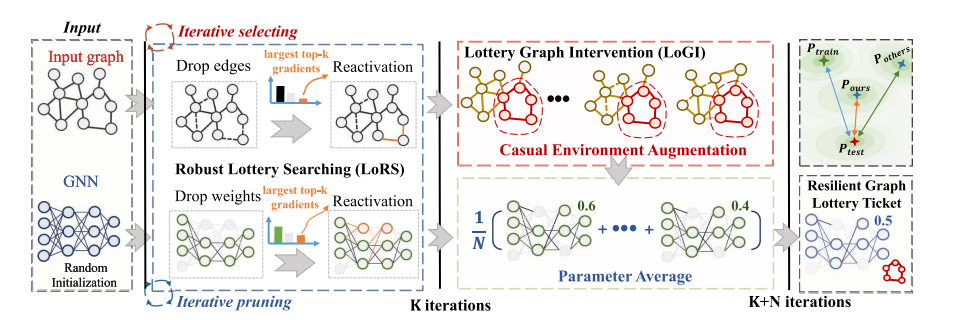
首先,我们执行鲁棒彩票搜索(LoRS)来生成稀疏网络和图的组合。在每次迭代中,我们根据边和权重的大小来修剪边和权重,然后重新激活具有前 k 个梯度的边和权重。然后,我们在核心子图上利用 Lottery Graph Intervention (LoGI) 来推断测试分布,并将增强图传递到剪枝模型以进行下一轮训练。在最后几轮中,我们进行模型平均以进一步提高模型的泛化性。值得注意的是,LoRS 可以独立运行来发现鲁棒图彩票和我们的 LoGI,而 LoGI 算法依赖于 LoRS 识别的核心子图。我们提出的两种算法协同工作,有助于大规模 GNN 应用的落地。
Formulation
本文意图解决一个更有挑战性的问题,
提高模型的泛化能力。假设 $S\text{ 是环境 }^{1}$的支持(support of the environments,?),$f(·)$ 是预测函数,我们的目标是最小化不同数据分布下的经验风险:
$$\min\limits_ {f}\max\limits_ {e\in\mathcal{S}}\mathbb{E}_ {(\mathcal{G},Y)\sim p(\mathcal{G},Y|e)}:[\mathcal{L}\left(f\left(\mathcal{G}\right),Y\right)|e]$$
我的理解是类似于最小化$L^\infty$距离
Robust Lottery Searching (LoRS)

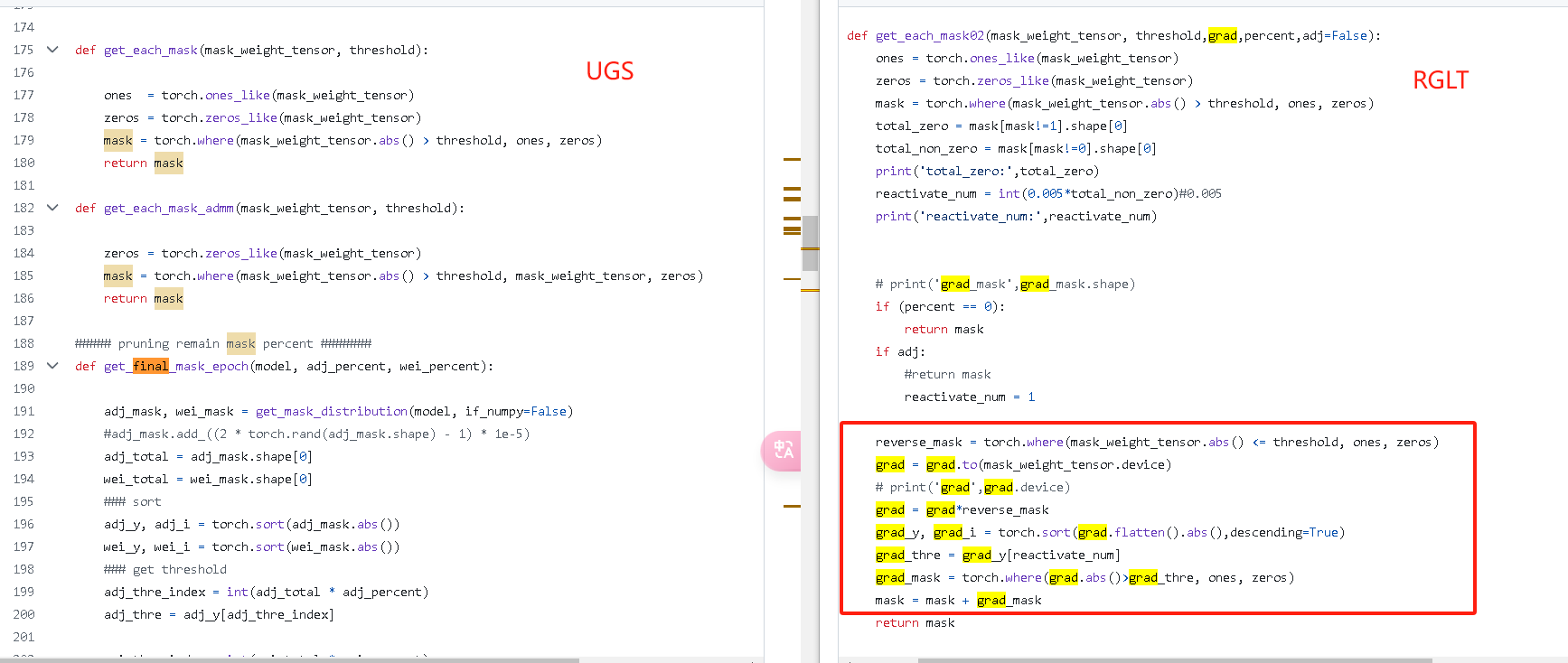
前面的步骤和UGS类似,多了一步,将丢弃的边中梯度最大的若干个恢复,代码如右图红框所示。
lottery Graph Intervention (LoGI)
代码
基于UGS的代码,有大量相同的地方。
和UGS一样,主函数也是包括
1 | |
run_fix_mask
1 | |
不断优化gcn,劣化gl
《Analyzing_Adversarial_Vulnerabilities_of_Graph_Lottery_Tickets(ICASSP2024).pdf》
和finding_adversarially_robust_graph lottery tickets原作者,内容基本一样。
除了少了平滑项。
实验
pass
《finding_adversarially_robust_graph lottery tickets(under review).pdf》
 被拒了。
被拒了。
AC拒稿理由:
本文提出了一种减少图彩票对图结构的对抗性扰动的脆弱性的技术。结果似乎对这个问题相当有效。审稿人提出了一些担忧,包括设置本身(结构扰动真的是正确的威胁模型吗?关注这一点是否依赖于其他方面不受攻击?)、方法本身的复杂性(超参数太多)以及大小正在研究的图表的数量(它们足够大吗?)。我同意第一个担忧:这真的是一个重要问题吗?如果对图彩票的对抗性攻击是一个重要问题,那么这些类型的攻击在实践中是否重要?我对接受持矛盾态度,并且基于所研究问题的重要性,我倾向于拒绝。对于这个特定问题来说,这似乎是一个合理的贡献,但问题本身却非常小众。
相关工作
pass
算法
总所周知,两层的GCN可以表示为
$$
Z=f({ A, X },\Theta)= \mathcal{S}(\hat{A} \sigma ( \hat A X W_ {(0)}) W_ {(1)})
$$
设计了一个transductive semi-supervised node classification (SSNC) loss:
$$
\mathcal{L} _ 0 (f({A, X}, \Theta))=-\sum _ {l \in \mathcal{Y} _ {TL}} \sum _ {j=1} ^C Y _ {l_j} log( Z _ {l_j})
$$
其中$\mathcal{Y}_ {TL}$是训练节点的索引,C是类总数,$Y_l$是$v_l$one hot 标签。
posion 攻击者的目标是找到一个最优的扰动A ‘,欺骗GNN做出错误的预测。这可以表述为一个双层优化问题(Zugner et al., 2018;zugner & gunnemann, 2019):
$$
\begin{align}
arg \max\mathcal{L}_ {atk}(f({A’,X},\Theta ^\ast))\\
A’\in\Phi(A)\\
\mathrm{s.t.}\quad\Theta^{\ast}=\arg\min_ {\Theta}\mathcal{L}_ {0}(f({A’,X},\Theta))
\end{align}
$$
其中$\Phi(A)$是满足$\frac{|A’-A|{0}}{|A|{0}}\leq\Delta$的领接矩阵。$\mathcal{L}_ {atk}$ 是攻击loss函数,$\Delta$ 是 perturbation rate,$\Theta ^\ast$是摄动图上GNN的最优参数。
为了帮助消除对抗边和鼓励特征平滑,对于homophilic graphs:
$$
\mathcal{L}_ {fs} (A’,X)=\frac{1}{2} \sum_ {i,j=1}A_ {ij}’ (x_i-x_j)^2
$$
对于heterophilic graphs:
$$
\mathcal{L}_ {fs}(A’)=\frac{1}{2}\sum_ {i,j=1}A_ {ij}’(y_ {i}-y_ {j})^{2}
$$
以上有点像dirichlet energy。
dirichlet energy:
$$
tr(x^\top Lx)=|\nabla_Gx|_2^2=\frac{1}{2}\sum _ {i,j}W[i,j] (x[j]-x[i])^2
$$
进一步归一化:
$$
tr(x^\top Lx)=|\nabla_Gx|_2^2=\frac{1}{2}\sum _ {i,j}W[i,j] (\frac{x[j]}{\sqrt{1+d_j}}-\frac{x[i]}{\sqrt{1+d_i}})^2
$$
(上式来自《Dirichlet Energy Constrained Learning for Deep Graph Neural Networks》)或
$$
tr(x^\top Lx)=|\nabla_Gx|_2^2=\frac{1}{4}\sum _ {i,j}W[i,j]|\frac{x[j]}{\sqrt{d_j}}-\frac{x[i]}{\sqrt{d_i}}|_2^2
$$
(上式来自《A Fractional Graph Laplacian Approach to Oversmoothing》)其中d为节点的度。
其中yi∈R P为输入图G上运行DeepWalk算法得到的节点i, j的位置特征,P为节点位置特征个数。
查看上面部分的代码,我们可以发现:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def feature_smoothing(self, adj, X):
adj = (adj.t() + adj)/2
rowsum = adj.sum(1)
r_inv = rowsum.flatten()
D = torch.diag(r_inv)
L = D - adj
r_inv = r_inv + 1e-3
r_inv = r_inv.pow(-1/2).flatten()
r_inv[torch.isinf(r_inv)] = 0.
r_mat_inv = torch.diag(r_inv)
L = r_mat_inv @ L @ r_mat_inv
XLXT = torch.matmul(torch.matmul(X.t(), L), X)
loss_smooth_feat = torch.trace(XLXT)
return loss_smooth_feat迹的计算又出现了。
另外,作者还训练了一个简单的两层MLP。mlp使用训练集做训练,然后对使用训练好的MLP来预测测试节点的标签。称这些标签为伪标签。最后,利用MLP预测置信度较高的测试节点计算测试节点CE损失项。
设$Y_ {P L}$为MLP预测置信度较高的测试节点集,$Y_ {mlp}$为MLP的预测值。CE损失为:
$$
\mathcal{L} _ 1(f({A’,X},\Theta))=-\sum_ {l\in\mathcal{Y}_ {TL}}\sum_ {j=1}^C Y_ {mlp_ {l_j}}\log(Z_ {l_j})
$$
最终loss为:
$$
\begin{align}
\mathcal{L}_ {ARGS}=\alpha\mathcal{L}_ {0}(f({m_ {g}\odot A’,X},m_ {\theta}\odot\Theta))+\beta\mathcal{L}_ {fs}(m_ {g}\odot A’,X)\\+\gamma\mathcal{L}_ {1}(f({m_ {g}\odot A’,X},m_ {\theta}\odot\Theta))+\lambda_ {1}||m_ {g}||_ {1}+\lambda_ {2}||m_ {\theta}||_ {1}
\end{align}
$$
其中,$\alpha$和$\gamma$设置为1。$m_g$用于领接矩阵,$m_ \theta$用于模型权重。
代码
完全基于UGS的代码,有大量相同的地方。
和UGS一样,主函数也是包括
1 | |
run_get_mask函数不同点:run_get_mask中加入了平滑项和伪标签的分类误差。
即loss为
$$
\begin{align}
\mathcal{L}_ {run_get_mask}=\alpha\mathcal{L}_ {0}(f({m_ {g}\odot A’,X},m_ {\theta}\odot\Theta))+\beta\mathcal{L}_ {fs}(m_ {g}\odot A’,X)\\
+\gamma\mathcal{L}_ {1}(f({m_ {g}\odot A’,X},m_ {\theta}\odot\Theta))+\lambda_ {1}||m_ {g}||_ {1}+\lambda_ {2}||m_ {\theta}||_ {1}
\end{align}
$$
run_fix_mask函数不同点:run_fix_mask中加入了伪标签的分类误差。
即loss为
$$
\mathcal{L}_ {run_fix_mask}=\alpha\mathcal{L}_ {0}(f({m_ {g}\odot A’,X},m_ {\theta}\odot\Theta))+\gamma\mathcal{L}_ {1}(f({m_ {g}\odot A’,X},m_ {\theta}\odot\Theta))
$$
实验
pass
《inductive lottery ticket learning for graph neural networks(under review).pdf》
Accepted by JCST 2023
Rejected by ICLR 2022
介绍
过往的有以下缺点
1)也就是说,边缘遮罩被限制在给定的图中,使得UGS在归纳设置中不可行,因为边缘遮罩很难推广到看不见的边或全新的图。
2)对每条边单独应用掩码只能提供对边缘的局部理解,而不是整个图的全局视图(例如,在节点分类中)或多个图(例如,在图分类中)
此外,创建可训练边缘掩模的方式会使gnn的参数加倍,这在某种程度上违背了修剪的目的。
因此,这些边缘掩模可能是次优的,以指导修剪。(3)不理想的图剪枝会对模型权值的剪枝产生负面影响。更糟糕的是,低质量的权值剪枝会反过来放大边缘掩模的误导信号。它们相互影响,形成恶性循环。我们将所有这些UGS的局限性归因于它的转导性质。因此,在归纳设置中进行组合修剪对于高质量中奖彩票至关重要。
算法
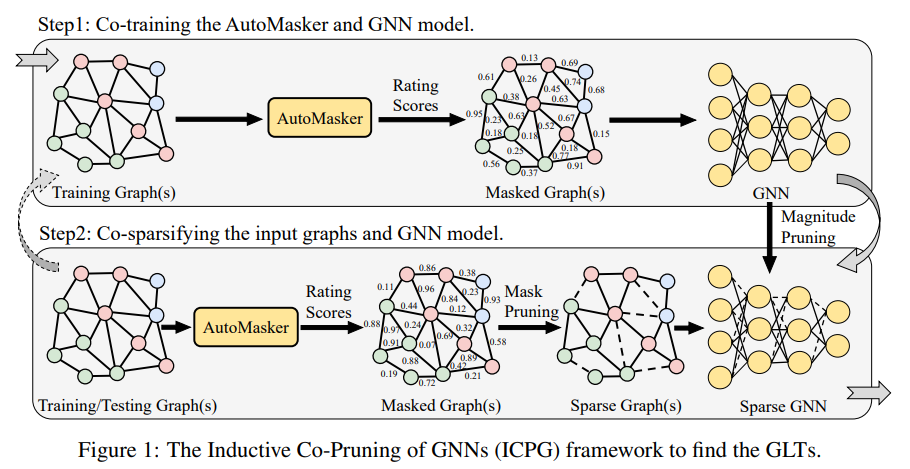
本文提出了一个AutoMasker,具体而言,他设计了一套网络用来生成mask的选择。
它使用一个GNN $g(·)$来获取每个节点的 representations。
$H=g(A,X)$
每一行代表着节点的representation。故可由计算节点的重要性,
$$
s_ {ij}=\sigma{(\alpha_ {ij})},a_ {ij} = MLP([h_i,h_j])
$$
对于图,我们采用AutoMasker来预测每个图的所有边的重要性。然后根据掩码值对某图的边进行排序,对最小值为5%的边进行剪接,得到二值图掩码mG。
对于GNN,我们根据权重量级对参数进行排序,并对最低量级的参数进行20%的修剪,得到二值模型掩码mΘ。在当前的稀疏度水平下,我们现在成功地得到了模型的稀疏化图g0 = (mG A, X)和稀疏化掩码mΘ。
最后,我们需要检查稀疏性是否满足我们的条件。如果满足稀疏性,则算法完成;如果没有,我们需要重用找到的GLT来更新原始图和GNN模型,并迭代使用步骤1和步骤2(图1中虚线箭头),直到满足条件。

代码
模型代码
GAT:
1 | |
Masker
1 | |
GAT和Masker相比,masker的隐藏层更小,多了inner_product_score(上文省略了)和concat_mlp_score的函数。GAT最后一层是分类器,Masker最后一层输出边的分数。
训练过程
1 | |
train_model_and_masker函数
1 | |
和UGS的过程其实差不多,权重=mask*权重,使用CEloss进行训练。UGS的mask为网络中的参数,而该算法的mask则由另一套神经网络生成。
pruning_model
本部分使用了pytorch 的torch.nn.utils.prune
1 | |
L1:基于权重绝对值
random:完全随机
grad_model
源代码为pruning.grad_model(masker, False),冻结梯度
1 | |